论文:Faster Training of Mask R-CNN by Focusing on Instance Boundaries
Mask R-CNN是实例分割的经典模型,作者通过在Mask R-CNN框架上附加一个新任务,达到更快的网络收敛速度。
该文对MaskR-CNN添加了一个新的预测任务,称为Edge Agreement Head,它的灵感来自人工实例标注的方式。当人们对实例进行像素级标注的时候,仅仅会关注实例的边缘部分,而实例内部则只需要简单的复制边缘的标注信息就可以了。所以实例的mask边缘非常有用,它们很好地表达了实例。
Edge Agreement Head的作用即鼓励深度网络训练时预测的实例mask边缘与groundtruth的边缘相似。
主要解决:降低训练时间,更准确沿着边缘分割
亮点:增加一个边缘预测部分( Edge Agreement Head)
结果:
由于附加网络分支仅在训练期间相关,因此与Mask R-CNN相比,推断速度保持不变。在默认的Mask R-CNN设置中,与基线相比,MS COCO度量的训练速度提高了29%,整体提升了8.1%。
算法思想
作者通过观察Mask R-CNN训练前期输出的预测图像,发现很多时候边缘都不在点上,显然神经网络在走弯路。如图:

这是Mask R-CNN深度网络训练前期的一些预测的Mask,发现它并没有像人类一样先把边缘找出来,甚至缺失的很离谱(你可以预测的不很精细准确,但至少要表现出在向这个方向努力吧!)。
为了避免神经网络走弯路,作者把实例的边缘信息作为一种监督的指引,即将groundtruth进行边缘滤波,让神经网络同时去预测实例的边缘。
Mask R-CNN的多任务损失函数:

具体的做法是,增加一个新分支,预测边缘并与groundtruth的边缘相比较,如图:

作者仅是对每个实例28*28大小区域内(所以增加的计算量有限)进行上述操作,通过添加简单的3*3边缘检测计算预测和groundtruth的边缘,因为边缘检测往往和图像平滑一起用,所以右边的图增加了平滑的步骤。
上图中L代表计算两者差异的方式,如下:

作者尝试了普通的Sobel滤波和Laplacian滤波检测边缘(Sobel滤波效果更好)。
作者通过Edge Agreement Head方式增加了一个损失函数,模型复杂度略微增加,没添加任何额外的需要训练的模型变量,训练的计算成本增加很小,而网络推断时不增加计算量。
实验结果
作者在MS COCO 2017数据集上做了实验,比较训练达到160k steps时基准模型和提出的模型的COCO AP metrics精度。

Table 1说明当训练达到160k steps时,使用Edge Agreement Head的模型训练达到了更高的精度,尤其是使用Soble边缘算子的模型。
Table 2表明不使用图像平滑加速更加明显,达到更高的精度。
预测结果比较:

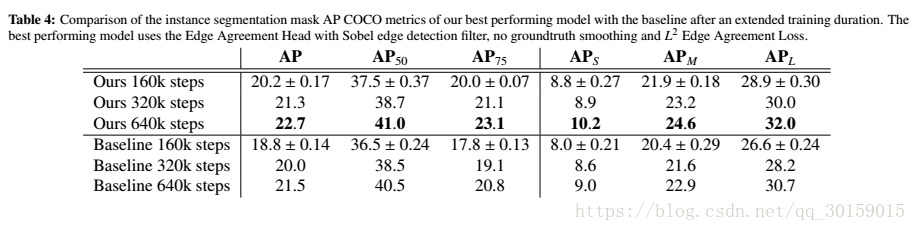
Table 4表明,拉长训练时间,使用Edge Agreement Head仍然获得了更高的精度。
消融实验结果:
1、Sobel滤波器比拉普拉斯滤波器具有更好的性能
2、ground truth mask平滑没有改善,平滑甚至比没有平滑基础的训练更慢。我们观察到,如果使用预测的mask被平滑,则训练显着更稳定
3、边缘损失中,L2损失表现最佳