本文参考自宋宝华老师的《linux驱动开发详解》
并发(Concurrency) 指的是多个执行单元同时、 并行被执行, 而并发的执行单元对共享资源(硬件资源和软件上的全局变量、 静态变量等) 的访问则很容易导致竞态(Race Conditions)
只要并发的多个执行单元存在对共享资源的访问, 竞态就可能发生。
1.对称多处理器(SMP) 的多个CPU
SMP是一种紧耦合、 共享存储的系统模型,, 它的特点是多个CPU使用共同的系统总线, 因此可访问共同的外设和储存器。
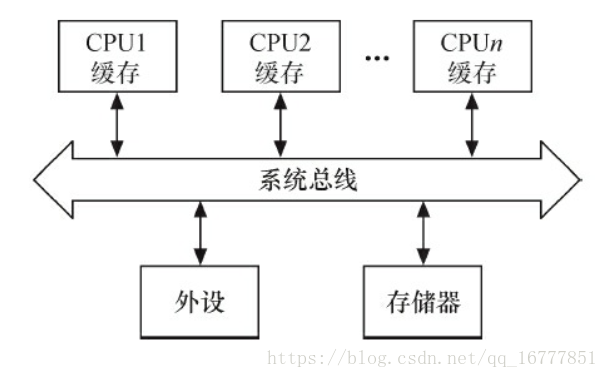
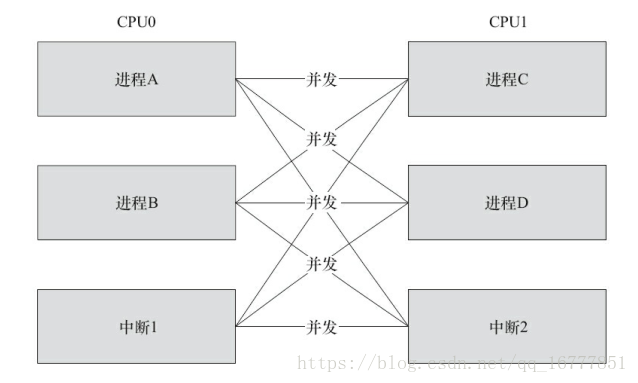
在SMP的情况下, 两个核(CPU0和CPU1) 的竞态可能发生于CPU0的进程与CPU1的进程之间、CPU0的进程与CPU1的中断之间以及CPU0的中断与CPU1的中断之间, 下图中任何一条线连接的两个实体都有核间并发可能性。
2.单个CPU进程内核和抢占它的进程
Linux 2.6以后的内核支持内核抢占调度, 一个进程在内核执行的时候可能耗完了自己的时间片(timeslice) , 也可能被另一个高优先级进程打断, 进程与抢占它的进程访问共享资源的情况类似于SMP的多个CPU。
3.中断(硬中断、 软中断、 Tasklet、 底半部) 与进程之间
中断可以打断正在执行的进程, 如果中断服务程序访问进程正在访问的资源, 则竞态也会发生。此外, 中断也有可能被新的更高优先级的中断打断, 因此, 多个中断之间本身也可能引起并发而导致竞态。 但是Linux 2.6.35之后, 就取消了中断的嵌套。 老版本的内核可以在申请中断时, 设置标记IRQF_DISABLED以避免中断嵌套, 由于新内核直接就默认不嵌套中断, 这个标记反而变得无用了。
上述并发的发生除了SMP是真正的并行以外, 其他的都是单核上的“宏观并行, 微观串行”, 但其引发的实质问题和SMP相似。
解决竞态问题的途径是保证对共享资源的互斥访问, 所谓互斥访问是指一个执行单元在访问共享资源的时候, 其他的执行单元被禁止访问。访问共享资源的代码区域称为临界区(Critical Sections) , 临界区需要被以某种互斥机制加以保护。
中断屏蔽、 原子操作、 自旋锁、 信号量、 互斥体等是Linux设备驱动中可采用的互斥途径。
7.2 编译乱序和执行乱序
理解Linux内核的锁机制, 还需要理解编译器和处理器的特点。 比如下面一段代码, 写端申请一个新的struct foo结构体并初始化其中的a、 b、 c, 之后把结构体地址赋值给全局gp指针。
struct foo {
int a;
int b;
int c;
};
struct foo *gp = NULL;
/* . . . */
p = kmalloc(sizeof(*p), GFP_KERNEL);
p->a = 1;
p->b = 2;
p->c = 3;
gp = p;而读端如果简单做下处理,则程序的运行可能是不符合预期的。
p = gp;
if(NULL != p)
{
do_something(p->a, p->b, p->c);
}
有两种可能的原因会造成程序出错,一种可能性是编译乱序,另 一种可能性是执行乱序。
关于编译方面,C语言顺序“p->a = 1; p->b = 2; p->c = 3; gp = p;”的编译结果的指令顺序可能是gp的赋值指令发生在a,b,c的赋值之前。现代的高性能编译器在目标码优化上都具备对指令进行乱序优化的能力。编译器可以对访存的指令进行乱序,减少逻辑上不必要的访问,以尽量提高cache命中率和CPU的load/store单元的工作效率。因此在打开编译器优化以后,看到生成的汇编码并没有严格按照代码的逻辑顺序,这是正常的。
解决编译乱序问题,需要通过barrier()编译屏障进行。我们可以在代码中设置barrier()屏障,这个屏障可以阻挡编译器的优化。对于编译器来说,这个编译屏障可以保证屏障前的语句和屏障后的语句不乱“串门”。
比如下面一段代码在e=d[4095],于b = a、c = a之间没有编译屏障
int main(int argc,char *argv[])
{
int a = 0, b, c, d[4096], e;
e = d[4095];
b = a;
c = a;
printf("a:%d b:%d c:%d e:%d\n",a, b, c, c, e);
return 0;
}使用下面命令编译
arm-none-linux-gnueabi-gcc -O2 barrier.c -o barrier使用下面命令反汇编后,重定位到.dis文件中
arm-none-linux-gnueabi-objdump -D barrier > barrier.dis反汇编的结果是(thumb 2)
int main(int argc,char *argv[])
{
831c: b530 push {r4, r5, lr}
831e: f5ad 4d80 sub.w sp, sp, #16384 ; 0x4000 4096*4个字节
8322: b083 sub sp, #12 ; b c e共12个字节
8324: 2100 movs r1, #0
8326: f50d 4580 add.w r5, sp, #16384 ; 0x4000
832a: f248 4018 movw r0, #33816 ; 0x8418
832e: 3504 adds r5, #4
8330: 460a mov r2, r1 ;-> b= a;
8332: 460b mov r3, r1 ;-> c= a;
8334: f2c0 0000 movt r0, #0
8338: 682c ldr r4, [r5, #0]
833a: 9400 str r4, [sp, #0] ;-> e = d[4095];
833c: f7ff efd4 blx 82e8 <_init+0x20>
}显然,尽管源代码级别b = a,c = a发生在c = d[4095]之后,但是目标代码的b = a,c = a指令发生在c = d[4095]之前。
我们重新编写代码,在c = d[4095],与b = a,c = a之间加上编译屏障:
#define barrier() __asm__ volatole ("": : :"memory")
int main(int argc,char *argv[])
{
int a = 0, b, c, d[4096], e;
e = d[4095];
barrier();
b = a;
c = a;
printf("a:%d b:%d c:%d e:%d\n",a, b, c, c, e);
return 0;
}再次使用
arm-none-linux-gnueabi-gcc -O2 barrier.c -o barrier优化编译,反汇编的结果是:
int main(int argc,char *argv[])
{
831c: b510 push {r4, lr}
831e: f5ad 4d80 sub.w sp, sp, #16384 ; 0x4000
8322: b082 sub sp, #8
8324: f50d 4380 add.w r3, sp, #16384 ; 0x4000
8328: 3304 adds r3, #4
832a: 681c ldr r4, [r3, #0]
832c: 2100 movs r1, #0
832e: f248 4018 movw r0, #33816 ; 0x8418
8332: f2c0 0000 movt r0, #0
8336: 9400 str r4, [sp, #0] ;-> e = d[4095];
8338: 460a mov r2, r1 ;-> b= a;
833a: 460b mov r3, r1 ;-> c= a;
833c: f7ff efd4 blx 82e8 <_init+0x20>
}因为__asm__ vloatile ("" : : :"memory")这个编译屏障的存在,原来的3条指令的顺序 拨乱反正 了。
关于解决编译乱序的问题,C语言的volatile关键字的作用较弱,它更多的知识避免内存访问行为的合并,对C语言编译器而言,volatile是暗示除了当前的执行线索之外,其它的执行线索可可能改变某内存,所以他的含义是“异变的”。换句话说,就是如果线程A读取var这个内存中的变量两次而没有修改var,编译器可能觉得读一次就行了,第二次直接取第一次的结果(在寄存器中)。但如果加了volatile关键字来形容var,则就是告诉编译器线程B,线程C或者其他执行实体也可能把var改掉了,因此编译器就不会把线程A代码的第2次内存读取优化掉了。另外,volatile也不具备保护临界资源的作用。总之,linux内核明显不太喜欢volatile,这个可以看考源码目录下的文档Documentation/volatile-considered-harmful.txt
乱序编译时编译器的行为,而执行乱序则是处理器运行时的行为。指向乱序是指变异的二进制指令的顺序按照“p ->a = 1; p- > = 2; p->c = 3; gp = p;”排放,在处理器上执行时,后放置的指令话是可能先执行完,这是处理器的“乱序执行”策略。高级点的CPU可以根据自己缓存的组织特性,将访存指令重新排序执行。连续地址的访问可能会先执行,因为这样花村命中率高。有的还允许访存的非阻塞,即如果前面一条访问指令因为缓存不命中,造成长延时的存储访问时,后面的访存指令可以先执行,一遍从缓存重取数。因此,即便是从汇编上看顺序正确的指令,其回想的顺序也是不可预知的。
举例,ARM v6/v7的处理器会对一下指令顺序进行优化。
ldr r0, [r1]
str r2, [r3]假设第一条ldr指令导致缓存未命中,这样缓存就会填充行,并需要较多的时钟周期才能完成。老的ARM处理器,比如ARM926EJ-S会等待这个动作完成,再指行下一条str指令。而ARM v6/v7处理器会识别下一条指令(str),且不需要等待第一条指令(ldr)完成(并不依赖r0的值),即会先执行str指令,而不是等待ldr指令完成。
对于大多数体系结构而言,尽管每个cpu都是乱序执行,但是这一乱序对于单核的程序是不可见的,因为单个CPU在碰到依赖点(后面的指令依赖前面的指令额执行结果)的时候会等待,所以程序员可能感觉不到这个乱序过程。但是这个依赖点等待的过程,在SMP处理器里面对于其他核是不可见的。比如若是在CPU0上执行:
while(f == 0);
print xCPU1上执行
x = 42;
f = 1;我们不能武断地认为CPU0上打印的x一定小于等于42,因为CPU1上即使 “f = 1”编译在“先= 42”后面,执行时仍然可能先于“x = 42”完成,所以这个时候CPU0上打印的x不一定就是42。
处理器为了解决多核间一个核的内存行为对另一个核可见的问题,引入了一些内存屏障的指令。譬如,ARM处理器的屏障指令包括:
dmb(数据内存屏障):在dmb之后的显示内存访问执行之前,保证所有在dmb指令之前的内存访问完成;
dsb(数据同步指令):等待所有在dsb指令之前的指令完成(位于此指令前的所有显示内存访问均完成,位于此指令前的所有缓存,跳转预测和TLB维护操作全部完成);
isb(指令同步屏障):flush流水线,是的所有isb之后的指令都是从缓存或内存中获得的。
linux的内核自旋锁、互斥体等互斥逻辑,需要用到上述指令;在请求获得锁时,调用屏障指令;在解锁时,也需要调用屏障指令。
下面代码清单用汇编代码描述了一个简单的互斥逻辑,留意其中的14和22行。
LOCKED EQU 1
UNLOCKED EQU 0
lock_mutex
; 互斥量是否锁定?
LDREX r1, [r0] ; 检查是否锁定
CMP r1, #LOCKED ; 和"locked"比较
WFEEQ ; 互斥量已经锁定, 进入休眠
BEQ lock_mutex ; 被唤醒, 重新检查互斥量是否锁定
; 尝试锁定互斥量
MOV r1, #LOCKED
STREX r2, r1, [r0] ; 尝试锁定
CMP r2, #0x0 ; 检查STR指令是否完成
BNE lock_mutex ; 如果失败, 重试
DMB ; 进入被保护的资源前需要隔离, 保证互斥量已经被更新
BX lr
unlock_mutex
DMB ; 保证资源的访问已经结束
MOV r1, #UNLOCKED ; 向锁定域写"unlocked"
STR r1, [r0]
DSB ; 保证在CPU唤醒前完成互斥量状态更新
SEV ; 像其他CPU发送事件, 唤醒任何等待事件的CPU
BX lr前面提到每个CPU都是乱序执行,但是每个CPU在碰到依赖点的时候会等待,所以执行乱序对单核不一定可见。但是在访问外设的寄存器时,这些寄存器的访问顺序在CPU的逻辑上构不成依赖关系,但是从外设的逻辑上将,可能需要固定的寄存器读写顺序,这个时候,也需要使用CPU的内存屏障指令。内核文章\Documentatio\nmemory-barriers.txt \Documentatio\io_ordering.txt
对此进程了描述。
在linux内核中,定义了 mb()、读屏障rmb()、写屏障wmb()、以及作用于寄存器读写的__ioemb()、__iowmb()这样的API。读写寄存器的readl_relaxed()和readl()、write_relaxed()和writel()API的区别就体现在有无屏障方面。

比如我们通过write_relaxed()写完DMA的开始地址、结束地址、大小之后,我们一定要调用writel来启动DMA(以保障前面的写成功)。
writel_relaxed(DMA_SRC_REG, src_addr);
writel_relaxed(DMA_DST_REG, dst_addr);
writel_relaxed(DMA_SIZE_REG, size);
writel (DMA_ENABLE, 1);
#if __LINUX_ARM_ARCH__ >= 7 || \
(__LINUX_ARM_ARCH__ == 6 && defined(CONFIG_CPU_32v6K))
#define sev() __asm__ __volatile__ ("sev" : : : "memory")
#define wfe() __asm__ __volatile__ ("wfe" : : : "memory")
#define wfi() __asm__ __volatile__ ("wfi" : : : "memory")
#endif
#if __LINUX_ARM_ARCH__ >= 7
#define isb(option) __asm__ __volatile__ ("isb " #option : : : "memory")
#define dsb(option) __asm__ __volatile__ ("dsb " #option : : : "memory")
#define dmb(option) __asm__ __volatile__ ("dmb " #option : : : "memory")
#elif defined(CONFIG_CPU_XSC3) || __LINUX_ARM_ARCH__ == 6
#define isb(x) __asm__ __volatile__ ("mcr p15, 0, %0, c7, c5, 4" \
: : "r" (0) : "memory")
#define dsb(x) __asm__ __volatile__ ("mcr p15, 0, %0, c7, c10, 4" \
: : "r" (0) : "memory")
#define dmb(x) __asm__ __volatile__ ("mcr p15, 0, %0, c7, c10, 5" \
: : "r" (0) : "memory")
#elif defined(CONFIG_CPU_FA526)
#define isb(x) __asm__ __volatile__ ("mcr p15, 0, %0, c7, c5, 4" \
: : "r" (0) : "memory")
#define dsb(x) __asm__ __volatile__ ("mcr p15, 0, %0, c7, c10, 4" \
: : "r" (0) : "memory")
#define dmb(x) __asm__ __volatile__ ("" : : : "memory")
#else
#define isb(x) __asm__ __volatile__ ("" : : : "memory")
#define dsb(x) __asm__ __volatile__ ("mcr p15, 0, %0, c7, c10, 4" \
: : "r" (0) : "memory")
#define dmb(x) __asm__ __volatile__ ("" : : : "memory")
#endif
3.中断屏蔽
在单CPU范围内避免竞态的一种简单而有效的方法是在进入临界区之前屏蔽系统的中断,但是在驱动编程中不值得推荐,驱动通常需要考虑跨平台特点而不假定自己在单核上运行。CPU一般都具备屏蔽中断和打开中断的功能,这项功能可以保证正在执行的内核执行路径不被中断处理程序所抢占,防止某些竞态条件的发生。具体而言,中断屏蔽将使得中断与进程之间的并发不再发生,而且,由于linux内核的进程调度等操作都是依赖中断实现,内核抢占进程之间的并发也得以避免了。
中断屏蔽的使用方法为:
local_irq_disable(); /* 屏蔽中断 */
...
/* 临界区 */
...
local_irq_enable(); /* 开中断 */其底层的实现原理是让CPU本身不响应中断,比如,对于ARM处理器而言,其底层的实现是屏蔽ARM CPSR的I位:
static inline void arch_local_irq_enable(void)
{
asm volatile(
" cpsie i @ arch_local_irq_enable"
:
:
: "memory", "cc");
}
static inline void arch_local_irq_disable(void)
{
asm volatile(
" cpsid i @ arch_local_irq_disable"
:
:
: "memory", "cc");
}
由于linux的异步I/O,进程调度等多个重要操作都依赖于中断,中断对比内核的的运行非常重要,在屏蔽中断期间,所有的中断都无法得到处理,因此长时间屏蔽中断是很危险的,这有可能会造成数据丢失乃至系统崩溃等后果。这就要求在屏蔽了中断之后,当前的内核执行路径应当尽快的执行完境界区的代码。
local_irq_disable()和local_irq_enable()都只能禁止和使能本CPU内的中断,因此,并不能解决SMP多CPU引发的竞态。因此,单独使用中断屏蔽通常不是一种值得推荐的避免竞态的方法(换句话说,驱动中使用local_irq_disable/local_irq_enable通常意味着一个bug),它适合于下文将要介绍的自旋锁联合使用。
local_irq_disable()不同的是,loacl_irq_save(flags)处了经行禁止中断的操作以外,还保存目前CPU的中断位信息,local_irq_restore(flags)进行的是与local_irq_save(flags)相反的操作。对于arm处理器而言,其实就是保存和恢复CPSR。
如果只是想禁止中断的底半 部,应该使用local_bh_disable(),使能用loacl_bh_disable()禁止的底半部应该使用local_bh_enable()。
4. 原子操作
原子操作可以保证对一个整型数据的修改是排他性的。linux内核提供了一系列函数来实现内核中的原子操作,这些函数分为两类,分别针对位和整型变量进行原子操作。位和整型变量的原子操作都依赖于底层CPU的原子操作,因此所有这些函数都与CPU架构密切相关。对于ARM处理器而言,底层使用ldrex和strex指令,比如atomic_inc()底层的实现会调用掉atomic_add(),其代码如下:
/*
* ARMv6 UP and SMP safe atomic ops. We use load exclusive and
* store exclusive to ensure that these are atomic. We may loop
* to ensure that the update happens.
*/
static inline void atomic_add(int i, atomic_t *v)
{
unsigned long tmp;
int result;
prefetchw(&v->counter);
__asm__ __volatile__("@ atomic_add\n"
"1: ldrex %0, [%3]\n"
" add %0, %0, %4\n"
" strex %1, %0, [%3]\n"
" teq %1, #0\n"
" bne 1b"
: "=&r" (result), "=&r" (tmp), "+Qo" (v->counter)
: "r" (&v->counter), "Ir" (i)
: "cc");
}
ldrex和strex配对使用,可以让总线监控ldrex到strex之间有无其他的实体存取该地址,如果有并发的访问,执行strex指令时,第一个寄存器的值被设置为1(Non-Exclusive Access)并且存储的行为也不成功;如果没有并发的存取,strex在第一个寄存器里设置0(Exclusive Access)并且存储的行为也是成功的。本例中,如果两个并发实体同时调用ldrex + strex ,如下图所示,在T3时间点上,CPU0的strexz会执行失败,在T4时间点上CPU1的strex会执行成功。所以CPU0和CPU之间只有CPU1执行成功了,执行ctrex失败的CPU的 teq %1,#0 判断语句不会成立,于是失败的CPU0通过bne 1b再次进入ldrex。ldrex和strex的这一过程不仅适用于多核之间的的并发,也适用于同一个核内部并发的情况。

详细的ldrex和strex指令可以看下面这位博主的,文章,讲的很通俗。
https://blog.csdn.net/roland_sun/article/details/47670099
4.1 整型原子操作
1.设置原子变量的值
void atomic_set(atomic_t *v, int i); /* 设置原子变量的值为i */
atomic_t v = ATOMIC_INIT(0); /* 定义原子变量v并初始化为0 */2.获取原子变量的值
atomic_read(atomic_t *v); /* 返回原子变量的值*/3.原子变量加/减
void atomic_add(int i, atomic_t *v); /* 原子变量增加i */
void atomic_sub(int i, atomic_t *v); /* 原子变量减少i */4.原子变量自增/自减
void atomic_inc(atomic_t *v); /* 原子变量增加1 */
void atomic_dec(atomic_t *v); /* 原子变量减少1 */5.操作并测试
int atomic_inc_and_test(atomic_t *v);
int atomic_dec_and_test(atomic_t *v);
int atomic_sub_and_test(int i, atomic_t *v);上述操作对原子变量执行自增、 自减和减操作后(注意没有加) , 测试其是否为0, 为0返回true, 否则返回false。
6.操作并返回
int atomic_add_return(int i, atomic_t *v);
int atomic_sub_return(int i, atomic_t *v);
int atomic_inc_return(atomic_t *v);
int atomic_dec_return(atomic_t *v);上述操作对原子变量进行加/减和自增/自减操作, 并返回新的值。
4.2 位原子操作
1.设置位
void set_bit(nr, void *addr);上述操作设置addr地址的第nr位, 所谓设置位即是将位写为1。
2.位清除
void clear_bit(nr, void *addr);上述操作清除addr地址的第nr位, 所谓清除位即是将位写为0。
3.位改变
void change_bit(nr, void *addr);上述操作对addr地址的第nr位进行反置。
4.位测试
test_bit(nr, void *addr);上述操作返回addr地址的第nr位。
5.测试并操作位
int test_and_set_bit(nr, void *addr);
int test_and_clear_bit(nr, void *addr);
int test_and_change_bit(nr, void *addr);上述test_and_xxx_bit(nr, void*addr) 操作等同于执行test_bit(nr, void*addr) 后再执行xxx_bit(nr, void*addr) 。
使用原子变量使设备只能被一个进程打开
static atomic_t xxx_available = ATOMIC_INIT(1); /* 定义原子变量*/
static int xxx_open(struct inode *inode, struct file *filp)
{
...
if (!atomic_dec_and_test(&xxx_available)) {
atomic_inc(&xxx_available);
return - EBUSY; /* 已经打开*/9 }
...
return 0; /* 成功 */
}
static int xxx_release(struct inode *inode, struct file *filp)
{
atomic_inc(&xxx_available); /* 释放设备 */
return 0;
}5. 自旋锁
1.自旋锁的使用
自旋锁(spin lock)是一种典型的对临界资源进行互斥访问的手段,其名称来源于它的工作方式。为了获得一个自旋锁,在某CPU上运行的代码需要先执行一个原子操作,该操作测试并设置(test and set)某个内存变量。由于它是原子操作,所以在操作完成之前其它执行单元不可能访问这个内存变量。由于它是原子操作,所以在该操作完成之前其它执行单元不可能访问这个内存变量。如果测试结果表明锁已经空闲,则程序获得自旋锁并继续执行;如果测试结果表明所仍被占用,程序将在一个小的循环内重复“测试并设置”操作,即进行所谓的自旋,通俗的说就是在原地打转。放自旋锁的持有者通过重置该变量释放这个自旋锁后,某个等待的“测试并设置”操作向其调用者报告锁已释放。
理解自旋简单的方法是把它看做一个变量,该变量把一个临界区标记为“我当前在运行,清稍等一会”或者标记为“我不在运行,可以被使用”。如果A执行单元首先进入历程,它将持有自旋锁,当B执行单元试图进入同一个例程时,将获知自旋锁已被持有,需等到A执行单元释放后才能进入。
在ARM体系结构下,自旋锁的实现借用了ldrex/strex指令、ARM处理器内存屏障指令dbm和dsb、wfe指令和sev指令,这类似于最上面我们自己实现的自旋锁的逻辑。既要保证排他性,也要处理好内存屏障。
LOCKED EQU 1
UNLOCKED EQU 0
lock_mutex
; 互斥量是否锁定?
LDREX r1, [r0] ; 检查是否锁定
CMP r1, #LOCKED ; 和"locked"比较
WFEEQ ; 互斥量已经锁定, 进入休眠
BEQ lock_mutex ; 被唤醒, 重新检查互斥量是否锁定
; 尝试锁定互斥量
MOV r1, #LOCKED
STREX r2, r1, [r0] ; 尝试锁定
CMP r2, #0x0 ; 检查STR指令是否完成
BNE lock_mutex ; 如果失败, 重试
DMB ; 进入被保护的资源前需要隔离, 保证互斥量已经被更新
BX lr
unlock_mutex
DMB ; 保证资源的访问已经结束
MOV r1, #UNLOCKED ; 向锁定域写"unlocked"
STR r1, [r0]
DSB ; 保证在CPU唤醒前完成互斥量状态更新
SEV ; 像其他CPU发送事件, 唤醒任何等待事件的CPU
BX lrlinnux中与自旋锁相关的操作主要有一下4种。
1.定义自旋锁
spinlock_t lock2.初始化自旋锁
spin_lock_init(lock);该宏用于动态初始化自旋锁
3.获得自旋锁
spin_lock(lock);该宏用于获得自旋锁lock,如果能够立即获得锁,他就马上返回,否则,它将在那里自旋,知道该自旋锁的保持者释放。
spin_trylock(lock);该宏尝试获得自旋锁lock,如果能立即获得锁,它获得锁并返回true,否则立即返回false,实际上不再“原地发展”。
4.释放自旋锁
spin_unlock(lock);该宏释放自旋锁lock,他与spin_lock或spin_trylock配对使用。
自旋锁一般被这样使用:
/* 定义一个自旋锁 */
spinlock_t lock;
spin_lock_init(lovk);
spin_lock(&lock); /* 获得锁,保护临界区 */
... /* 临界区 */
spin_unlock(&lock) /* 解锁 */自旋锁主要针对SMP或单CPU单内核可抢占的情况,对于单CPU和内核不支持抢占的系统,自旋锁退化为空操作,在单CPU和内核可抢占的系统中,自选苏持有期间中内核的抢占被禁止。由于内核可抢占的单CPU系统的行为实际上很类似于SMP系统,因此,在这样的单CPU系统中使用自旋锁仍十分重要。另外,在多核SMP的情况下,任何一个核拿到了自旋锁,该核上的抢占调度也被禁止了,但是没有禁止另外一个核的 抢占调度。
尽管用了自旋锁可以保证临界区不受别的CPU和本CPU内的抢占进程打扰,但是得到锁的代码路径在执行临界区的时候,还可能受到中断和底半部(bh)的影响。为了防止这种影响,就需要用到自旋锁的衍生、spin_lock()/spin_unlock()是自旋锁基址的基础,他们和关中local_irq_disable()/开中断local_irq_enable()、关底半部local_bh_disable()/开底半部local_irq_enable()、关中断并保留状态字local_irq_save()开中断并回复状态字local_irq_restore()结合就形成了整套自旋锁机制,关系如下:
spin_lock_irq() = spin_lock() + locak_irq_disable()
spin_unlock_irq() = spin_unlock() + locak_irq_enabke()
spin_lock_irqsave() = spin_lock() + local_irq_save()
spin_unlock_irqrestore() = spin_unlock() + local_irq_restore()
spin_lock_bh() = spin_lock() + local_bh_disable()
spin_unlock_bh() = spin_unlock() + spin_bh_enable()spin_lock_irq()、spin_lock_irqsave()、spin_lock_bh()类函数会自动为自旋锁的使用系好“安全带”以避免突如其来的中断驶入对系统造成的伤害。
在多核编程的时候,如果进程和中断可能访问同一片临界资源,我们一般需要在进程上下文中调用spin_lock_irqsave()、spin_unlock_irqrestore,在中断上下文中调用spin_lock()、spin_unlock(),如下图所示。这样在CPU0上,无论是进程上下文还是中断上下文获得了自旋锁,此后,如果CPU1无论是进程上下文,还是中断上下文想获得同一自旋锁,都必须忙等,这避免一切核间并发的可能性。同时,由于每个核的进程上下文持有锁的时候用的是spin_lock_irqsave(),所以该核上的中断是不能进入的,这避免了核内并发的可能性。

驱动工程师应谨慎使用自旋锁,而且在使用中还要特别注意如下几个问题。
1.自旋锁实际上是忙等锁,当锁不可用时,CPU一直循环执行“测试并设置”该锁直到可用而取得该锁,CPU在等待自旋锁时不做任何有用的工作,仅仅是等待。因此,只有在占用速派的时间极短的情况下,使用自旋锁才是合理的。当临界区很大,或有共享设备的时候,需要较长时间占用锁,使用自旋锁会降低系统的性能。
2.自旋锁可能导致系统死锁。引发这个问题最常见的情况是递归使用一个自旋锁锁,即如果一个已经拥有某个自旋锁的CPU想第二次获得这个自旋锁,则该CPu将死锁。
3.自旋锁锁定期间不能调用可能引起进程调的函数。如果进程获得自旋锁之后,再阻塞,如调用copy_form_user()、copy_to_user()、kmalloc()和msleep()等函数,在可能导致内核的崩溃。
4.在单核情况下编程的时候,也应该认为自己的CPU是多核的,驱动特别强调跨平台的概念。比如,在单CPU的情况下,若中断和进程可能访问同一临界区,进程里调用spin_lock_irqsave()是安全的,在中断里其实不调用spin_lock()也没有问题,因为spin_lock_irqsave可以保证这个CPU的中断服务程序不可能执行。但是,在多CPU下,spin_lock_irqsave()不能屏蔽另一个核的中断,所以另外一个核就可能造成并发问题。因此,无论如何让,我们在中断服务程序里面应该调用spin_lock()。
单CPU,可抢占
process1通过系统调用进入内核态,如果其需要访问临界区,则在进入临
界区前获得锁,上锁,V=1,然后进入临界区。
如果process1在内核态执行临界区代码的过程中发生了一个外部中断,当中
断处理函数返回时,因为内核的可抢占性,此时将会出现一个调度点,如果
CPU的运行队列中出现了一个比当前被中断进程process1优先级更高的进程
process2,那么被中断的进程将会被换出处理器,即便此时它正运行于内核
态。
如果process2也通过系统调用进入内核态,且要访问相同的临界区,则会形
成死锁(因为拥有锁的Process1永没有机会再运行从而释放锁。
多CPU
CPU1上的process1通过系统调用进入内核态,如果其需要访问临界区,则在
进入临界区前获得锁,上锁,V=1,然后进入临界区。
如果process1在内核态执行临界区代码的过程中发生了一个外部中
断,当中断处理函数返回时,因为内核的可抢占性,此时将会出现一个调度
点,如果CPU1的运行队列中出现了一个比当前被中断进程process1优先级更
高的进程process2,那么被中断的进程process1将会被换出处理器,即便此
时它正运行于内核态。
如果CPU2上的process3也通过系统调用进入内核态,且要访问相同的临
界区,因为得不到锁,它也会一直自璇下去。即2号CPU被死锁。
这时1号CPU的process2或其他进程如果通过系统调用也使用了临界区,
则CPU1就死锁了,同时把其它CPU页死锁了。
所以使用自旋锁保护的区域是工作在非抢占的状态;即使获取不到锁,在“自
旋”状态也是禁止抢占的。了解到这,我想咱们应该能够理解为何自旋锁保护
的代码不能睡眠了。试想一下,如果在自旋锁保护的代码中间睡眠,此时发
生进程调度,则可能另外一个进程会再次调用spinlock保护的这段代码。而
我们现在知道了即使在获取不到锁的“自旋”状态,也是禁止抢占的,而“自
旋”又是动态的,不会再睡眠了,也就是说在这个处理器上不会再有进程调度
发生了,那么死锁自然就不会发生了。
static inline void spin_lock(spinlock_t *lock)
{
raw_spin_lock(&lock->rlock);
}
#define raw_spin_lock(lock) _raw_spin_lock(lock)
#define _raw_spin_lock(lock) __LOCK(lock)
#define __LOCK(lock) \
do { preempt_disable(); ___LOCK(lock); } while (0)
#define preempt_count_inc() preempt_count_add(1)
#define preempt_count_add(val) __preempt_count_add(val)
static __always_inline void __preempt_count_add(int val)
{
*preempt_count_ptr() += val;
}
static __always_inline volatile int *preempt_count_ptr(void)
{
return ¤t_thread_info()->preempt_count;
}
preempt_disable()的功能是关抢占
抢占计数存放着被持有锁的数量和preempt_disable()的调度次数,如果计
数是0,那么内核可以进行抢占,如果为1或更大的值,那么内核就不会进行
抢占。这个计数非常有用,它是一种对原子操作和睡眠很有效的调试方法。
函数preempt_count()返回这个值。
可以看到,上面举得例子都是在一定情况下,即自旋锁在锁定期间在该cpu上不能睡眠,不能调度,是有可能会发生死锁等情况,因为我们不能保证其它程序不会调用这个驱动,所以为了不出现死锁等情况,统一规定在持有锁期间,不能睡眠,不能调度。
单处理器非抢占内核下:自旋锁会在编译时被忽略;
单处理器抢占内核下:自旋锁仅仅当作一个设置内核抢占的开关;
多处理器下:此时才能完全发挥出自旋锁的作用,自旋锁在内核中主要用来防止多处理器中并发访问临界区,防止内核抢占造成的竞争。
用户抢占在以下情况下产生:
从系统调用返回用户空间
从中断处理程序返回用户空间 内核抢占会发生在:
当从中断处理程序返回内核空间的时候,且当时内核具有可抢占性;
当内核代码再一次具有可抢占性的时候。(如:spin_unlock时)
如果内核中的任务显式的调用schedule()
如果内核中的任务阻塞。
下面代码是,使用自旋锁使设备只能被一个进程打开
int xxx_count = 0; /* 定义文件打开次数计数 */
static spinlock_t xxx_lock;
static int xxx_open(struct inode *inode, struct file *file)
{
...
spin_lock(&xxx_lock);
if(xxx_count) { /* 文件以被打开 */
spin_unlock(&xxx_lock);
return -EBUSY;
}
xxx_count++; /* 增加使用次数 */
spin_unlock(&xxx_lock);
...
return 0;
}
static int xxx_realese(struct inode *inode, struct file *file)
{
...
spin_lock(&xxx_lock);
xxx_count --; /* 减少使用次数 */
spin_unlock(&xxx_lock);
return 0;
}注:因为xxx_count ++ 、xxx_count --可能不止一条汇编指令或不是单周期指令,所以在执行期间可能会中断或高优先级任务被打断,造成并发。所以要用自旋锁保护,防止执行期间被打断。当然这里使用自旋锁只是一个例子,一般这种使用原子操作会更简单一些。
5.2 读写自旋锁
自旋锁不关心锁定的临界区究竟在进行什么操作,不管是读还是写,他都一视同仁。即便多个执行单元同时读取临界资源也会被锁住。实际上,对共享资源并发访问时,读个执行单元同时读取它是不会有问题的,自旋锁的衍生锁读写自旋锁(rwlock)可允许读的并发。读写自旋锁是一种比自旋锁颗粒度更小的机制,它保留了“自旋”的概念,但是在写操作方面,只能最多有1个写进程,在读操作方面,同时可以有多个读执行单元。当然,读和写页不能同时进程。
读写自旋锁涉及的操做如下。
1.定义和初始化读写自旋锁
rwlock_t my_rwlock;
rwlock_init(&myrw_lock);2.读锁定
void read_lock(rwlock_t *lock);
void read_lock_irqsave(rwlock_t *lock,unsigned long flags);
void read_lock_irq(rwlock_t *lock);
void read_lock_bh(rwlock_t *lock);3.读解锁
void read_unlock(rwlock_t *lock);
void read_unlock_irqrestore(rwlock_t *lock,unsigned long flags);
void read_unlock_irq(rwlock_t *lock);
void read_unlock_bh(rwlock_t *lock);
在对共享资源进行读取之前, 应该先调用读锁定函数, 完成之后应调用读解锁函数。
read_lock_irqsave() 、 read_lock_irq() 和read_lock_bh() 也分别是read_lock() 分别与local_irq_save() 、 local_irq_disable() 和local_bh_disable() 的组合, 读解锁函数read_unlock_irqrestore() 、 read_unlock_irq() 、 read_unlock_bh() 的情况与此类似。
4.写锁定
void write_lock(rwlock_t *lock);
void write_lock_irqsave(rwlock_t *lock,unsigned long flahs);
void write_lock_irq(rwlock_t *lock);
void write_lock_bh(rwlock_t *lock);
int write_trylock(rwlock_t *lock);5.写解锁
void write_unlock(rwlock_t *lock);
void write_unlock_irqstore(rwlock_t *lock,unsigned long flags);
void write_unlock_irq(rwlock_t *lock);
void write_unlock_bh(rwlock_t *lock);write_lock_irqsave() 、 write_lock_irq() 、 write_lock_bh() 分别是write_lock() 与local_irq_save() 、 local_irq_disable() 和local_bh_disable() 的组合, 写解锁函数write_unlock_irqrestore() 、 write_unlock_irq() 、 write_unlock_bh() 的情况与此类似。
在对共享资源进行写之前, 应该先调用写锁定函数, 完成之后应调用写解锁函数。 和spin_trylock()一样, write_trylock() 也只是尝试获取读写自旋锁, 不管成功失败, 都会立即返回。
读写自旋锁一般这样被使用:
rwlock_t lock; /* 定义rwlock */
rwlock_init(&lock); /* 初始化rwlock */
/* 读时获取锁 */
read_lock(&lock);
... /* 临界资源 */
read_unlock(&lock);
/* 写时获取锁 */
write_lock_irqsave(&lock,flags);
... /* 临界资源 */
write_unlock_irqrestore(&lock, flags);
5.3 顺序锁
顺序锁(seqlock)是对读写锁的一种优化,若使用顺序锁,读执行单元不会被写执行单元阻塞,也就是说,读执行单元在写执行单元对顺序锁保护的共享资源进行写操作时仍然可以继续读,而不必等待写执行单元完成写操作,写执行单元也不需要等待所有读执行单元完成读操作才去进行写操作。但是,写执行单元与写执行单元仍然是互斥的,即如果有写执行单元在进行写操作,其它执行单元不必自旋在那里,直到写执行单元释放了顺序锁。
对于顺序锁而言,尽管读写之间不互相排斥,但是如果读执行单元在读操作期间,写执行单元已经发生了写操作,那么,读执行单元必须重新读取数据,以便确保得到的数据是完整的。所以,在这种情况下,读端可能反复读多次同样的区域了能读到有效的数据(最新的)。
linux内核中,写执行单元涉及的顺序操作如下。
1.获得顺序锁
void write_seqlock(seqlock_t *s1);
int write_tryseqlock(seqlock_t *s1);
write_seqlock_irqsave(lock, flags);
write_sseqlock_irq(lock);
write_seqlock_bh(lock);其中,
write_seqlock_irqsave() = local_irq_save() + write_seqlock();
write_sseqlock_irq() = local_irq_disable() + write_seqlock();
write_seqlock_bh(lock) = local_bh_disable() + write_seqlock();2.释放顺序锁
void write_sequnlock(seqlock_t *s1);
write_sequnlock_irqrestore(lock,flags);
write_sequnlock_irq(lock);
write_sequnlock_bh(lock);其中,
write_sequnlock_irqrestore() = write_sequnlock() + local_irq_restore();
write_sequnlock_irq() = write_sequnlock() + local_irq_enable();
write_sequnlock_bh(lock) = write_sequnlock() + local_bh_enable();写执行单元使用顺序锁的模式如下:
write_seqlock(&seqlock_a);
... /* 写操作代码块 */
write_sequnlock(&seqlock_a);因此,对写执行单元而言,它的使用与自旋锁相同。
读执行单元涉及的顺序锁操作如下。
1.读开始
unsigned read_seqbegin(const seqlock_t *s);
read_seqbegin_irqsave(lock,flags);读执行单元在对被顺序锁s保护的共享资源进行访问前需要调用该函数,该函数返回顺序锁s的当前顺序号。其中,
read_seqbegin_irqsave() = local_irq_save() + read_seqbegin()2.重读
int read_seqretry(const seqlock_t *s1,unsigend iv);
read_seqretry_irqresrore(lock,iv, flags);读执行单元在访问完被顺序锁s1保护的共享资源后需要调用该函数来检查,在读访问期间是否有写操作。如果有写操作,读执行单元就需要重新进行读操作。其中,
read_seqretry_irqrestore() = read_seqretry() + local_irq_restore()读执行单元使用顺序锁的模式如下
do {
seqnum = read_seqbegin(&seqlock_a);
/* 读操作代码块 */
...
} while(read_seqretry(&seqlock_a, seqnum));5.4 读-复制-更新
RCU(read-copy-update 读-复制-更新)它是基于其原理命名的。RCU并不是新的锁机制,早在20世纪80年代就有了这种机制,而在linux中开发内核2.5.43时引入该技术,并正式包含在2.6内核中。
linux社区关于RCU的经典文档位于
https://www.kernel.org/doc/ols/2001/read-copy.pdf
linux内核源代码Documentation/RCU/也包含了RCU的一些讲解。
不同于自旋锁,使用RCU的读端没有锁,内存屏障,原子操作类的开销,几乎可以认为是直接读(只是简单的表明是读开始和读结束),而RCU的写执行单元在访问它的共享资源前首先复制一个副本,然后对副本进行修改,最后使用一个会掉机制在适当的时机把原来数据的指针重新指向新的被修改的数据,这个时机就是所有引用该数据的CPU都退出对共享数据读操作的时候。等待适当实际的这一时期称为宽限期(Gracwe Period)
比如,有下面的一个由struct foo结构体组成的链表:
struct foo {
struct lsit_head lsit;
int a;
int b;
int c;
};假设进程A要修改链表中某个节点N的成员a,b。自旋锁的思路是排他性的访问这个链表,等所有其它持有自旋锁的进程或中断把自旋锁释放后,进程A再拿到自旋锁访问链表并找到N节点,之后修改它的a,b两个成员,完成后解锁。而RCU的思路则不同,它直接创造一个新的节点M,把N的内容复制给M,之后在M上修改a,b,并用M来代替N原来在链表上的位置。之后进程A等待在链表前期已经存在的所有读端结束后(即宽限期,通过下文说的synchronize_rcu()API完成),再释放原来的N。用代码描述这个逻辑就是:
struct foo {
struct lsit_head lsit;
int a;
int b;
int c;
};
LIST_HEAD(head);
/* .... */
p = search(head, key);
if(NULL == p) {
/* take approproate action,unlock,and retutn */
}
q = kmalloc(sizeof(*p), GFP_KERNEL);
*q = *p;
q->b = 2;
q->c = 3;
list_replace_rcu(&p->list, &q->list);
synchronize_rcu();
kfree(p);
RCU可以看做读写锁的高性能版本,相比读写锁,RCU的优点在于既允许对个读执行单元同时访问保护的数据,有允许多个读单元和多个写执行单元同时访问被保护 的数据。但是,RCU不能替代读写锁,因为如果写比较多时,对读执行单元的性能提高不能弥补写执行单元同步导致的损失。因为使用RCU时,写执行单元之间的同步开销会比较大,它需要延时数据结构的释放,复制被修改的数据结构,它也必须使用某种锁机制来同步并发的其它写执行单元的修改操作。
读者在访问被RCU保护的共享数据期间不能被阻塞,这是RCU机制得以实现的一个基本前提,也就说当读者在引用被RCU保护的共享数据期间,读者所在的CPU不能发生上下文切换,spinlock和rwlock都需要这样的前提。写者在访问被RCU保护的共享数据时不需要和读者竞争任何锁,只有在有多于一个写者的情况下需要获得某种锁以与其他写者同步。
写者修改数据前首先拷贝一个被修改元素的副本,然后在副本上进行修改,修改完毕后它向垃圾回收器注册一个回调函数以便在适当的时机执行真正的修改操作。等待适当时机的这一时期称为grace period,而CPU发生了上下文切换称为经历一个quiescent state,时间宽限grace period就是所有CPU都经历一次quiescent state所需要的等待的时间。垃圾收集器就是在grace period之后调用写者注册的回调函数来完成真正的数据修改或数据释放操作的。
linux中提供RCU操作如下4种。
1.读锁定
rcu_read_lock()
rcu_read_lock_bh()2.读解锁
rcu_read_unlock()
rcu_read_unlock_bh()使用RCU进行读的模式如下:
rcu_read_lock()
... /* 读临界区 */
rcu_read_unlock() 3.同步RCU
synchronize_rcu()该函数RCU写执行单元调用,它将阻塞写执行单元,知道当前CPU上所有的已经存在的读执行单元完成读临界区,写执行单元才可以继续下一步操作。synchronize_rcu()并不需要等待后续读临界区完成。如下图

synchronize_rcu()探测所有的rcu_read_lock()被rcu_read_unlock()结束的过程很类似java语言额垃圾回收的工作。
4.挂接回调
void call_rcu(struct *rcu_head,
void (*func)(struct rcu_head *rcu));函数call_rcu()也由RCU写执行单元调用,与synchronize_rcu()不同的是,它不会使写执行单元阻塞,因而可以在中断上下文或软中断中使用。该函数把函数func挂接到RCU回调函数链上,然后立即返回。挂接的回调函数会在一个宽限期结束(即所有已经存在的RCU读进阶区完成【所有CPU都进程过一次上下文切换】)后被执行。
rcu_assign_pointer(p, v)给RCU保护的指针附一个新的值。
rcu_dereference(p)读端使用rcu_dereference()获得一个RCU保护的指针,直呼既可以安全地引用它(访问它指向的区域)。一般需要在rcu_read_lock()、rcu_read_unlock()保护的区间引用这个指针。例如
rcu_read_lock();
irq_rt = rcu_dereference(kvm->irq_routing);
if(irq < irq_rt->nr_rt_enteries)
hlist_for_entry(e, &irq_rt->map[irq], link) {
if(likely(e->type == KVM_IRQ_ROUTING_MSI))
ret = kvm_set_msi_inatomic(e, kvm);
else
ret = -EWOULDBLOCK;
break;
}
rcu_read_unlock();上述代码取自virt/kvm/irq_comm.c的kvm_set_irq_inatomic() 函数
rcu_access_pointer(p)读端使用rcu_access_pointer()获取一个rcu保护的指针,之后并不引用它。这种情况下,我们只关心指针本身的值,而不关心指针本身的内容。比如我们可以使用该API来判断指针是否为NULL。
把rcu_assign_pointer()和rcu_dereference()结合起来使用,写端分配一个新的struct foo内存,并初始化其中的成员,之后把该结构体的地址赋值给全局的gp的指针:
struct foo {
int a;
int b;
int c;
};
struct foo *gp = NULL;
/* .... */
p = kmalloc(sizeof(*p), GFP_KERNEL);
p->a = 1;
p->b = 2;
p->c = 3;
rcu_assign_pointer(gp, p);读端访问该片区域:
rcu_read_lock();
p = rcu_dereference(gp);
if(NULL != p) {
do_somethig_with(p->a, p->b, p->c);
}
rcu_read_unlock();上述代码中,我们可以把写端rcu_assign_pointer()看成发布了gp,而读端rcu_dereference()看成订阅了gp。它保证读端可以看到rcu_assign_pointer()之前所有内存被社会的情况(即gp->a,gp->b,gp->c等于1,2,3对于读端可见)。由此可见,与RCU相关的原语已经内嵌了相关的编译屏障或内存屏障。
对于链表数据结构而言,linux内核增加了专门的RCU保护的链表操作API:
static inline void list_add_rcu(struct list_head *new, struct list);该函数把链表元素new插入RCU保护的链表head的开头。
static inline void list_add_tail_rcu(struct lsit_head *new,
struct list_head *head);
该函数类似于list_ass_rcu(),它将把新的链表元素new添加到被RCU保护的链表末尾。
static inline void list_del_rcu(struct list_head *entry);
该函数从RCU保护的链表中删除指定的链表元素entry。
static inline void list_replace_rcu(struct list *old, struct list_head *new);它使用新的链表元素new取代旧的链表元素old。
list_for_each_entry_rcu(pos, head);该宏用于遍历由RCU保护的链表head,只要在读执行单元临界区使用该函数,它就可以安全地和其它RCU保护的链表操作函数(如list_add_rcu)并发运行。
链表的写端代码模型如下:
struct foo {
struct list_head list;
int a;
int b;
int c;
};
LIST_HEAD(head);
/* ... */
p = kmalloc(sizeof(*p), GFP_KERNEL);
p->a = 1;
p->b = 2;
p->c = 3;
list_add_rcu(&p->list, &head);
链表的读端代码则形如:
rcu_read_lock();
list_for_each_entry_rcu(p, head, list) {
do_something(p->a, p->b, p->c);
}
rcu_read_unlock();前面已经看大了对RCU保护链表中节点进行修改以及添加新节点的动作,下面我们看一下RCU保护的链表删除节点N的工作。写端扥两个步骤,第一步是从链表中删除N,之后等第一个宽限期结束,在释放N的内存。下面的代码分别用读写锁和RCU两种不同的方法描述着一过程;

关于RCU的实现细节可以查看这位博主的文章。
http://blog.jobbole.com/106856/
6. 信号量
信号量(semaphore)是操作系统中最经典的用于同步和互斥的手段,信号量的值可以是0,1,或者n。信号量与操作系统中和的经典概念PV操作对应。
P(S):将信号量S的值减1,即S = S -1;
如果S >= 0,则该进程继续执行;否则该进程置位等待状态,排入等待队列。
V(S):将信号量S的值加1,即S = S + 1;
如果S > 0,唤醒队列中等待信号量的进程。
linux中与信号量相关的操作主要有下面几种。
1.定义信号量
下列代码定义名称为sem的信号量
struct semaphore sem;2.初始化信号量
void sema_init(struct semaphore *sem, int val);该函数初始化信号量,并设置信号量sem的值为val。
3.获得信号量
void down(struct semaphore *sem);该函数用于获得信号量sem,他会导致睡眠,因此不能在中断上下文使用。
int down_interruptible(struct semaphore *sam);
该函数功能与down类似,不同之处为,因为down()进入睡眠状态不能被信号打断,但因为down_interruptible()进入睡眠状态的进程能被信号打断,信号也会导致该函数返回,这时候函数的返回值非0.
int down_trylock(struct semaphore *sem);
该函数尝试获得信号量sem,如果能够立即获得,他就获得该信号量并返回0,否则,返回非0值。它不会导致调用者睡眠,可以在中断上下文中使用。
在使用down_interruptible()获得信号量时,对返回值一般会进程检查,如果非0,通常立即返回-ERESTARSYS,如
if(down_interruptible(&sem))
return -ERESTARTSYS;4.释放信号量
void up(struct semaphore *sem);该函数释放信号量sem,唤醒等待者。
作为一种可能的互斥手段,信号量可以保护临界区,它的使用方式和自旋锁了四。与自旋锁相同,只有得到了信号的进程才能执行临界区代码。但是,与自旋锁不同的是,当获取不到信号量时,进程不会原地的打转而是进入休眠等待状态,用作互斥时,信号量一般这样被使用:

由于新的linux内核更倾向于直接使用mutex作为互斥手段,信号量用作互斥不再被推荐使用。
信号量也可以用于同步,一个进程A执行down()等信号量,另一个进程B执行up()释放信号量,这样进程A就同步地等待了进程B。其过程类似:

此外,对于关心具体数值的生产者/消费者问题,使用信号量则较为合适。因为生产者/消费者问题也是一种同步问题。
7 互斥体
互斥体也叫互斥锁。
尽管信号量已经可以实现互斥的功能,但是正宗的mutex在linux内核中还是真实地存在的。
下面代码定义了名为my_mutex的互斥体并初始化它:
struct mutex my_muttex;
mutex_init(&my_mutext);下面两个函数用于获取互斥体:
void mutex_lock(struct mutex *lock);
int mutex_lock_interrupt(struct mutex *lock);
int mutex_trylock(struct mutex *lock);mutex_lock()与mutex_lock_interrupt()的区别和down()与down_trylock()的区别完全一致,前者引起的睡眠不能被信号打断,而后者可以。mutex_trylock()用于尝试获得mutext,获取不到mutex时不会引起进程睡眠。
下列函数用户释放互斥体:
void mutex_unlock(struct mutex *lock);mutex的使用方法和信号量用于互斥的场合完全一样:
struct mutex my_mutex; /* 定义互斥体 */
mutex_init(&my_mutex); /* 初始化互斥体 */
mutex_lock(&my_mutex); /* 获取互斥体 */
... /* 临界资源 */
mutex_unlock(&my_mutex); /* 释放互斥体 */自旋锁和互斥都是解决互斥问题的基本手段,面对特定情况,应该如何让取舍这两种手段呢?选择的一句是临界区的性质和系统的特点。
严格意义上说,互斥体和自旋锁属于不同层次的互斥手段,前者的实现依赖于后者。在互斥体本身的实现上,为了保证互斥体结构存取的原子性,需要自旋锁来互斥。所以自旋锁属于更底层的手段。
/*
* Simple, straightforward mutexes with strict semantics:
*
* - only one task can hold the mutex at a time
* - only the owner can unlock the mutex
* - multiple unlocks are not permitted
* - recursive locking is not permitted
* - a mutex object must be initialized via the API
* - a mutex object must not be initialized via memset or copying
* - task may not exit with mutex held
* - memory areas where held locks reside must not be freed
* - held mutexes must not be reinitialized
* - mutexes may not be used in hardware or software interrupt
* contexts such as tasklets and timers
*
* These semantics are fully enforced when DEBUG_MUTEXES is
* enabled. Furthermore, besides enforcing the above rules, the mutex
* debugging code also implements a number of additional features
* that make lock debugging easier and faster:
*
* - uses symbolic names of mutexes, whenever they are printed in debug output
* - point-of-acquire tracking, symbolic lookup of function names
* - list of all locks held in the system, printout of them
* - owner tracking
* - detects self-recursing locks and prints out all relevant info
* - detects multi-task circular deadlocks and prints out all affected
* locks and tasks (and only those tasks)
*/
struct mutex {
/* 1: unlocked, 0: locked, negative: locked, possible waiters */
atomic_t count;
spinlock_t wait_lock; /* 互斥体里面包含自旋锁,用来满足其原子性 */
struct list_head wait_list;
#if defined(CONFIG_DEBUG_MUTEXES) || defined(CONFIG_SMP)
struct task_struct *owner;
#endif
#ifdef CONFIG_MUTEX_SPIN_ON_OWNER
struct optimistic_spin_queue osq; /* Spinner MCS lock */
#endif
#ifdef CONFIG_DEBUG_MUTEXES
const char *name;
void *magic;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
};
互斥体是进程级别的,用于多个进程之间对资源的互斥,虽然也是在内核中,但是该内核执行路径是以进程的身份,代表进程来争夺资源的。如果禁止失败,会发生进程上下文切换,当前进程进入睡眠状态,CPU将运行其它进程。鉴于进程上下文切换的开销很大,因此只有当进程占用资源时间比较长时,用互斥体才是较好的选择。
当所要保护的临界区访问时间比较短时,用自旋锁是非常方便的,因为它可节省上下文切换的时间。但是CPU得不到自旋锁会那里空转知道其他执行单元解锁为止,所以要求不能在临界区里长时间停留,否则会降低系统的效率。
由此,可以总结出自旋锁和互斥体选用的3箱原则。
1.当锁不能获取到时,使用互斥体的开销是是进程上下文切换时间,使用自旋锁的开销是等待获取自旋锁(由临界区执行时间决定)。若临界区较小,宜使用自旋锁,若进阶区很大,使用互斥体。
2.互斥体所保护的临界资源区可包含可能引起阻塞的代码,而自旋锁则绝对要避免用来保护含这样代码的进阶区。因为阻塞意味着要进行进程的切换,若果进程被切换出去后,另一个进程企图获取本自旋锁,死锁就会发生。
3.互斥体存在于进程上下文,因此,如果被保护的共享资源需要在中断或软中断情况下使用,则在互斥体和自旋锁之间只能选手自旋锁。当然,如果一定要使用互斥体,则只能通过mutex_trylock(),方式进行,不能获取就立即返回避免阻塞。
8.完成量
linux提供了完成量(completion,关于这个名词,至今没有好的翻译,本书作者[宋宝华],将其翻译为“完成量”),它用于一个执行单元等待另一个执行单眼执行完某事。
linux中完成量相关的操作主要有一下4种。
1.定义完成量
下列代码定义名为my_completion的完成量:
struct complteion my_completion;2.初始化完成量
下列代码初始化或重新初始化my_completion这个完成量的值为0(即米有完成的状态)
init_completion(&my_completion);
reinit_completion(&my_copmletion);3.等待完成量
下列函数用于等待一个完成量被唤醒:
void wait_for_completion(struct copmletion *c);4.唤醒完成量
下面两个函数用于唤醒完成量:
void completion(struct completion *c);
void completiom_all(struct completion *c);前者只唤醒一个等待的执行单元,后者释放所有等待同一完成量的执行单元。
完成量用于同步的流程一般如下:

9 总结
并发和竞态广泛存在, 中断屏蔽、 原子操作、 自旋锁和互斥体都是解决并发问题的机制。 中断屏蔽很少单独被使用, 原子操作只能针对整数进行, 因此自旋锁和互斥体应用最为广泛。
自旋锁会导致死循环, 锁定期间不允许阻塞, 因此要求锁定的临界区小。 互斥体允许临界区阻塞, 可以适用于临界区大的情况