一,工具
电脑安卓模拟器:夜神模拟器
抓包工具:fiddler
代码:pycharm
二、分析
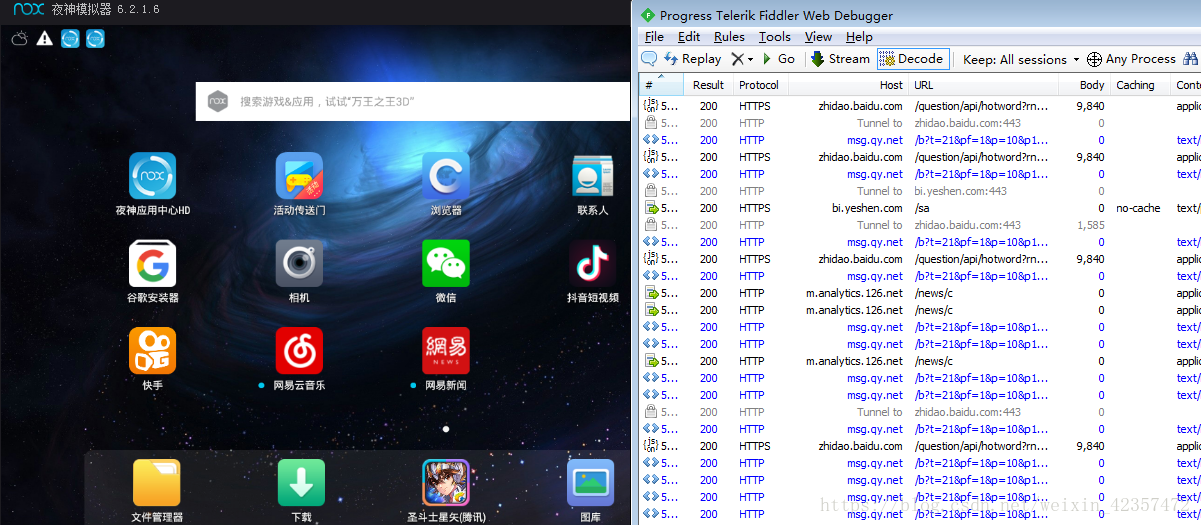
1.首先要设置好fiddler和夜神模拟器的关联,这个网上很多教程这里不做介绍
2.打开网易app,观察fiddler抓包列表,尽量先清空下然后刷新网易这样再次观察更清晰
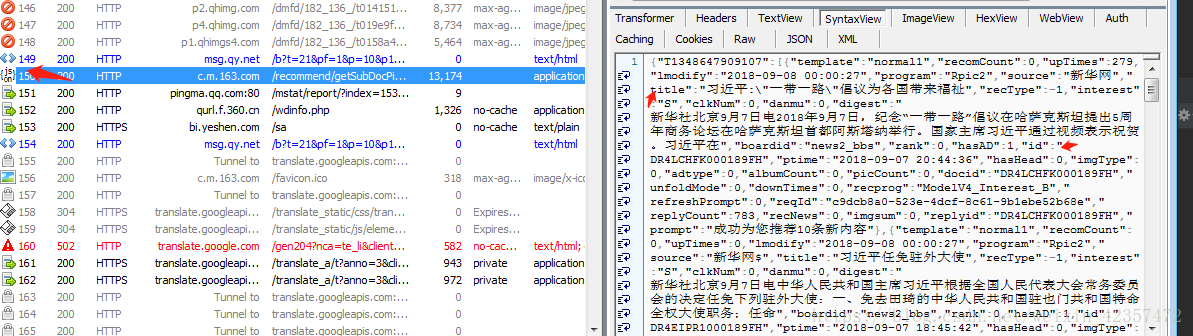
3.找到内容的包,当然这个需要多观察,看到一个json的api接口
4.分析json数据能看到内容的标题,来源,简介和新闻内容的跳转链接的id
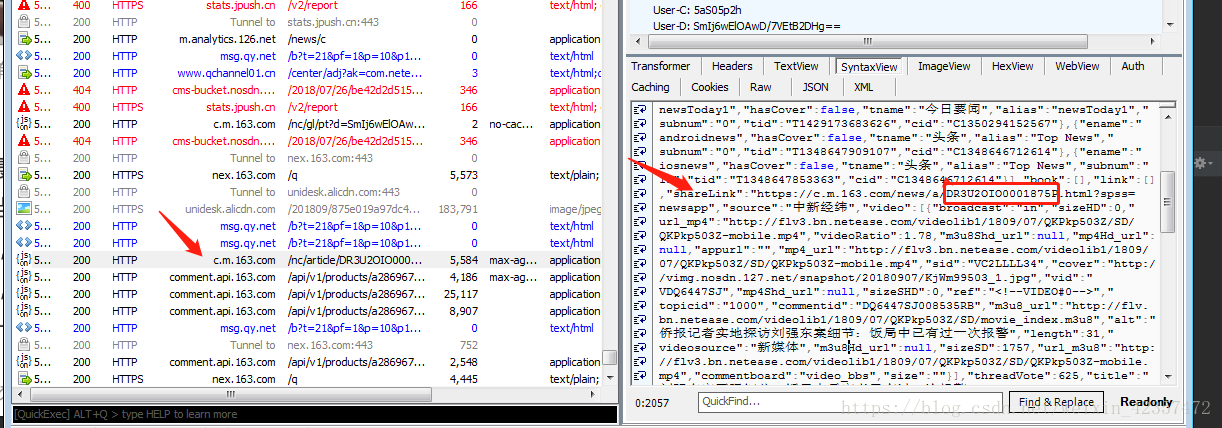
5.新闻内容链接还是通过抓包分析就是由具体格式加上id组成
三、代码
主要通过简单的请求和解析出想要的内容,requests请求,json转出dict,然后就是解析出想要的内容
#效果展示

import requests
import json
url="http://c.m.163.com/recommend/getSubDocPic?tid=T1348647909107&from=toutiao&offset=0&size=10&fn=2&LastStdTime=0&spestr=&prog=&passport=&devId=SmIj6wElOAwD%2F7VEtB2DHg%3D%3D&lat=d7C%2FuQEMvzpJvLOCtGz7eA%3D%3D&lon=jKhXi261wzrUpMyoUJMkXA%3D%3D&version=32.1&net=wifi&ts=1536372024&sign=GDXr1D%2FJSfyJMd2%2BUFw5n0BFw9x8%2FjCcuvItDDfX2gZ48ErR02zJ6%2FKXOnxX046I&encryption=1&canal=news_lf_cpa_2&mac=4CNyYK7%2FA82%2Bwmt5R%2FX%2FIDuov9agSmjNwKbeX%2FiMet8%3D&open=&openpath="
response=requests.get(url)
source_dit=json.loads(response.text)
# print(type(source))
content=source_dit["T1348647909107"]
for i in content:
title=i["title"]
source=i["source"]
digest=i["digest"]
link="https://c.m.163.com/news/a/{}.html?spss=newsapp".format(i["id"])
print(source,"\n",link ,"\n", title, "\n",digest,"\n" )
print("="*80)