10、AtomicInteger类。
AtomicInteger是一个提供原子操作的Integer类,通过线程安全的方式操作加减,十分适合高并发情况下的使用,AtomicInteger是在使用非阻塞算法实现并发控制。
11、Java常用集合。
Collection和Map,是集合框架的根接口。
Set:接口:实现类有HashSet和LinkedHashSet。Set的子接口SortedSet接口——>实现类:TreeSet。
List:接口:实现类有LinkedList、Vector、ArrayList。
Vector:可实现自动增长的对象数组,重量级、线程安全、使用少。
ArrayList:底层是Object数组,所以ArrayList具有数组的查询速度快的优点以及增删速度慢的缺点。
LinkedList:采用双向循环链表实现,方便增删,不利于查询。
HashSet通过equals和HashCode来判断两个元素是否相等,具体规则是:如果两个元素通过equals比较为true,并且两个元素的HashCode相等,则两个元素重复。
Map集合比较:
HashMap的存入顺序和输出顺序无关。
LinkedHashMap保留了键值对的存入顺序。
TreeMap则是对Map中的元素进行排序。
HashMap和HashTable的比较:
(a)、都是Java集合类,都可以用来存放Java对象。
(b)、HashTable 是Java1.1就有的,HashMap是Java1.2引进的Map接口的一个实现。
(c)、HashTable是同步的,这个类中的一些方法会保证HashTable中的对象是线程安全的;HashMap是异步的,HashMap中的对象不是线程安全的。
(d)、HashMap的key或value可放入空值(null)而HashTable不可以。
总结:
如果要求线程安全,使用Vector、HashTable。
如果不要求线程安全,使用ArrayList、LinkedList、HashMap。
如果要求键值对,则使用HashMap、HashTable。
如果数据量很大,又要求线程安全考虑Vector。
12、服务端的几种IO模型。
12.1.阻塞式模型。
指系统调用(一般是IO接口)不返回调用结果并让当前线程一直阻塞,只有当该系统调用获得结果或者超时出错才返回。
12.2.多线程的服务模型(异步IO)。
目的是让每个连接都有独立的线程(或进程),这样任何一个连接的阻塞都不会影响其他的连接。
12.3.非阻塞式模型。
非阻塞IO通过进程反复调用IO函数,与阻塞不同的是,调用IO函数后,内核会立刻返回一个错误的接口,该进程会不断去调用查询结果的函数recv(),直到收到正确的结果,在这个过程中进程是阻塞的。
12.4.IO复用模型。
关键来自select/epoll这个Function,对一个IO端口,两次调用,两次返回。好处在于单个process可以同时处理多个网络连接的IO。
12.5.信号驱动IO。
首先允许套接字进行信号驱动IO,并安装一个信号处理函数,进程继续运行并不阻塞。当数据准备好时,进程会收到一个SIGIO信号,可以在信号处理函数中调用IO操作函数处理数据。
13、NIO相关知识。
传统IO<=>BIO—>阻塞式IO
NIO—>非阻塞式IO
AIO—>异步IO
NIO关键点:
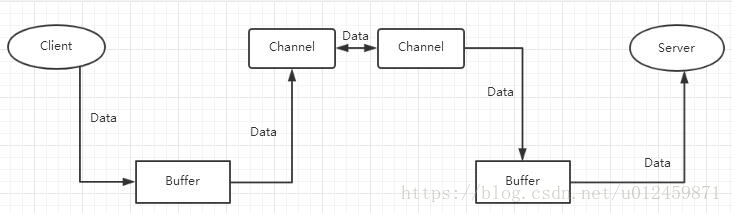
(a)、 缓冲区Buffer。
一个Buffer对象是固定数量的数据的容器。其作用是一个存储器,或者分段运输区,在这里数据可被存储并在之后用于检索。
(b)、通道Channel。
通道是一种途径,可以用最小的总开销来访问操作系统本身的IO服务。通道可以是单向的或者双向的。
(c)、选择器Selector。
用于分发不同的请求到不同的Channel,这样才能确保Channel不处于阻塞状态就可以收发消息。
(d)、图示。
14、SpringMVC工作原理解析。
14.1.SpringMVC处理流程。
(a)、用户发送请求至前端控制器DispatcherServlet。
(b)、DispatcherServlet收到请求调用handlerMapping处理器映射器。
(c)、处理器映射器找到具体的处理器(可以根据xml配置、注解进行查找)、生成处理器对象及处理器拦截器(如果有则生辰)一并返回给DispatcherServlet。
(d)、DispatcherServlet调用HandlerAdapter处理器适配器。
(e)、HandlerAdapter经过适配调用具体的处理器(Controller,也叫后端控制器)。
(f)、Controller执行完后返回ModeAndView。
(g)、HandlerAdapter将Controller执行结果ModelAndView返回DispatcherServlet。
(h)、DispatcherServlet将ModeAndView传给ViewResolver视图解析器。
(i)、ViewReslver解析返回具体的View。
(j)、DispatcherServlet根据View渲染视图并响应用户。
14.2.HandlerMapping简述。
项目启动时通过HandlerMap将Controller的url映射为一个Map,用户请求访问时,用当前url与map中的数据做比对,并返回对应的Handler。
14.3.HandlerAdapter简述。
SpringMVC通过HandlerAdapter来实际调用处理函数。
15、MyBatis的实现。
15.1.MyBatis的初始化。
MyBatis的初始化其实过程其实就是解析配置文件和初始化Configuration的过程。首先创建SQLSessionFactory创建者对象,然后由它进行创建SessionFactory,这里用到的是建造者模式,建造者模式最简单的理解就是不手动new对象,而是由其他类来进行对象的创建。然后由SQLSessionFactory来创建SqlSession对象。
15.2.MyBatis的SQL查询流程。
SQL查询参数设置:首先获取数据库connection连接,然后准备statement,然后设置SQL查询中的参数值。打开一个connection连接,在使用完后不会close,而是存储下来,当下次需要打开时直接返回。
SQL查询结果集的封装:ResultSetWrapper是ResultSet的封装类,调用getFirstResultSet方法获取第一个ResultSet,同时获取数据库的metaData数据,包括数据表列名、列的类型、类序号等,这些信息都存储在ResultSetWrapper类中了,然后调用HandleResultSet方法来进行结果集的封装。
15.3.MyBatis缓存。
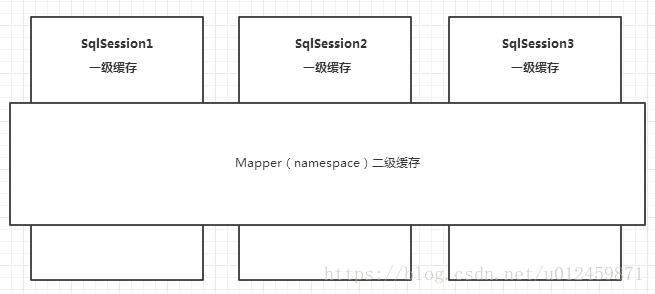
一级缓存是SqlSession级别的缓存,每个SqlSession对象都有一个哈希表用于缓存数据,不同SqlSession对象之间缓存不共享。同一个SqlSession对象执行两遍相同的Sql查询,在第一次查询完毕后会将查询结果缓存起来,第二遍查询直接返回结果即可,MyBatis默认是开启一级缓存的。
二级缓存是Mapper级别的缓存,二级缓存是跨SqlSession的,多个SqlSession对象可以共享同一个二级缓存。MyBatis默认是不开启二级缓存的,可以配置开启二级缓存(CacheEnabled)。
16、数据库索引类型。
(a)、普通索引。
(b)、唯一索引。
(c)、主键索引。
(d)、聚集索引。
该索引中键值的逻辑顺序决定表中相应的物理顺序。
(e)、非聚集索引。
该索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同。
17、MySQL三种数据引擎比较。
17.1.InnoDB。
支持事务处理,支持外键,支持崩溃修复能力和并发控制。如果对事务的完整性要求比较高(比如银行),要求实现并发控制(比如售票),那么选择InnoDB有很大的优势。如果需要频繁的更新、删除操作的数据库,也可以选择InnoDB,因为支持事务的提交(Commit)和回滚(RollBack)。
17.2.MyISAM。
插入数据快,空间和内存使用比较低。如果表主要用于插入新记录和读出记录。那么选择MyISAM能实现处理的高效率。如果应用的完整性、并发性要求比较低,也可以使用。
17.3.MEMORY。
所有的数据都在内存中,数据处理速度快,但是安全性不够高。如果需要很快的读写速度,对数据的安全性要求比较低,可以选择MEMORY。它对表的大小有要求,不能建立太大的表。所以,这类数据库只使用在相对较小的数据库表。
18、Redis相关知识。
18.1.使用场景。
(a)、配合关系型数据库做告诉缓存。
缓存高频次访问的数据,降低数据库IO。
分布式架构做Session共享。
(b)、可以持久化特定数据。
利用ZSet类型可以存储排行榜。
利用list的自然时间排序存储最新n个数据。
18.2.使用Redis的好处。
(a)速度快,因为数据存储在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1)。
(b)支持丰富的数据类型,支持String、list、set、sorted set(ZSet)、Hash。
(c)支持事务,操作都是原子性。所谓的原子性就是对数据的更改要么全部执行,要么全部不执行。
(d)丰富的特性:可用于缓存、消息队列、按key设置过期时间,过期后自动删除。
18.3.Redis缓存击穿问题处理。
缓存击穿表示恶意用户模拟请求很多缓存中不存在的数据,由于缓存中都没有,导致这些请求短时间内直接落在了数据库上,致使数据库异常。
(a)使用互斥锁排队。
根据key获取对应的value值为空时,锁上,从数据库中load数据后再释放锁(分布式环境需要使用分布式锁,单机环境的话使用Synchronized、Lock即可)。
(b)BloomFilter布隆过滤器。
类似于一个HashSet,用于判断某个元素是否存在于集合中。
18.4.Redis缓存雪崩问题处理。
缓存在同一时间内大量过期(失效),接着来的一大波请求瞬间落在数据库上导致连接异常。
(a)互斥锁排队(处理同上)。
(b)建立缓存备份。
缓存A和缓存B,B不设置超时时间,先从A读缓存,A没有则读B,并且更新A缓存和B缓存。