本文翻译自Coding-Geek文章:《 How does a relational database work》。原文链接:http://coding-geek.com/how-databases-work/#Buffer-Replacement_strategies
本文翻译了如下章节, 介绍数据库查询优化器的实现表连接的一个简单实例:
简单实例–Simplified example
我们已经看到了3种连接操作算法。现在我们来看一下如何连接包含个人完整信息的5张表的数据。一个人可能有如下信息:
- 多个手机号。
- 多个电子邮箱。
- 多个住址。
- 多个银行账户。
换句话说,我们需要快速回答下面这个查询语句(如何做连接):
SELECT * from PERSON, MOBILES, MAILS,ADRESSES, BANK_ACCOUNTS
WHERE
PERSON.PERSON_ID = MOBILES.PERSON_ID
AND PERSON.PERSON_ID = MAILS.PERSON_ID
AND PERSON.PERSON_ID = ADRESSES.PERSON_ID
AND PERSON.PERSON_ID = BANK_ACCOUNTS.PERSON_ID作为查询优化器,我们必须找到处理这些数据最合适的方式。现在有两个问题:
1. 我应该为每个连接条件选择哪种连接方式?我已有有3种可用的连接算法(Hash Join, Merge Join, Nested Join),可使用0,1,2个索引(不考虑不同索引类型存在的差异)。
.
2. 我应该按怎样的顺序去执行多个连接操作?
例如,下图展示了各种可能的联表处理方式(涉及4张表的3次Join过程)。
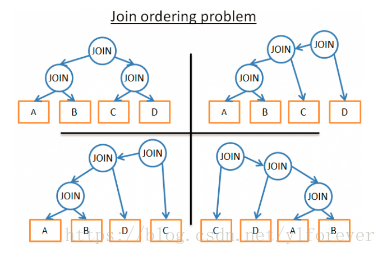
下面是我提供的一种可行方案:
1. 我使用的是一种简单粗暴的逼近最优的计算策略(译者注:使用穷举法)。
.
使用数据库的统计数据,我计算出所有可行的联表方案的成本,保留成本最优的一个。但是,可能的方案也许非常多,对于已经指定顺序的连接操作,每条连接都有3种可选的方案:HashJoin,Merge Join, Nested Loop Join。对于给定顺序的连接操作,前面的4张表就有3的4次方种连接方案。
.
联表顺序组合数是一个排序组合,在二叉树上4张表有(2*4)!/(4+1)!种联表顺序组合。
为简化问题,我认为总共有34*(2*4)!/(4+1)!种联表处理方案。
.
不考虑极端情况,这也意味着有27 216种可能的处理方案。如果我考虑增加0,1,或者2个B+树的索引,可能的处理方案就变成了210 000种。而且这还是一个非常简单的查询语句。
.
2. 现在,我已经感到沮丧,不想继续往下干了。
到此为打住看起来很好,但是你无法获取你想知道的知识。而我也需要钱来支付账单(译者注:为了钱,难搞的事情也要搞下去。作者写这边文章有稿费?)。
我仅尝试几种方案,从中找出一个成本最低的方案。
因为我不是超人,不无法计算每种方式的成本。我随机选择所有方案的一个子集,计算子集中方案的成本,找出最优的。
我通过几条规则来减少可能联表方案的数量。有两条规则:
我能使用逻辑规则,这些规则能去掉无用的选择条件,但不会过滤掉很多可行的方案。例如:循环嵌套连接的内连接对象集必须是最小的那个数据集。
.
我接受找不到最优解的风险,通过一些激进的规则大量减少选择条件。例如:如果一个对象集数据量很小,使用循环嵌套连接而不使用归并连接。
在这个简单的例子中,我找到这些可行条件结束。但是一个真实的查询器还支持其它的关系连接操作,例如OUTER JOIN, CROSS JOIN, GROUP BY, ORDER BY, PROJECTION, UNION, INTERSECT, DISTINCT…。这意味着有更多可能的操作。
那么,一个真实的数据库是如何处理它们的呢?下一章节解释。