官方文档:http://hadoop.apache.org/docs/r3.1.1/
1. 安装包准备
- hadoop3.1 :链接:https://pan.baidu.com/s/13EI77WAG_Y95HqGrqqn9dA 密码:ut43
- jdk1.8 :链接:https://pan.baidu.com/s/1huUeiQYTpJkZlAClkYIi1w 密码:taih
在主机端下载后,通过WinSCP软件将两个安装包传输到Redhat上。如图:
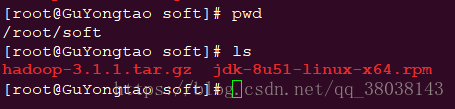
2. 安装jdk
命令:
rpm -ivh jdk-8u51-linux-x64.rpm
安装完成后,执行命令如下:
发现,java的版本仍然为1.7.0_65。rpm命令查询,系统默认已安装了jdk1.6和1.7。则依次卸载1.6和1.7:
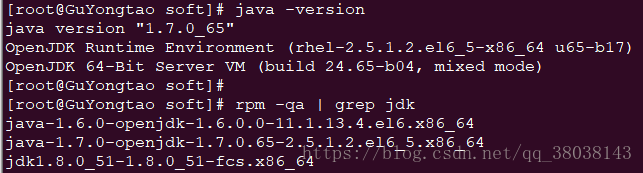
rpm -e java-1.6.0-openjdk-1.6.0.0-11.1.13.4.el6.x86_64
rpm -e java-1.7.0-openjdk-1.7.0.65-2.5.1.2.el6_5.x86_64
并且修改/etc/profile文件,在文件末尾添加:
export JAVA_HOME=/usr/java/jdk1.8.0_51
执行命令,使/etc/profile文件生效:
source /etc/profile
再次查看java版本,安装成功:

3. 设置免密登录
依次执行命令:
ssh-keygen -t rsa
cp /root/.ssh/id_rsa.pub /root/.ssh/authorized_keys
执行ssh localhost查看系统是否能够免密登录。
4. hadoop安装
解压hadoop-3.1.1:
tar -zxvf hadoop-3.1.1.tar.gz
移动压缩后的文件,并修改名称:
mv hadoop-3.1.1 /usr/local/hadoop
查看hadoop版本:
cd /usr/local/hadoop/
./bin/hadoop version

配置文件:
修改文件~/.bashrc,在文件末尾加入:
export JAVA_HOME=/usr/java/jdk1.8.0_51
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
5. 单机模式
hostname配置
在/etc/hosts和/etc/sysconfig/network配置如下(在此将GuYongtao修改为master,可根据自己Linux的主机名进行配置),其中10.13.7.72为eth1的IP地址:

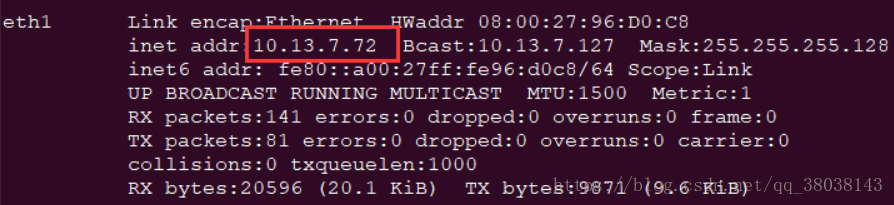
**重启网络:service network restart
单机测试:
依次执行如下命令:
[root@master hadoop]# pwd
/usr/local/hadoop
[root@master hadoop]#
[root@master hadoop]# mkdir input
[root@master hadoop]# cp etc/hadoop/*.xml input/
[root@master hadoop]# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.1.jar grep input/ ./output 'dfs[a-z.]+'
效果:
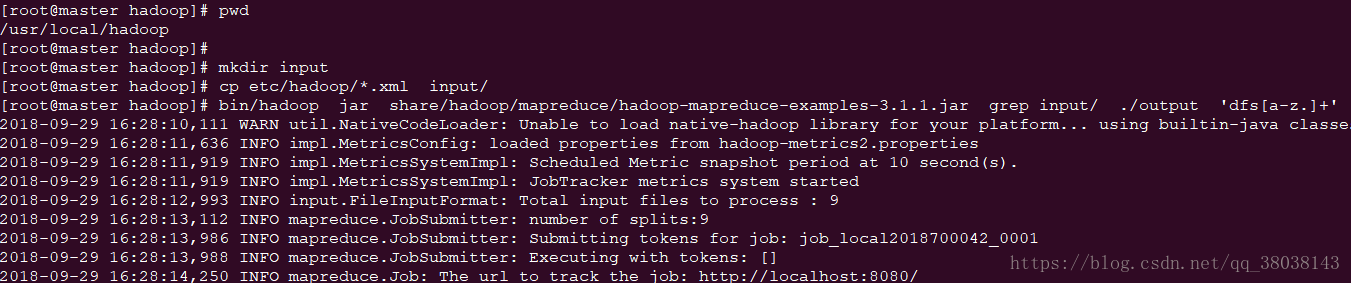
查看结果,如下即成功:

6. 伪分布式搭建
6.1 hadoop配置
6.1.1 创建目录:
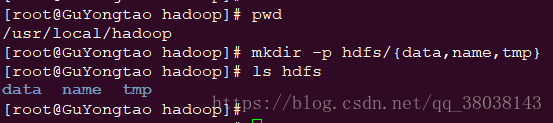
6.1.2 修改配置文件:
进入路径:
修改以下文件内容:
- vim hadoop-env.sh
在该文件末尾加入:
export JAVA_HOME=/usr/java/jdk1.8.0_51
export HADOOP_PID_DIR=/usr/local/hadoop/hdfs/tmp
- vim core-site.xml
注:将下列所有配置文件的master修改为自己Redhat的主机名(如下面代码第9行,修改为hdfs://你的主机名:9000)
在<configuration中加入以下内容,:
<configuration>
<property>
<!-- 这个属性用来指定namenode的hdfs协议的文件系统通信地址, -->
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<!-- 这个属性用来执行文件IO缓冲区的大小-->
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<!-- 指定hadoop临时目录,前面用file:表示是本地目录。 -->
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/hdfs/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>
- vim hdfs-site.xml
在<configuration中加入以下内容:
<configuration>
<property>
<!-- secondary namenode的http通讯地址-->
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<!-- namenode数据的存放地点。记录了hdfs系统中文件的元数据-->
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hdfs/name</value>
</property>
<property>
<!-- datanode数据的存放地点。也就是block块存放的目录了-->
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hdfs/data</value>
</property>
<property>
<!-- hdfs的副本数设置。-->
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<!-- 开启hdfs的web访问接口。好像默认端口是50070-->
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
- vim mapred-site.xml
在<configuration中加入以下内容:
<configuration>
<property>
<!-- 指定mr框架为yarn方式,Hadoop二代MP也基于资源管理系统Yarn来运行 -->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<!-- 指定mr框架jobhistory的内部通讯地址。 -->
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<!-- 指定mr框架web查看的地址 -->
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
- vim yarn-site.xml
在<configuration中加入以下内容:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<!--yarn总管理器的IPC通讯地址-->
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<!--yarn总管理器调度程序的IPC通讯地址-->
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<!--yarn总管理器的IPC通讯地址-->
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<!--yarn总管理器的IPC管理地址-->
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<!--yarn总管理器的web http通讯地址-->
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
共5个文件,可下载:
链接:https://pan.baidu.com/s/1-yzHluKD7fupsAFE2tVweg
提取码:hx8m
7. 报错处理(可以跳过此步骤,直接进入8. hadoop启动)
由于启动过程发生报错,作出以下修改:
进入路径:
[root@master sbin]# pwd
/usr/local/hadoop/sbin
- 修改start-dfs.sh,stop-dfs.sh
在这两个文件的头部加入:
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
- 修改start-yarn.sh,stop-yarn.sh
在这两个文件的头部加入:
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
- 修改文件:
vim /usr/local/hadoop/etc/hadoop/log4j.properties
在文件末尾加入:
log4j.logger.org.apache.hadoop.util.NativeCodeLoader=ERROR
8. hadoop启动(若启动时报错,可以回到7. 报错处理)
修改/etc/profile文件,在文件末尾加入,并执行source /etc/profile:
export PATH=$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin
格式化namenode节点:
命令:
hdfs namenode -format
效果:
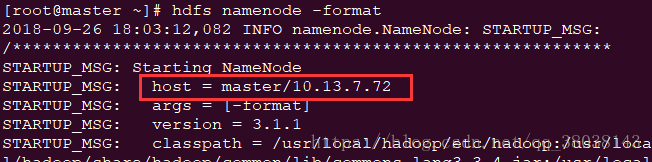

启动:
系统能够免密登录后,启动命令(停止命令:stop-all.sh):
start-all.sh
效果:

命令:jps
效果:

在Linux的浏览器查看(hadoop2.x 端口为:50070):
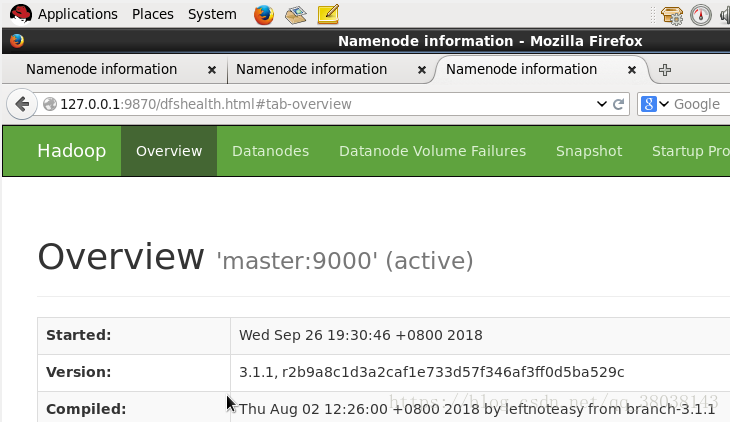
在主机的浏览器查看(主机能ping通Linux)(可选):
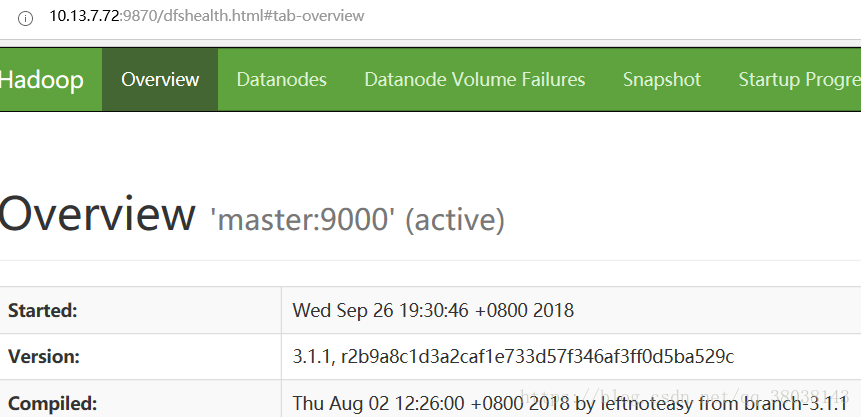
出现上图结果则安装成功。
参考链接:
https://blog.csdn.net/cx105200/article/details/78284761
https://blog.csdn.net/u011762604/article/details/72897000
https://blog.csdn.net/mm_bit/article/details/49474709
https://blog.csdn.net/lglglgl/article/details/80553828
https://blog.csdn.net/l1028386804/article/details/51538611