一序
本文分为两个部分,第一部分主要基于何登成大神的文章。何博士作为阿里数据库内核团队大神。文章更是深入浅出。膜拜一下:原文地址如下 http://hedengcheng.com/?p=771
第二部分介绍常见的实践注意事项。
二 背景
MVCC:Snapshot Read vs Current Read
MySQL InnoDB存储引擎,实现的是基于多版本的并发控制协议——MVCC (Multi-Version Concurrency Control) 在MVCC并发控制中,读操作可以分成两类:快照读 (snapshot read)与当前读 (current read)。快照读,读取的是记录的可见版本 (有可能是历史版本),不用加锁。当前读,读取的是记录的最新版本,并且,当前读返回的记录,都会加上锁,保证其他事务不会再并发修改这条记录。
在一个支持MVCC并发控制的系统中,哪些读操作是快照读?哪些操作又是当前读呢?以MySQL InnoDB为例:
-
快照读:简单的select操作,属于快照读,不加锁。(当然,也有例外,下面会分析)
-
select * from table where ?;
-
-
当前读:特殊的读操作,插入/更新/删除操作,属于当前读,需要加锁。
-
select * from table where ? lock in share mode;
-
select * from table where ? for update;
-
insert into table values (…);
-
update table set ? where ?;
扫描二维码关注公众号,回复: 3444772 查看本文章
-
delete from table where ?;
所有以上的语句,都属于当前读,读取记录的最新版本。并且,读取之后,还需要保证其他并发事务不能修改当前记录,对读取记录加锁。其中,除了第一条语句,对读取记录加S锁 (共享锁)外,其他的操作,都加的是X锁 (排它锁)
-
其他相关知识点:
聚集索引(主键索引) 官网介绍、
2PL:Two-Phase Locking (锁操作分为两个阶段:加锁阶段与解锁阶段,并且保证加锁阶段与解锁阶段不相交)
隔离级别(官网介绍:https://dev.mysql.com/doc/refman/5.7/en/innodb-transaction-isolation-levels.html)
Read Uncommited,Read Committed,Repeatable Read,Serializable,不做重复介绍。
三 加锁分析case
SQL1:select * from t1 where id = 10;
SQL2:delete from t1 where id = 10;
需要分析不同的前提,下面是常见的:
-
组合一:id列是主键,RC隔离级别
-
组合二:id列是二级唯一索引,RC隔离级别
-
组合三:id列是二级非唯一索引,RC隔离级别
-
组合四:id列上没有索引,RC隔离级别
-
组合五:id列是主键,RR隔离级别
-
组合六:id列是二级唯一索引,RR隔离级别
-
组合七:id列是二级非唯一索引,RR隔离级别
-
组合八:id列上没有索引,RR隔离级别
-
组合九:Serializable隔离级别
在前面八种组合下,也就是RC,RR隔离级别下,SQL1:select操作均不加锁,采用的是快照读,因此在下面的讨论中就忽略了,主要讨论SQL2:delete操作的加锁。
3.1组合一:id主键+RC
这个组合,是最简单,最容易分析的组合。id是主键,Read Committed隔离级别,给定SQL:delete from t1 where id = 10; 只需要将主键上,id = 10的记录加上X锁即可。
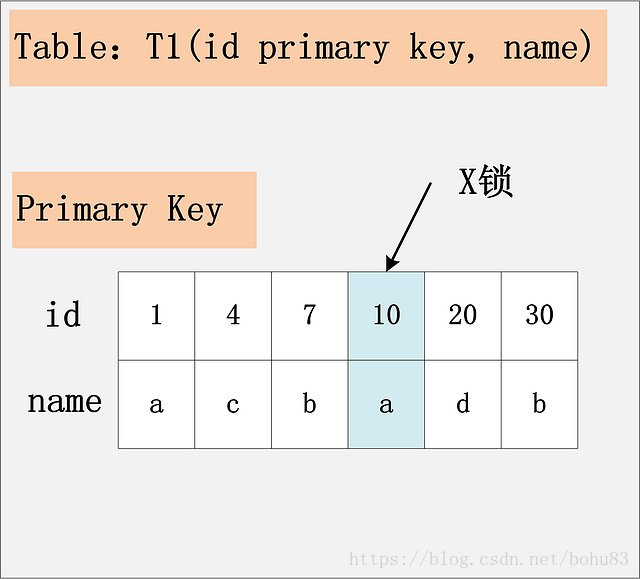
结论:id是主键时,此SQL只需要在id=10这条记录上加X锁即可。
3.2 组合二:id唯一索引+RC
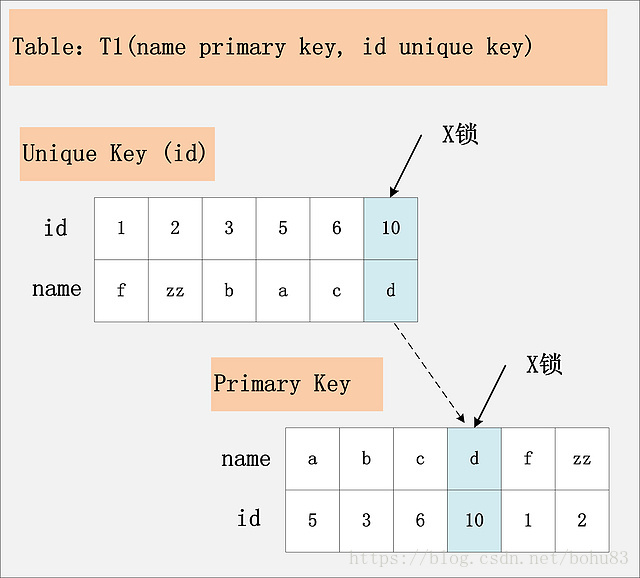
此组合中,id是unique索引,而主键是name列。此时,加锁的情况由于组合一有所不同。由于id是unique索引,因此delete语句会选择走id列的索引进行where条件的过滤,在找到id=10的记录后,首先会将unique索引上的id=10索引记录加上X锁,同时,会根据读取到的name列,回主键索引(聚簇索引),然后将聚簇索引上的name = ‘d’ 对应的主键索引项加X锁。为什么聚簇索引上的记录也要加锁?试想一下,如果并发的一个SQL,是通过主键索引来更新:update t1 set id = 100 where name = ‘d’; 此时,如果delete语句没有将主键索引上的记录加锁,那么并发的update就会感知不到delete语句的存在,违背了同一记录上的更新/删除需要串行执行的约束。
结论:若id列是unique列,其上有unique索引。那么SQL需要加两个X锁,一个对应于id unique索引上的id = 10的记录,另一把锁对应于聚簇索引上的[name=’d’,id=10]的记录。
3.3 组合三:id非唯一索引+RC
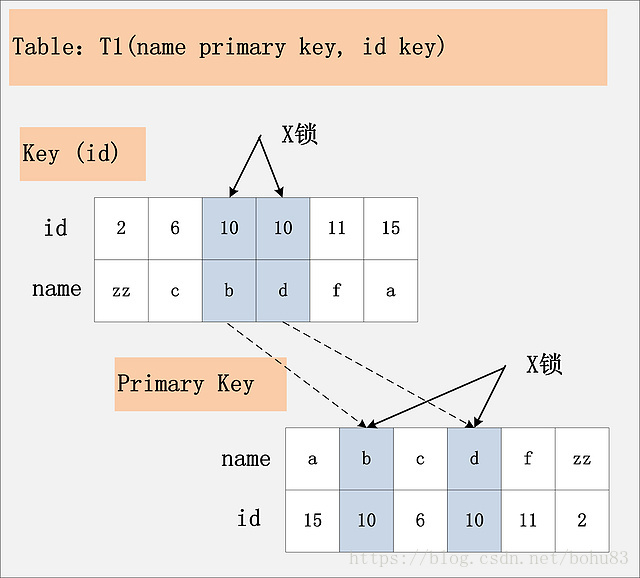
根据此图,可以看到,首先,id列索引上,满足id = 10查询条件的记录,均已加锁。同时,这些记录对应的主键索引上的记录也都加上了锁。与组合二唯一的区别在于,组合二最多只有一个满足等值查询的记录,而组合三会将所有满足查询条件的记录都加锁。
结论:若id列上有非唯一索引,那么对应的所有满足SQL查询条件的记录,都会被加锁。同时,这些记录在主键索引上的记录,也会被加锁。
3.4组合四:id无索引+RC
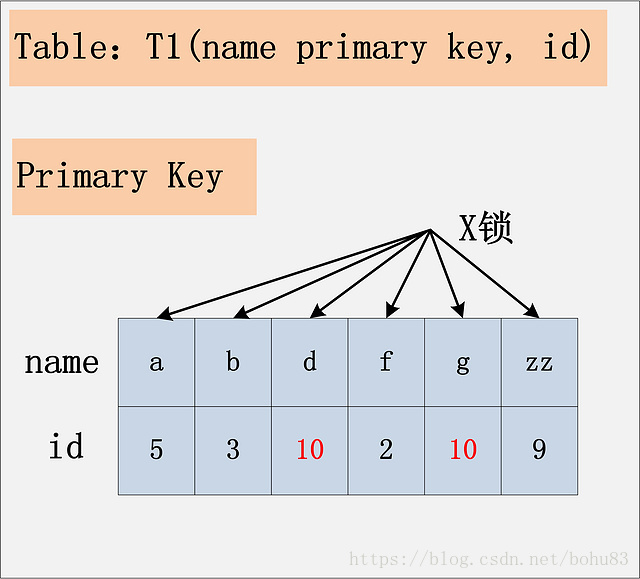
由于id列上没有索引,因此只能走聚簇索引,进行全部扫描。从图中可以看到,满足删除条件的记录有两条,但是,聚簇索引上所有的记录,都被加上了X锁。无论记录是否满足条件,全部被加上X锁。既不是加表锁,也不是在满足条件的记录上加行锁。
注:在实际的实现中,MySQL有一些改进,在MySQL Server过滤条件,发现不满足后,会调用unlock_row方法,把不满足条件的记录放锁 (违背了2PL的约束)。这样做,保证了最后只会持有满足条件记录上的锁,但是每条记录的加锁操作还是不能省略的。
结论:若id列上没有索引,SQL会走聚簇索引的全扫描进行过滤,由于过滤是由MySQL Server层面进行的。因此每条记录,无论是否满足条件,都会被加上X锁。但是,为了效率考量,MySQL做了优化,对于不满足条件的记录,会在判断后放锁,最终持有的,是满足条件的记录上的锁,但是不满足条件的记录上的加锁/放锁动作不会省略。同时,优化也违背了2PL的约束。
3.5 组合五:id主键+RR
上面的四个组合,都是在Read Committed隔离级别下的加锁行为,接下来的四个组合,是在Repeatable Read隔离级别下的加锁行为。
组合五,id列是主键列,Repeatable Read隔离级别,针对delete from t1 where id = 10; 这条SQL,加锁与组合一:(id是主键,Read Committed隔离级别) 一致。
结论:id是主键时,此SQL只需要在id=10这条记录上加X锁即可。
3.6 组合六:id唯一索引+RR
与组合二:[id唯一索引,Read Committed]一致。两个X锁,id唯一索引满足条件的记录上一个,对应的聚簇索引上的记录一个。
3.7 组合七:id非唯一索引+RR
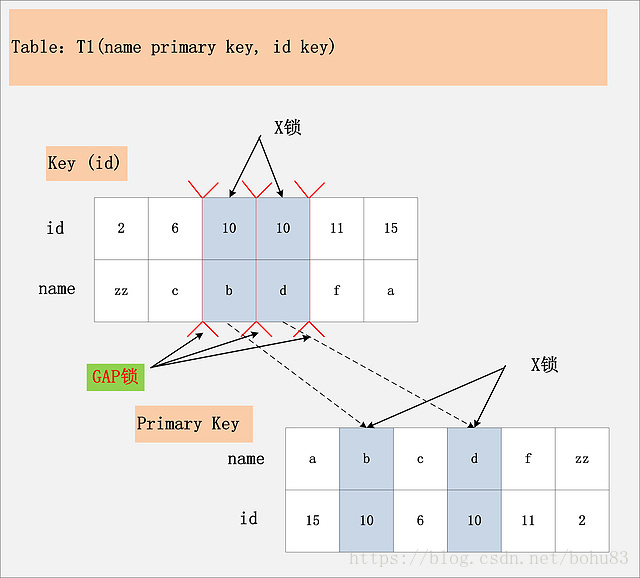
相对于组合三:[id列上非唯一锁,Read Committed]看似相同,其实却有很大的区别。最大的区别在于,这幅图中多了一个GAP锁。
其实这个多出来的GAP锁,就是RR隔离级别,相对于RC隔离级别,不会出现幻读的关键。确实,GAP锁锁住的位置,也不是记录本身,而是两条记录之间的GAP。所谓幻读,就是同一个事务,连续做两次当前读 (例如:select * from t1 where id = 10 for update;),那么这两次当前读返回的是完全相同的记录 (记录数量一致,记录本身也一致),第二次的当前读,不会比第一次返回更多的记录 (幻象)。如何保证两次当前读返回一致的记录,那就需要在第一次当前读与第二次当前读之间,其他的事务不会插入新的满足条件的记录并提交。为了实现这个功能,GAP锁应运而生。
如图中所示,有哪些位置可以插入新的满足条件的项 (id = 10),考虑到B+树索引的有序性,满足条件的项一定是连续存放的。记录[6,c]之前,不会插入id=10的记录;[6,c]与[10,b]间可以插入[10, aa];[10,b]与[10,d]间,可以插入新的[10,bb],[10,c]等;[10,d]与[11,f]间可以插入满足条件的[10,e],[10,z]等;而[11,f]之后也不会插入满足条件的记录。因此,为了保证[6,c]与[10,b]间,[10,b]与[10,d]间,[10,d]与[11,f]不会插入新的满足条件的记录,MySQL选择了用GAP锁,将这三个GAP给锁起来。
Insert操作,如insert [10,aa],首先会定位到[6,c]与[10,b]间,然后在插入前,会检查这个GAP是否已经被锁上,如果被锁上,则Insert不能插入记录。因此,通过第一遍的当前读,不仅将满足条件的记录锁上 (X锁),与组合三类似。同时还是增加3把GAP锁,将可能插入满足条件记录的3个GAP给锁上,保证后续的Insert不能插入新的id=10的记录,也就杜绝了同一事务的第二次当前读,出现幻象的情况。
既然防止幻读,需要靠GAP锁的保护,为什么组合五、组合六,也是RR隔离级别,却不需要加GAP锁呢?GAP锁的目的,是为了防止同一事务的两次当前读,出现幻读的情况。而组合五,id是主键;组合六,id是unique键,都能够保证唯一性。一个等值查询,最多只能返回一条记录,而且新的相同取值的记录,一定不会在新插入进来,因此也就避免了GAP锁的使用。
结论:Repeatable Read隔离级别下,id列上有一个非唯一索引,对应SQL:delete from t1 where id = 10; 首先,通过id索引定位到第一条满足查询条件的记录,加记录上的X锁,加GAP上的GAP锁,然后加主键聚簇索引上的记录X锁,然后返回;然后读取下一条,重复进行。直至进行到第一条不满足条件的记录[11,f],此时,不需要加记录X锁,但是仍旧需要加GAP锁,最后返回结束。
3.8 组合八:id无索引+RR
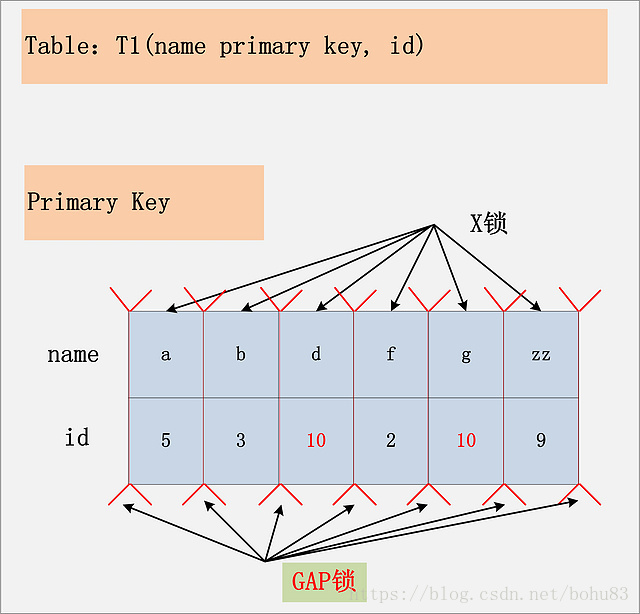
结论:在Repeatable Read隔离级别下,如果进行全表扫描的当前读,那么会锁上表中的所有记录,同时会锁上聚簇索引内的所有GAP,杜绝所有的并发 更新/删除/插入 操作。当然,也可以通过触发semi-consistent read,来缓解加锁开销与并发影响,但是semi-consistent read本身也会带来其他问题,不建议使用。
组合九:Serializable
Serializable隔离级别,影响的是SQL1:select * from t1 where id = 10; 这条SQL,在RC,RR隔离级别下,都是快照读,不加锁。但是在Serializable隔离级别,SQL1会加读锁,也就是说快照读不复存在,MVCC并发控制降级为Lock-Based CC。
结论:在MySQL/InnoDB中,所谓的读不加锁,并不适用于所有的情况,而是隔离级别相关的。Serializable隔离级别,读不加锁就不再成立,所有的读操作,都是当前读。
普通的并发插入导致的死锁
create table t1 (a int primary key); 开启三个会话执行: insert into t1(a) values (2);
| session 1 | session 2 | session 3 |
|---|---|---|
| BEGIN; INSERT.. | ||
| INSERT (block),为session1创建X锁,并等待S锁 | ||
| INSERT (block, 同上等待S锁) | ||
| ROLLBACK,释放锁 | ||
| 获得S锁 | 获得S锁 | |
| 申请插入意向X锁,等待session3 | ||
| 申请插入意向X锁,等待session2 |
上述描述了互相等待的场景,因为插入意向X锁和S锁是不相容的。这也是一种典型的锁升级导致的死锁。如果session1执行COMMIT的话,则另外两个线程都会因为duplicate key失败。
这里需要解释下为何要申请插入意向锁,因为ROLLBACK时原记录回滚时是被标记删除的。而我们尝试插入的记录和这个标记删除的记录是相邻的(键值相同),根据插入意向锁的规则,插入位置的下一条记录上如果存在与插入意向X锁冲突的锁时,则需要获取插入意向X锁。
又一个并发插入的死锁现象
两个会话参与。在RR隔离级别下
例表如下:
create table t1 (a int primary key ,b int);
insert into t1 values (1,2),(2,3),(3,4),(11,22);
| session 1 | session 2 |
|---|---|
| begin;select * from t1 where a = 5 for update;(获取记录(11,22)上的GAP X锁) | |
| begin;select * from t1 where a = 5 for update; (同上,GAP锁之间不冲突 | |
| insert into t1 values (4,5); (block,等待session1) | |
| insert into t1 values (4,5);(需要等待session2,死锁) |
引起这个死锁的原因是非插入意向的GAP X锁和插入意向X锁之间是冲突的。
四 数据库实践
4.1 设计阶段
表引擎选择使用innodb不适用myisam:
由于myisam引擎只支持table lock,在使用myisam引擎表过程中,当数据库中出现执行时间较长的查询后就会堵塞该表上的更新动作,所以经常会碰到线程会话处于表级锁等待(Waiting for table level lock)的情况.
表索引设计:避免索引死锁或者index merge。
4.2 开发阶段
因为已经使用了阿里云的RDS数据库,通常是dba监控慢SQL或者异常。
事务处理时间过长,导致并发出现锁等待。 并发事务处理在数据库中经常看到的应用场景,在这种场景下,需要避免大事务,长事务,复杂事务导致事务在数据库中的运行时间加长,事务时间变长则导致事务中锁的持有时间变长,影响整体的数据库吞吐量。
4.3 维护阶段
DDL操作被大查询block。 当应用上线进入维护阶段,则开始会有较多的数据库变更操作,比如:添加字段,添加索引等操作,这一类操作导致的锁故障也是非常频繁的.
尽量设计表保留拓展字段,保留json类型数据。这种字段没法做索引,也不要太长,只做必要的业务展示或者中转。
Metadata lock wait 的含义:为了在并发环境下维护表元数据的数据一致性,在表上有活动事务(显式或隐式)的时候,不可以对元数据进行写入操作。因此 MySQL 引入了 metadata lock ,来保护表的元数据信息。因此在对表进行上述操作时,如果表上有活动事务(未提交或回滚),请求写入的会话会等待在 Metadata lock wait。
导致 Metadata lock wait 等待的常见因素包括:活动事务,当前有对表的长时间查询,显示或者隐式开启事务后未提交或回滚,比如查询完成后未提交或者回滚,表上有失败的查询事务等。
总结:
设计开发阶段:
- 表设计要避免使用myisam存储引擎,改用innodb引擎;
- 为SQL创建合适的索引,避免多个单列索引执行出错;
- 避免大事务,长事务,复杂事务导致事务在数据库中的运行时间加长。
管理运维阶段:
- 在业务低峰期执行上述操作,比如创建删除索引;
- 在结构变更前,观察数据库中是否存在长时间运行的SQL,未提交的事务;
- 结构变更期间,监控数据库的线程状态是否存在lock wait。
参考: