本篇博客作为复习深度学习时,查漏补缺所用。
目录
1. 在神经网络当中,x是 n行m列 ,m个样本,n表示特征向量 /* 列叠加 */
7. python中的广播 numpy和广播使我们可以用一行代码完成很多运算
8. assert(a.shape==(n,1))避免shape为(n,)的向量,reshape的使用
Part1. ng课程复习与思考
1. 在神经网络当中,x是 n行m列 ,m个样本,n表示特征向量 /* 列叠加 */
y=wt*x+b中的x是n行m列,脑子中不是想着下面的图1这种,而是矩阵np相乘
比如,本来x的shape是3*1,w是4*3,得到的z就是4*1,其中4代表4个隐藏层的单元数,1代表1个样本。
现在X是多个样本,是3*m,w还是4*3,得到的Z就是4*m,4代表隐藏层的单元数,m代表的是样本数。

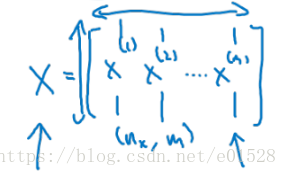
向量化运算,尽量避免用for语句,比如m个样本,不用for i in range(m) n个特征。

2. 为什么凸函数有利于梯度下降(优化)?
凸函数的性质:1.二阶可导 2.二阶导数>0 3.局部最优就是全局最优
梯度下降得到的结果可能是局部最优值。如果F(x)是凸函数,则可以保证梯度下降得到的是全局最优值。
下图为梯度下降的目的,找到J(θ)的最小值。
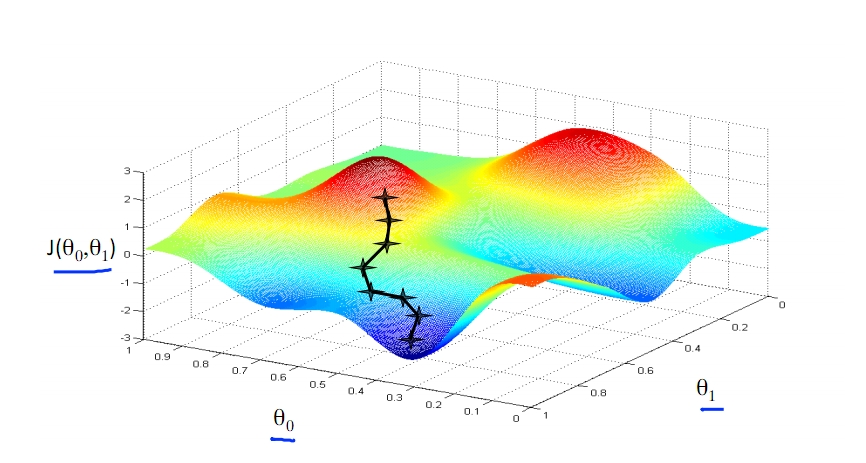
其实,J(θ)的真正图形是类似下面这样,其是一个凸函数,只有一个全局最优解,所以不必担心像上图一样找到局部最优解

3. 为什么 归一化后加快了梯度下降求最优解的速度?
如下图所示,蓝色的圈圈图代表的是两个特征的等高线。其中左图两个特征X1和X2的区间相差非常大,X1区间是[0,2000],X2区间是[1,5],其所形成的等高线非常尖。当使用梯度下降法寻求最优解时,很有可能走“之字型”路线(垂直等高线走),从而导致需要迭代很多次才能收敛;

4. 为什么 归一化有可能提高精度?
一些分类器需要计算样本之间的距离(如欧氏距离),例如KNN。如果一个特征值域范围非常大,那么距离计算就主要取决于这个特征,从而与实际情况相悖(比如这时实际情况是值域范围小的特征更重要)。
5. 梯度下降大局观
代价函数求导,更新 w=w−α∗J′(w),通过更改w b使得到达最近似值。
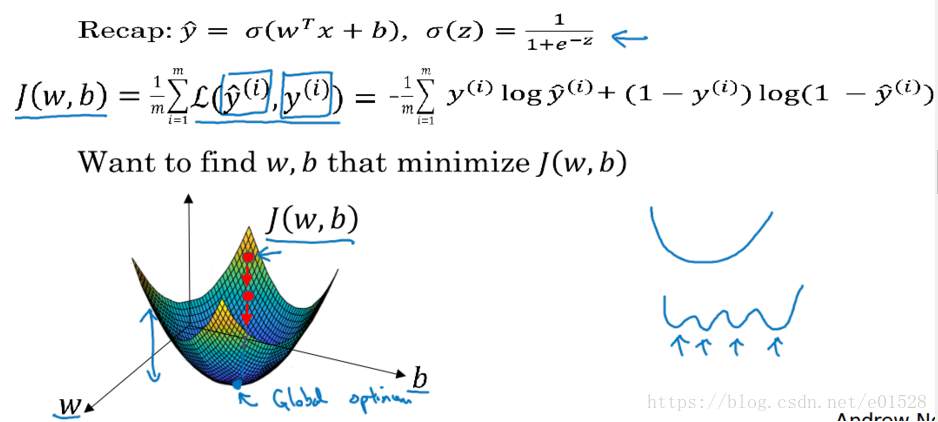
6. logistic代价函数的解释
https://www.cnblogs.com/liaohuiqiang/p/7659719.html 7.1部分 【最大似然的思想使已有的数据发生的概率最大化,相乘最大】
7. python中的广播 numpy和广播使我们可以用一行代码完成很多运算
加减乘除都是
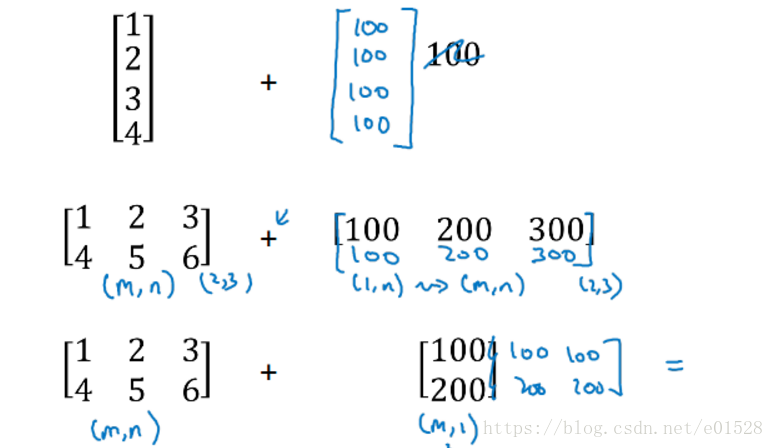
8. assert(a.shape==(n,1))避免shape为(n,)的向量,reshape的使用
比如a 的 shape是(5, ) ,当你计算np.dot(a,a.T)的时候得到的是一个实数,a和a的转置,它们的shape都是(5, )。
如果a 的 shape是(5, 1),你计算np.dot(a,a.T)的时候得到的就是一个5*5的矩阵。a的shape是( 5, 1),而a.T的shape是( 1, 5 )。
a.shape = (5, )这是一个秩为1的数组,不是行向量也不是列向量。很多学生出现难以调试的bug都来自秩为1数组。如果你得到了(5,) 你可以把它reshape成(5, 1)或(1, 5),reshape是很快的O(1)复杂度

9. 激活函数小对比
通常来说,很少会把各种激活函数串起来在一个网络中使用的。

| sigmoid | tanh | relu | leakly relu | |
| 优点 | 1. 输出层还是使用sigmoid,因 2. 为它输出[0,1]更符合概率分布 |
关于原点 中心对称 |
1. ReLU 对于 SGD 的收敛有加速作用,有人认为是由于它的线性、非饱和所致。 2. ReLU 只需要一个阈值就可以得到激活值,不用去算一大堆复杂的(指数)运算 |
为解决“ ReLU 死亡”问题的尝试。 |
| 缺点 | 1. 不关于原点中心对称 2. 梯度消失 |
梯度消失 | 1.relu的缺点是当z小于等于0时导数为0 2. 它在训练时比较脆弱并且可能“死掉”。 合理设置学习率,会降低这种情况的发生概率。实在不行尝试 Leaky ReLU、PReLU 或者 Maxout. |
1. 论文指出这个激活函数表现不错,但是其效果并不是很稳定。 2. Delving Deep into Rectifiers 中介绍了一种新方法PReLU,然而该激活函数在在不同任务中表现的效果也没有特别清晰。 |