指令重排 & 内存屏障 & 可见性 & volatile & happen before:
https://www.cnblogs.com/amei0/p/8378625.html
秋招准备篇(1)—面经积累




1.Java的集合类用过哪些?
答:
用过,比较常用的有ArrayList,LinkedList.HashMap等2.那他们有什么区别呢?
区别:
ArrayList:它是实现了List接口的,它的底层实现是数组的,它通常会设置一个初始容量,默认是10,如果在要加入一个元素的时候,大于这个初始容量的话,就会进行扩容操作,会编程初始容量的1.5倍。它的
LinkedList:它是实现List接口的,他的底层实现是双向链表的,比较适合插入删除
在进行list遍历时,如果是对ArrayList进行遍历,推荐使用下标方式,如果是LinkedList则推荐使用迭代器方式。
ArrayList比较适合查询,LinkedList的查询效率低,但是插入删除效率高。
HashMap:它是实现Map接口的,HashMap中的值的形式是键对值的,它的底层实现是数组+链表的。3.ArrayList是线程安全的吗?
不是,ArrayList在进行add操作的时候, * 添加一个元素时,做了如下两步操作
* 1.判断列表的capacity容量是否足够,是否需要扩容
* 2.真正将元素放在列表的元素数组里面
会先进行size+1以后再进行判断需不需要扩容,比如现在有两个线程,
由此看到add元素时,实际做了两个大的步骤:
判断elementData数组容量是否满足需求
在elementData对应位置上设置值
这样也就出现了第一个导致线程不安全的隐患,在多个线程进行add操作时可能会导致elementData数组越界。具体逻辑如下:
列表大小为9,即size=9
线程A开始进入add方法,这时它获取到size的值为9,调用ensureCapacityInternal方法进行容量判断。
线程B此时也进入add方法,它获取到size的值也为9,也开始调用ensureCapacityInternal方法。
线程A发现需求大小为10,而elementData的大小就为10,可以容纳。于是它不再扩容,返回。
线程B也发现需求大小为10,也可以容纳,返回。
线程A开始进行设置值操作, elementData[size++] = e 操作。此时size变为10。
线程B也开始进行设置值操作,它尝试设置elementData[10] = e,而elementData没有进行过扩容,它的下标最大为9。于是此时会报出一个数组越界的异常ArrayIndexOutOfBoundsException.
另外第二步 elementData[size++] = e 设置值的操作同样会导致线程不安全。从这儿可以看出,这步操作也不是一个原子操作,它由如下两步操作构成:
elementData[size] = e;
size = size + 1;
在单线程执行这两条代码时没有任何问题,但是当多线程环境下执行时,可能就会发生一个线程的值覆盖另一个线程添加的值,具体逻辑如下:
列表大小为0,即size=0
线程A开始添加一个元素,值为A。此时它执行第一条操作,将A放在了elementData下标为0的位置上。
接着线程B刚好也要开始添加一个值为B的元素,且走到了第一步操作。此时线程B获取到size的值依然为0,于是它将B也放在了elementData下标为0的位置上。
线程A开始将size的值增加为1
线程B开始将size的值增加为2
这样线程AB执行完毕后,理想中情况为size为2,elementData下标0的位置为A,下标1的位置为B。而实际情况变成了size为2,elementData下标为0的位置变成了B,下标1的位置上什么都没有。并且后续除非使用set方法修改此位置的值,否则将一直为null,因为size为2,添加元素时会从下标为2的位置上开始。4.知道CopyOnWriteArray吗?
CopyOnWriteArray是实现了List接口的,位于java.util.concurrent并发包之下的。
实现了List接口
内部持有一个ReentrantLock lock = new ReentrantLock();
底层是用volatile transient声明的数组 array
读写分离,写时复制出一个新的数组,完成插入、修改或者移除操作后将新数组赋值给array
为什么增删改中都需要创建一个新的数组,操作完成之后再赋给原来的引用?这是为了保证get的时候都能获取到元素,如果在增删改过程直接修改原来的数组,可能会造成执行读操作获取不到数据。
增加一个元素的过程:
1.先获得ReentrantLock锁
2.复制新数组
3.对新数组进行操作
4.把新数组赋给原来的引用。
5.释放锁
比较适合读多写少的场景。
读元素get()
public E get(int index) {
return get(getArray(), index);
}
final Object[] getArray() {
return array;
}
set()方法也很简单,两个要点:
通过锁lock保护队列修改过程
在副本上修改,最后替换array引用
按照独占锁的思路,仅仅给写线程加锁是不行的,会有读、写线程的竞争问题。但是get()中明明没有加锁,为什么也没有问题呢?
通过加锁,保证同一时间最多只有一个写线程W1进入try block;假设要设置的值与旧值不同。9-10行首先将数据复制一份(此时,没有其他写线程能进入try block修改集合),11行在副本上修改相应元素,12行修改array引用。array是volatile变量,所以写的最新值对其他读线程、写线程都是可见的。
设计的思想
用并发访问“数组副本的引用”代替并发访问“数组元素的引用”,大大降低了维护线程安全的难度。
当前副本可能是失效的,但一定是集合在某一瞬间的快照(一定程度上满足不变性),满足弱一致性。5.CopyOnWriteArrayList为什么并发安全且性能比Vector好
Vector是增删改查方法都加了synchronized,保证同步,但是每个方法执行的时候都要去获得锁,性能就会大大下降,而CopyOnWriteArrayList 只是在增删改上加锁,但是读不加锁,在读方面的性能就好于Vector,CopyOnWriteArrayList支持读多写少的并发情况。
6.ConcurrentHashMap了解吗????????
http://www.importnew.com/28263.html
1.7版本
ConcurrentHashMap是java.util.Concurrent下的一个类,它是线程安全的,比Hashtable要好,因为HashTable虽然也是线程安全的,但是它是对整一个table进行加锁(利用了sybchronized对方法进行修饰)保证同一时间只能一个线程对它进行操作。
ConcurrentHashMap 利用了分段锁,Segment 通过继承 ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个 segment,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全。
concurrencyLevel:并发数,默认是16(也就是说segment有16个)所以理论上,这个时候,最多可以同时支持 16 个线程并发写,只要它们的操作分别分布在不同的 Segment 上。这个值可以在初始化的时候设置为其他值,但是一旦初始化以后,它是不可以扩容的。
初始化
initialCapacity:初始容量,这个值指的是整个 ConcurrentHashMap 的初始容量,实际操作的时候需要平均分给每个 Segment。
loadFactor:负载因子,之前我们说了,Segment 数组不可以扩容,所以这个负载因子是给每个 Segment 内部使用的。
new ConcurrentHashMap() 无参构造函数进行初始化的,那么初始化完成后:
Segment 数组长度为 16,不可以扩容
Segment[i] 的默认大小为 2,负载因子是 0.75,得出初始阈值为 1.5,也就是以后插入第一个元素不会触发扩容,插入第二个会进行第一次扩容
这里初始化了 segment[0],其他位置还是 null,至于为什么要初始化 segment[0],后面的代码会介绍
当前 segmentShift 的值为 32 – 4 = 28,segmentMask 为 16 – 1 = 15,姑且把它们简单翻译为移位数和掩码,这两个值马上就会用到。
segmentShift segmentMask是用于查找在哪一个segment中的
初始化操作中,初始化了segment[0],别的要在第一次插入数据的时候才初始化,为什么要先初始化segmen[0]呢?因为之后在初始化别的segment的时候要利用到segment[0]的数组长度和负载因子。
put操作:
1.先根据hash(key)和segmentShift segmentMask找到位于那个segment中
2.如果是第一次插入这个segment中需要先初始化。初始化的时候,保证并发的操作是使用了CAS,如果有一个线程成功初始化就退出。
3.再找到在内部数组的哪个位置,(利用的hash&(tab.length-1))
4.判断这这个位置是已有链表还是为空
已有链表:就继续沿着链表看一下有没有key相同的,有的话就新值覆盖旧值
为空:判断要插入的是空还是不为空:为空就初始化,不为空就插在链表头部,判断是否需要扩容,需要扩容的话,先扩容再插入值。
扩容操作:是已经获得锁的情况下了
1.扩容为原来初始容量的2倍,如果在原来数组的位置是i,就把链表拆了,放在新数组i或者i+原来数组初始容量的位置。
put 操作的线程安全性。
初始化槽,这个我们之前就说过了,使用了 CAS 来初始化 Segment 中的数组。
添加节点到链表的操作是插入到表头的,所以,如果这个时候 get 操作在链表遍历的过程已经到了中间,是不会影响的。当然,另一个并发问题就是 get 操作在 put 之后,需要保证刚刚插入表头的节点被读取,这个依赖于 setEntryAt 方法中使用的 UNSAFE.putOrderedObject。
扩容。扩容是新创建了数组,然后进行迁移数据,最后面将 newTable 设置给属性 table。所以,如果 get 操作此时也在进行,那么也没关系,如果 get 先行,那么就是在旧的 table 上做查询操作;而 put 先行,那么 put 操作的可见性保证就是 table 使用了 volatile 关键字。
remove 操作的线程安全性。
get 操作需要遍历链表,但是 remove 操作会”破坏”链表。
如果 remove 破坏的节点 get 操作已经过去了,那么这里不存在任何问题。
如果 remove 先破坏了一个节点,分两种情况考虑。 1、如果此节点是头结点,那么需要将头结点的 next 设置为数组该位置的元素,table 虽然使用了 volatile 修饰,但是 volatile 并不能提供数组内部操作的可见性保证,所以源码中使用了 UNSAFE 来操作数组,请看方法 setEntryAt。2、如果要删除的节点不是头结点,它会将要删除节点的后继节点接到前驱节点中,这里的并发保证就是 next 属性是 volatile 的。

1.8
并发环境下为什么使用ConcurrentHashMap
1. HashMap在高并发的环境下,执行put操作会导致HashMap的Entry链表形成环形数据结构,从而导致Entry的next节点始终不为空,因此产生死循环获取Entry
2. HashTable虽然是线程安全的,但是效率低下,当一个线程访问HashTable的同步方法时,其他线程如果也访问HashTable的同步方法,那么会进入阻塞或者轮训状态。
3. 在jdk1.7中ConcurrentHashMap使用锁分段技术提高并发访问效率。首先将数据分成一段一段地存储,然后给每一段数据配一个锁,当一个线程占用锁访问其中一段数据时,其他段的数据也能被其他线程访问。然而在jdk1.8中的实现已经抛弃了Segment分段锁机制,利用CAS+Synchronized来保证并发更新的安全,底层依然采用数组+链表+红黑树的存储结构。
在jdk1.8中主要做了2方面的改进
改进一:取消segments字段,直接采用transient volatile HashEntry<K,V>[] table保存数据,采用table数组元素作为锁,从而实现了对每一行数据进行加锁,进一步减少并发冲突的概率。
改进二:将原先table数组+单向链表的数据结构,变更为table数组+单向链表+红黑树的结构。对于hash表来说,最核心的能力在于将key hash之后能均匀的分布在数组中。如果hash之后散列的很均匀,那么table数组中的每个队列长度主要为0或者1。但实际情况并非总是如此理想,虽然ConcurrentHashMap类默认的加载因子为0.75,但是在数据量过大或者运气不佳的情况下,还是会存在一些队列长度过长的情况,如果还是采用单向列表方式,那么查询某个节点的时间复杂度为O(n);因此,对于个数超过8(默认值)的列表,jdk1.8中采用了红黑树的结构,那么查询的时间复杂度可以降低到O(logN),可以改进性能。
7.线程池用过吗?原理?参考:线程池原理解析 很好
线程池的好处:
线程池主要用来解决线程生命周期开销问题和资源不足问题。通过对多个任务重用线程,线程创建的开销就被分摊到了多个任务上了,而且由于在请求到达时线程已经存在,所以消除了线程创建所带来的延迟。这样,就可以立即为请求服务,使应用程序响应更快。另外,通过适当地调整线程池中的线程数目可以防止出现资源不足的情况。
线程池的执行过程:
1。如果当前线程池中的线程数目小于corePoolSize,则每来一个任务,就会创建一个线程去执行这个任务;
2.如果当前线程池中的线程数目>=corePoolSize,则每来一个任务,会尝试将其添加到任务缓存队列当中,若3.添加成功,则该任务会等待空闲线程将其取出去执行;若添加失败(一般来说是任务缓存队列已满),则会尝试创建新的线程去执行这个任务;
4.如果当前线程池中的线程数目达到maximumPoolSize,则会采取任务拒绝策略进行处理;
5.如果线程池中的线程数量大于 corePoolSize时,如果某线程空闲时间超过keepAliveTime,线程将被终止,直至线程池中的线程数目不大于corePoolSize;如果允许为核心池中的线程设置存活时间,那么核心池中的线程空闲时间超过keepAliveTime,线程也会被终止。
在jdk中这里有一个非常巧妙的设计方式,假如我们来设计线程池,可能会有一个任务分派线程,当发现有线程空闲时,就从任务缓存队列中取一个任务交给空闲线程执行。但是在这里,并没有采用这样的方式,因为这样会要额外地对任务分派线程进行管理,无形地会增加难度和复杂度,这里直接让执行完任务的线程去任务缓存队列里面取任务来执行
线程池的源码解析:
构造函数:
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler);即使还有别的构造函数,但是它们实际上也是调用这一个构造函数的。
参数解释:
1.corePoolSize 核心池的大小 在创建了线程池后,默认情况下,线程池中并没有任何线程,而是等待有任务到来才创建线程去执行任务,除非调用了prestartAllCoreThreads()或者prestartCoreThread()方法,从这2个方法的名字就可以看出,是预创建线程的意思,即在没有任务到来之前就创建corePoolSize个线程或者一个线程。默认情况下,在创建了线程池后,线程池中的线程数为0,当有任务来之后,就会创建一个线程去执行任务,当线程池中的线程数目达到corePoolSize后,就会把到达的任务放到缓存队列当中;
2.maximumPoolSize 线程池的大小
3.keepAliveTime 表示线程没有任务执行时最多保持多久时间会终止。默认情况下,只有当线程池中的线程数大于corePoolSize时,keepAliveTime才会起作用,直到线程池中的线程数不大于corePoolSize,即当线程池中的线程数大于corePoolSize时,如果一个线程空闲的时间达到keepAliveTime,则会终止,直到线程池中的线程数不超过corePoolSize。但是如果调用了allowCoreThreadTimeOut(boolean)方法,在线程池中的线程数不大于corePoolSize时,keepAliveTime参数也会起作用,直到线程池中的线程数为0;
4.workQueue 任务缓冲队列
一个阻塞队列,用来存储等待执行的任务,这个参数的选择也很重要,会对线程池的运行过程产生重大影响,一般来说,这里的阻塞队列有以下几种选择:
ArrayBlockingQueue;
LinkedBlockingQueue;
SynchronousQueue;
ArrayBlockingQueue和PriorityBlockingQueue使用较少,一般使用LinkedBlockingQueue和Synchronous。线程池的排队策略与BlockingQueue有关。
5.threadFactory 用来创建线程的线程工厂
6.handler 表示当拒绝处理任务时的策略,有以下四种取值:
ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。
ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常。
ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程)
ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务
Executor是一个顶层接口,在它里面只声明了一个方法execute(Runnable),返回值为void,参数为Runnable类型,从字面意思可以理解,就是用来执行传进去的任务的;
然后ExecutorService接口继承了Executor接口,并声明了一些方法:submit、invokeAll、invokeAny以及shutDown等;
抽象类AbstractExecutorService实现了ExecutorService接口,基本实现了ExecutorService中声明的所有方法;
然后ThreadPoolExecutor继承了类AbstractExecutorService。
在ThreadPoolExecutor类中有几个非常重要的方法:
execute()
submit()
shutdown()
shutdownNow()
execute()方法实际上是Executor中声明的方法,在ThreadPoolExecutor进行了具体的实现,这个方法是ThreadPoolExecutor的核心方法,通过这个方法可以向线程池提交一个任务,交由线程池去执行。
submit()方法是在ExecutorService中声明的方法,在AbstractExecutorService就已经有了具体的实现,在ThreadPoolExecutor中并没有对其进行重写,这个方法也是用来向线程池提交任务的,但是它和execute()方法不同,它能够返回任务执行的结果,去看submit()方法的实现,会发现它实际上还是调用的execute()方法,只不过它利用了Future来获取任务执行结果(Future相关内容将在下一篇讲述)。
shutdown()和shutdownNow()是用来关闭线程池的。
unState表示当前线程池的状态,它是一个volatile变量用来保证线程之间的可见性;
下面的几个static final变量表示runState可能的几个取值。
当创建线程池后,初始时,线程池处于RUNNING状态;
如果调用了shutdown()方法,则线程池处于SHUTDOWN状态,此时线程池不能够接受新的任务,它会等待所有任务执行完毕;
如果调用了shutdownNow()方法,则线程池处于STOP状态,此时线程池不能接受新的任务,并且会去尝试终止正在执行的任务;
当线程池处于SHUTDOWN或STOP状态,并且所有工作线程已经销毁,任务缓存队列已经清空或执行结束后,线程池被设置为TERMINATED状态。线程池的种类
使用线程池需要注意的地方
① 合理设置线程池的核心数量大小;
② 不要对那些同步等待其他任务结果的任务排队,以免引起死锁;
③ 在为时间可能很长的操作使用合用的线程时要小心,避免阻塞其他线程。
newCachedThreadPool:
底层:返回ThreadPoolExecutor实例,corePoolSize为0;maximumPoolSize为Integer.MAX_VALUE;keepAliveTime为60L;unit为TimeUnit.SECONDS;workQueue为SynchronousQueue(同步队列)
通俗:当有新任务到来,则插入到SynchronousQueue中,由于SynchronousQueue是同步队列,因此会在池中寻找可用线程来执行,若有可以线程则执行,若没有可用线程则创建一个线程来执行该任务;若池中线程空闲时间超过指定大小,则该线程会被销毁。
适用:执行很多短期异步的小程序或者负载较轻的服务器
newFixedThreadPool:
底层:返回ThreadPoolExecutor实例,接收参数为所设定线程数量nThread,corePoolSize为nThread,maximumPoolSize为nThread;keepAliveTime为0L(不限时);unit为:TimeUnit.MILLISECONDS;WorkQueue为:new LinkedBlockingQueue<Runnable>() 无解阻塞队列
通俗:创建可容纳固定数量线程的池子,每隔线程的存活时间是无限的,当池子满了就不在添加线程了;如果池中的所有线程均在繁忙状态,对于新任务会进入阻塞队列中(无界的阻塞队列)
适用:执行长期的任务,性能好很多
newSingleThreadExecutor:
底层:FinalizableDelegatedExecutorService包装的ThreadPoolExecutor实例,corePoolSize为1;maximumPoolSize为1;keepAliveTime为0L;unit为:TimeUnit.MILLISECONDS;workQueue为:new LinkedBlockingQueue<Runnable>() 无解阻塞队列
通俗:创建只有一个线程的线程池,且线程的存活时间是无限的;当该线程正繁忙时,对于新任务会进入阻塞队列中(无界的阻塞队列)
适用:一个任务一个任务执行的场景
NewScheduledThreadPool:
底层:创建ScheduledThreadPoolExecutor实例,corePoolSize为传递来的参数,maximumPoolSize为Integer.MAX_VALUE;keepAliveTime为0;unit为:TimeUnit.NANOSECONDS;workQueue为:new DelayedWorkQueue() 一个按超时时间升序排序的队列
通俗:创建一个固定大小的线程池,线程池内线程存活时间无限制,线程池可以支持定时及周期性任务执行,如果所有线程均处于繁忙状态,对于新任务会进入DelayedWorkQueue队列中,这是一种按照超时时间排序的队列结构
适用:周期性执行任务的场景
线程池任务执行流程:
当线程池小于corePoolSize时,新提交任务将创建一个新线程执行任务,即使此时线程池中存在空闲线程。
当线程池达到corePoolSize时,新提交任务将被放入workQueue中,等待线程池中任务调度执行
当workQueue已满,且maximumPoolSize>corePoolSize时,新提交任务会创建新线程执行任务
当提交任务数超过maximumPoolSize时,新提交任务由RejectedExecutionHandler处理
当线程池中超过corePoolSize线程,空闲时间达到keepAliveTime时,关闭空闲线程
当设置allowCoreThreadTimeOut(true)时,线程池中corePoolSize线程空闲时间达到keepAliveTime也将关闭
备注:
一般如果线程池任务队列采用LinkedBlockingQueue队列的话,那么不会拒绝任何任务(因为队列大小没有限制),这种情况下,ThreadPoolExecutor最多仅会按照最小线程数来创建线程,也就是说线程池大小被忽略了。
如果线程池任务队列采用ArrayBlockingQueue队列的话,那么ThreadPoolExecutor将会采取一个非常负责的算法,比如假定线程池的最小线程数为4,最大为8所用的ArrayBlockingQueue最大为10。随着任务到达并被放到队列中,线程池中最多运行4个线程(即最小线程数)。即使队列完全填满,也就是说有10个处于等待状态的任务,ThreadPoolExecutor也只会利用4个线程。如果队列已满,而又有新任务进来,此时才会启动一个新线程,这里不会因为队列已满而拒接该任务,相反会启动一个新线程。新线程会运行队列中的第一个任务,为新来的任务腾出空间。
这个算法背后的理念是:该池大部分时间仅使用核心线程(4个),即使有适量的任务在队列中等待运行。这时线程池就可以用作节流阀。如果挤压的请求变得非常多,这时该池就会尝试运行更多的线程来清理;这时第二个节流阀—最大线程数就起作用了。8.Mysql用过吗?说一下mysql的隔离级别
用过
事务指的是一个用户定义的一个数据库操作序列,这些操作要么全做,要么就全不做,是一个不可分割的工作单位。
事务的并发问题
1、脏读:事务A读取了事务B更新的数据,然后B回滚操作,那么A读取到的数据是脏数据
2、不可重复读:事务 A 多次读取同一数据,事务 B 在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果 不一致。
3、幻读:系统管理员A将数据库中所有学生的成绩从具体分数改为ABCDE等级,但是系统管理员B就在这个时候插入了一条具体分数的记录,当系统管理员A改结束后发现还有一条记录没有改过来,就好像发生了幻觉一样,这就叫幻读。
小结:不可重复读的和幻读很容易混淆,不可重复读侧重于修改,幻读侧重于新增或删除。解决不可重复读的问题只需锁住满足条件的行,解决幻读需要锁表
mysql的事务隔离级别有:
1.可串行性,能够避免幻读,脏读,不可重复读的问题
2.可重复读 能够避免脏读,不可重复读的问题
3.读已提交 能够避免脏读的问题
4。读未提交 什么都不能避免
mysql默认的隔离级别是可重复读
oracle默认的隔离级别是读已提交
mysql的可重复读的隔离级别解决了 "不可重复读" 和 “幻读” 2个问题补充:
1、事务隔离级别为读提交时,写数据只会锁住相应的行
2、事务隔离级别为可重复读时,如果检索条件有索引(包括主键索引)的时候,默认加锁方式是next-key 锁;如果检索条件没有索引,更新数据时会锁住整张表。一个间隙被事务加了锁,其他事务是不能在这个间隙插入记录的,这样可以防止幻读。
3、事务隔离级别为串行化时,读写数据都会锁住整张表
4、隔离级别越高,越能保证数据的完整性和一致性,但是对并发性能的影响也越大。9.Mysql的MVCC机制
MVCC是一种多版本并发控制机制。
MVCC是为了解决什么问题?
大多数的MYSQL事务型存储引擎,如,InnoDB,Falcon以及PBXT都不使用一种简单的行锁机制.事实上,他们都和MVCC–多版本并发控制来一起使用.
大家都应该知道,锁机制可以控制并发操作,但是其系统开销较大,而MVCC可以在大多数情况下代替行级锁,使用MVCC,能降低其系统开销.
MVCC实现
MVCC是通过保存数据在某个时间点的快照来实现的. 不同存储引擎的MVCC. 不同存储引擎的MVCC实现是不同的,典型的有乐观并发控制和悲观并发控制.
1., InnoDB用MVCC来实现非阻塞的读操作,不同隔离级别下,MVCC通过读取不同版本的数据来解决"不可重复读" 的问题.
2, InnoDB的默认隔离级别解决2个问题,"不可重复读" 和 "幻读", oracle需要在串行读中解决"幻读"问题. InnoDB的实现方式和一般隔离级别的定义不一致.
3, InnoDB的默认隔离级别采用Next-key Lock(间隙锁) 来解决幻读问题. 而 read committed隔离级别采用Record锁,因此会产生"幻读"问题.
4, InnoDB的存储引擎不存在锁升级的问题(太多的行锁升级为表锁),来降低锁的开销. 因为不是根据记录来产生行锁的,根据页对锁进行管理.9.mysql中的锁?
ySQL的锁机制比较简单,其最显著的特点是不同的存储引擎支持不同的锁机制。比如,MyISAM和MEMORY存储引擎采用的是表级锁(table-level locking);BDB存储引擎采用的是页面锁(page-level locking),但也支持表级锁;InnoDB存储引擎既支持行级锁(row-level locking),也支持表级锁,但默认情况下是采用行级锁。
MySQL这3种锁的特性可大致归纳如下。
开销、加锁速度、死锁、粒度、并发性能
表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。
行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
页面锁:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般
对MyISAM表的读操作,不会阻塞其他用户对同一表的读请求,但会阻塞对同一表的写请求;对 MyISAM表的写操作,则会阻塞其他用户对同一表的读和写操作;MyISAM表的读操作与写操作之间,以及写操作之间是串行的!
在用LOCK TABLES给表显式加表锁时,必须同时取得所有涉及到表的锁,并且MySQL不支持锁升级。也就是说,在执行LOCK TABLES后,只能访问显式加锁的这些表,不能访问未加锁的表;同时,如果加的是读锁,那么只能执行查询操作,而不能执行更新操作。其实,在自动加锁的情况下也基本如此,MyISAM总是一次获得SQL语句所需要的全部锁。这也正是MyISAM表不会出现死锁(Deadlock Free)的原因。
并发插入(Concurrent Inserts)
上文提到过MyISAM表的读和写是串行的,但这是就总体而言的。在一定条件下,MyISAM表也支持查询和插入操作的并发进行。
MyISAM存储引擎有一个系统变量concurrent_insert,专门用以控制其并发插入的行为,其值分别可以为0、1或2。
当concurrent_insert设置为0时,不允许并发插入。
当concurrent_insert设置为1时,如果MyISAM表中没有空洞(即表的中间没有被删除的行),MyISAM允许在一个进程读表的同时,另一个进程从表尾插入记录。这也是MySQL的默认设置。
当concurrent_insert设置为2时,无论MyISAM表中有没有空洞,都允许在表尾并发插入记录。
行锁
InnoDB实现了以下两种类型的行锁。
共享锁(S):允许一个事务去读一行,阻止其他事务获得相同数据集的排他锁。
排他锁(X):允许获得排他锁的事务更新数据,阻止其他事务取得相同数据集的共享读锁和排他写锁。另外,为了允许行锁和表锁共存,实现多粒度锁机制,InnoDB还有两种内部使用的意向锁(Intention Locks),这两种意向锁都是表锁。
意向共享锁(IS):事务打算给数据行加行共享锁,事务在给一个数据行加共享锁前必须先取得该表的IS锁。
意向排他锁(IX):事务打算给数据行加行排他锁,事务在给一个数据行加排他锁前必须先取得该表的IX锁。
InnoDB行锁是通过给索引上的索引项加锁来实现的,这一点MySQL与Oracle不同,后者是通过在数据块中对相应数据行加锁来实现的。InnoDB这种行锁实现特点意味着:只有通过索引条件检索数据,InnoDB才使用行级锁,否则,InnoDB将使用表锁!
间隙锁:Next-Key锁)
当我们用范围条件而不是相等条件检索数据,并请求共享或排他锁时,InnoDB会给符合条件的已有数据记录的索引项加锁;对于键值在条件范围内但并不存在的记录,叫做“间隙(GAP)”,InnoDB也会对这个“间隙”加锁,这种锁机制就是所谓的间隙锁(Next-Key锁)。InnoDB除了通过范围条件加锁时使用间隙锁外,如果使用相等条件请求给一个不存在的记录加锁,InnoDB也会使用间隙锁!
InnoDB使用间隙锁的目的,一方面是为了防止幻读,以满足相关隔离级别的要求,对于上面的例子,要是不使用间隙锁,如果其他事务插入了empid大于100的任何记录,那么本事务如果再次执行上述语句,就会发生幻读;另外一方面,是为了满足其恢复和复制的需要。
9.怎么优化sql?
1.避免使用临时表
(1)除非却有需要,否则应尽量避免使用临时表,相反,可以使用表变量代替;
(2)大多数时候(99%),表变量驻扎在内存中,因此速度比临时表更快,临时表驻扎在TempDb数据库中,因此临时表上的操作需要跨数据库通信,速度自然慢。
可以使用联合(UNION)来代替手动创建的临时表
2.避免使用了索引,但是却出现索引无效的情况
什么情况下设置了索引但无法使用,索引无效
1) 以”%”开头的LIKE语句,模糊匹配:红色标识位置的百分号会导致相关列的索引无法使用
2) Or语句前后没有同时使用索引
3) 数据类型出现隐式转化(如varchar不加单引号的话可能会自动转换为int型,会使索引无效,产生全表扫描。)
4) 在索引列上使用IS NULL 或IS NOT NULL操作。索引是不索引空值的,所以这样的操作不能使用索引,可以用其他的办法处理,例如:数字类型,判断大于0,字符串类型设置一个默认值,判断是否等于默认值即可
5) 在索引字段上使用not,<>,!=,eg<> 操作符(不等于):不等于操作符是永远不会用到索引的,因此对它的处理只会产生全表扫描。 用其它相同功能的操作运算代替,如 a<>0 改为 a>0 or a<0
6) 对索引字段进行计算操作
7) 在索引字段上使用函数
3.避免在WHERE子句中使用in,not in,or或者having。
可以使用exist和not exist代替in和not in。
4.where子句中的连接顺序(where也采用从右往左解析)
当使用where子句连接的时候,要将可以过滤掉最大数量记录的条件写在WHERE子句的最右
5..删除所有记录都得时候,用TRUNCATE替代DELETE
因为delete删除表时,会扫描整个表,然后再一条一条删除
而TRUNCATE table user; 是一次性删除整个表的所有内容,会提高效率。
6.表名过长时,尽量使用表的别名
例如 salgrade s 长表名更加的耗费扫描时间10,spring循环依赖是怎么解决的?
循环依赖就是循环引用,就是两个或多个Bean相互之间的持有对方,比如CircleA引用CircleB,CircleB引用CircleA,则它们最终反映为一个环。
Spring如何解决循环依赖?
假设场景如下,A->B->A
1、实例化A,并将未注入属性的A暴露出去,即提前曝光给容器Wrap
2、开始为A注入属性,发现需要B,调用getBean(B)
3、实例化B,并注入属性,发现需要A的时候,从单例缓存中查找,没找到时继而从Wrap中查找,从而完成属性的注入
4、递归完毕之后回到A的实例化过程,A将B注入成功,并注入A的其他属性值,自此即完成了循环依赖的注入
spring中的循环依赖会有3种情况:
1.构造器循环依赖
构造器的循环依赖是不可以解决的,spring容器将每一个正在创建的bean标识符放在一个当前创建bean池中,在创建的过程一直在里面,如果在创建的过程中发现已经存在这个池里面了,这时就会抛出异常表示循环依赖了。
2.setter循环依赖
对于setter的循环依赖是通过spring容器提前暴露刚完成构造器注入,但并未完成其他步骤(如setter注入)的bean来完成的,而且只能决定单例作用域的bean循环依赖,通过提前暴露一个单例工厂方法,从而使其他的bean能引用到该bean.当你依赖到了该Bean而单例缓存里面有没有该Bean的时候就会调用该工厂方法生产Bean,
Spring是先将Bean对象实例化之后再设置对象属性的
Spring先是用构造实例化Bean对象,此时Spring会将这个实例化结束的对象放到一个Map中,并且Spring提供了获取这个未设置属性的实例化对象引用的方法。
为什么不把Bean暴露出去,而是暴露个Factory呢?因为有些Bean是需要被代理的
3.prototype范围的依赖
对于“prototype”作用域bean,Spring容器无法完成依赖注入,因为“prototype”作用域的bean,Spring容器不进行缓存,因此无法提前暴露一个创建中的Bean。
11.ssh的整一个流程
用户发送一个请求,读取web.xml配置问津,加载structs2的核心控制器对用户请
求进行拦截,根据用户请求中的action,在strucs.xml配置文件中找到匹配的Action配置
,并且把已经拦截的请求发给对应的ACTION来处理。
ACTION会根据请求去调用对应的SERVICE层来处理业务逻辑,
在通过dao层来对数据库进行访问。在service层处理业务之后,
会得到对应的逻辑视图,和数据。根据返回的结果,
在structs.xml中将逻辑视图转换为物理视图。返回给用户响应。12.Mysql联合索引和最左匹配原则的题目
最左前缀匹配原则
在mysql建立联合索引时会遵循最左前缀匹配的原则,即最左优先,在检索数据时从联合索引的最左边开始匹配,示例:
对列col1、列col2和列col3建一个联合索引
KEY test_col1_col2_col3 on test(col1,col2,col3);
联合索引 test_col1_col2_col3 实际建立了(col1)、(col1,col2)、(col,col2,col3)三个索引。
SELECT * FROM test WHERE col1=“1” AND clo2=“2” AND clo4=“4”
上面这个查询语句执行时会依照最左前缀匹配原则,检索时会使用索引(col1,col2)进行数据匹配。
注意
索引的字段可以是任意顺序的,如:
SELECT * FROM test WHERE col1=“1” AND clo2=“2”
SELECT * FROM test WHERE col2=“2” AND clo1=“1”
这两个查询语句都会用到索引(col1,col2),mysql创建联合索引的规则是首先会对联合合索引的最左边的,也就是第一个字段col1的数据进行排序,在第一个字段的排序基础上,然后再对后面第二个字段col2进行排序。其实就相当于实现了类似 order by col1 col2这样一种排序规则。
有人会疑惑第二个查询语句不符合最左前缀匹配:首先可以肯定是两个查询语句都保函索引(col1,col2)中的col1、col2两个字段,只是顺序不一样,查询条件一样,最后所查询的结果肯定是一样的。既然结果是一样的,到底以何种顺序的查询方式最好呢?此时我们可以借助mysql查询优化器explain,explain会纠正sql语句该以什么样的顺序执行效率最高,最后才生成真正的执行计划。
为什么要使用联合索引
减少开销。建一个联合索引(col1,col2,col3),实际相当于建了(col1),(col1,col2),(col1,col2,col3)三个索引。每多一个索引,都会增加写操作的开销和磁盘空间的开销。对于大量数据的表,使用联合索引会大大的减少开销!
覆盖索引。对联合索引(col1,col2,col3),如果有如下的sql: select col1,col2,col3 from test where col1=1 and col2=2。那么MySQL可以直接通过遍历索引取得数据,而无需回表,这减少了很多的随机io操作。减少io操作,特别的随机io其实是dba主要的优化策略。所以,在真正的实际应用中,覆盖索引是主要的提升性能的优化手段之一。
效率高。索引列越多,通过索引筛选出的数据越少。有1000W条数据的表,有如下sql:select from table where col1=1 and col2=2 and col3=3,假设假设每个条件可以筛选出10%的数据,如果只有单值索引,那么通过该索引能筛选出1000W10%=100w条数据,然后再回表从100w条数据中找到符合col2=2 and col3= 3的数据,然后再排序,再分页;如果是联合索引,通过索引筛选出1000w10% 10% *10%=1w,效率提升可想而知!
引申
对于联合索引(col1,col2,col3),查询语句SELECT * FROM test WHERE col2=2;是否能够触发索引?
大多数人都会说NO,实际上却是YES。
EXPLAIN SELECT * FROM test WHERE col2=2;
EXPLAIN SELECT * FROM test WHERE col1=1;
观察上述两个explain结果中的type字段。查询中分别是:
•type: index
•type: ref
index:这种类型表示mysql会对整个该索引进行扫描。要想用到这种类型的索引,对这个索引并无特别要求,只要是索引,或者某个联合索引的一部分,mysql都可能会采用index类型的方式扫描。但是呢,缺点是效率不高,mysql会从索引中的第一个数据一个个的查找到最后一个数据,直到找到符合判断条件的某个索引。所以,上述语句会触发索引。
ref:这种类型表示mysql会根据特定的算法快速查找到某个符合条件的索引,而不是会对索引中每一个数据都进行一一的扫描判断,也就是所谓你平常理解的使用索引查询会更快的取出数据。而要想实现这种查找,索引却是有要求的,要实现这种能快速查找的算法,索引就要满足特定的数据结构。简单说,也就是索引字段的数据必须是有序的,才能实现这种类型的查找,才能利用到索引。
13.Linux复制文件的命令
cp命令
功能:将给出的文件或目录拷贝到另一文件或目录中,就如同DOS下的copy命令一样,功能非常强大。
语法:cp [选项] 源文件或目录 目标文件或目录
说明:该命令把指定的源文件复制到目标文件或把多个源文件复制到目标目录中。
参数:
- a 该选项通常在拷贝目录时使用。它保留链接、文件属性,并递归地拷贝目录,其作用等于dpR选项的组合。
- d 拷贝时保留链接。
- f 删除已经存在的目标文件而不提示。
- i 和f选项相反,在覆盖目标文件之前将给出提示要求用户确认。回答y时目标文件将被覆盖,是交互式拷贝。
- p 此时cp除复制源文件的内容外,还将把其修改时间和访问权限也复制到新文件中。
- r 若给出的源文件是一目录文件,此时cp将递归复制该目录下所有的子目录和文件。此时目标文件必须为一个目录名。
- l 不作拷贝,只是链接文件。
需要说明的是,为防止用户在不经意的情况下用cp命令破坏另一个文件,如用户指定的目标文件名是一个已存在的文件名,用cp命令拷贝文件后,这个文件就会被新拷贝的源文件覆盖,因此,建议用户在使用cp命令拷贝文件时,最好使用i选项。
$ cp - i exam1.c /usr/wang/shiyan1.c
该命令将文件exam1.c拷贝到/usr/wang 这个目录下,并改名为 shiyan1.c。若不希望重新命名,可以使用下面的命令:
$ cp exam1.c /usr/ wang/
$ cp - r /usr/xu/ /usr/liu/ 将/usr/xu目录中的所有文件及其子目录拷贝到目录/usr/liu中。
14.数据库的范式
第一范式(1NF):数据表中的每一列(每个字段)必须是不可拆分的最小单元,也就是确保每一列的原子性;
第二范式(2NF):满足1NF后,要求表中的所有列,都必须依赖于主键,而不能有任何一列与主键没有关系,也就是说一个表只描述一件事情;
数据冗余 更新异常: 删除异常 :
第三范式(3NF):必须先满足第二范式(2NF),要求:表中的每一列只与主键直接相关而不是间接相关,(表中的每一列只能依赖于主键);
它也会存在数据冗余、更新异常、插入异常和删除异常的情况。
巴斯-科德范式(BCNF):
在3NF基础上,任何非主属性不能对主键子集依赖(在3NF基础上消除对主码子集的依赖)
15.B树和B+树的区别
B树 B+树
1.结构方面,B树每个节点都存储key和data,所有节点组成这棵树,并且叶子节点指针为null
B+树只有叶子节点存储data,叶子节点包含了这棵树的所有键值,B+树上增加了顺序访问指针,也就是每个叶子节点增加一个指向相邻叶子节点的指针,这样一棵树成了数据库系统实现索引的首选数据结构。
2.B树只支持随机查询,B+树支持随机查询和顺序查询
3.由于B树中的内部节点存储值,但是B+树中的内部结点没有,所以b+树相对而言的I/O读写消耗的资源要少一些
4.B树相对二叉树虽然提高了磁盘IO性能,但并没有解决遍历元素效率低下的问题。但是B+树的顺序访问指针解决了遍历元素这个问题。
为什么B+树更适合做索引的数据结构呢?
1.B+树磁盘读写代价更低
B+的内部结点并没有指向关键字具体信息的指针,即内部节点不存储数据。因此其内部结点相对B 树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
2.B+tree的查询效率更加稳定
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
16.数据结构
数据结构:是指相互之间存在一种或多种特定关系的数据元素的集合
数组
数组是最最基本的数据结构,很多语言都内置支持数组。数组是使用一块连续的内存空间保存数据,保存的数据的个数在分配内存的时候就是确定的:
访问数组中第 n 个数据的时间花费是 O(1) 但是要在数组中查找一个指定的数据则是 O(N)。当向数组中插入或者删除数据的时候,最好的情况是在数组的末尾进行操作,时间复杂度是O(1) ,但是最坏情况是插入或者删除第一个数据,时间复杂度是 O(N) 。在数组的任意位置插入或者删除数据的时候,后面的数据全部需要移动,移动的数据还是和数据个数有关所以总体的时间复杂度仍然是 O(N) 。
链表
链表是在非连续的内存单元中保存数据,并且通过指针将各个内存单元链接在一起,最有一个节点的指针指向 NULL 。链表不需要提前分配固定大小存储空间,当需要存储数据的时候分配一块内存并将这块内存插入链表中。
在链表中查找第 n 个数据以及查找指定的数据的时间复杂度是 O(N) ,但是插入和删除数据的时间复杂度是 O(1) ,因为只需要调整指针就可以:
堆栈
堆栈实现了一种后进先出的语义 (LIFO) 。可以使用数组或者是链表来实现它:
队列
队列实现了先入先出的语义 (FIFO) 。队列也可以使用数组和链表来实现:
队列只允许在队尾添加数据,在队头删除数据。但是可以查看队头和队尾的数据。还有一种是双端队列,在两端都可以插入和删除:
树
定义:树是由根结点和若干颗子树构成的。树是由一个集合以及在该集合上定义的一种关系构成的。集合中的元素称为树的结点,所定义的关系称为父子关系。父子关系在树的结点之间建立了一个层次结构。在这种层次结构中有一个结点具有特殊的地位,这个结点称为该树的根结点,或称为树根。
17.熟悉Spring,说一下ioc和aop
ioc是指的是控制反转,控制反转就是之前调用者要使用被调用对象的时候,
都要去new来生成被调用者对象,但是在spring中是由容器来生成被调用者的,
然后再注入给调用者的。控制反转的底层实现是根据java中的反射还有工厂模式来实现的。
IoC看作是一个大工厂,只不过这个大工厂里要生成的对象都是在XML文件中给出定义的,
然后利用Java 的“反射”编程,根据XML中给出的类名生成相应的对象。
从实现来看,IoC是把以前在工厂方法里写死的对象生成代码,改变为由XML文件来定义,
也就是把工厂和对象生成这两者独立分隔开来,目的就是提高灵活性和可维护性。
反射可以实现根据运行时动态的加载类,调用方法等。
AOP是指的spring中的面向切面编程,就是把一些系统的业务比如日志管理,
事务管理等变成横向切面,将其跟核心业务逻辑代码分开,使代码比较简洁。
等到要用到这个切面的时候,就把它织入到目标对象中成代理对象,实际上操作的是代理对象,
AOP的底层实现是动态代理,它涉及到的动态代理是由两种,JDK动态代理,
它是利用java的反射来实现的,它具有一定的局限性,一定要实现接口,
spring默认情况下是使用这种代理。还有cglib代理,它是利用的字节码增强技术,
不需要继承接口,是继承父类生成子类,是通过superclass方法生成子类,
在子类中增添新方法实现的代理。18.aop是用来干嘛的?
假如没有aop,在做日志处理的时候,我们会在每个方法中添加日志处理,比如
但大多数的日子处理代码是相同的,为了实现代码复用,我们可能把日志处理抽离成一个新的方法。但是这样我们仍然必须手动插入这些方法。
但这样两个方法就是强耦合的,假如此时我们不需要这个功能了,或者想换成其他功能,那么就必须一个个修改。
通过动态代理,可以在指定位置执行对应流程。这样就可以将一些横向的功能抽离出来形成一个独立的模块,然后在指定位置插入这些功能。这样的思想,被称为面向切面编程,亦即AOP。
切面编程,就是在你项目原有的功能基础上,通过AOP去添加新的功能,这些功能是建立在原有功能的基础上的,而且原有的功能并不知道你已经添加了新的功能。19.jvm内存分区
jvm的运行时分区:
1.程序计数器:线程独占的,唯一没有内存溢出的地方 这是一块比较小的内存,不在Ram上,而是直接划分在CPU上的,程序员无法直接操作它,它的作用是:JVM在解释字节码文件(.class)时,存储当前线程所执行的字节码的行号,只是一种概念模型,各种JVM所采用的方式不同,字节码解释器工作时,就是通过改变程序计数器的值来选取下一条要执行的指令,分支、循环、跳转、等基础功能都是依赖此技术区完成的。还有一种情况,就是我们常说的Java多线程方面的,多线程就是通过线程轮流切换而达到的,同一时刻,一个内核只能执行一个指令,所以,对于每一个程序来说,必须有一个计数器来记录程序的执行进度,这样,当现程恢复执行的时候,才能从正确的地方开始,所以,每个线程都必须有一个独立的程序计数器,这类计数器为线程私有的内存。如果一个线程正在执行一个Java方法,则计数器记录的是字节码的指令的地址,如果执行的一个Native方法,则计数器的记录为空,此内存区是唯一一个在Java规范中没任何OutOfMemoryError情况的区域。
2.方法区:存放着类信息等的内存,是线程共享的,可能会发生oom
方法区是所有线程共享的内存区域,用于存储已经被JVM加载的类信息、常量、静态变量等数据,一般来说,方法区属于持久代
运行时常量池:
3.堆:存放这new出来的对象实例和数组对象 是线程共享的,在这个区域会发生垃圾收集,可能会发生oom
4虚拟机栈:存放着方法执行的信息,每个方法都会有自己对应的方法栈帧,是线程独有的,可能会发生oom,和栈溢出
生命周期和线程一样,每个方法被执行的时候会产生一个栈帧,用于存储局部变量表、动态链接、操作数、方法出口等信息。方法的执行过程就是栈帧在JVM中出栈和入栈的过程。局部变量表中存放的是各种基本数据类型,如boolean、byte、char、等8种,及引用类型(存放的是指向各个对象的内存地址),因此,它有一个特点:内存空间可以在编译期间就确定,运行期不在改变。这个内存区域会有两种可能的Java异常:StackOverFlowError和OutOfMemoryError。
4.本地方法栈:本地方法栈就是用来处理Java中的本地方法的,Java类的祖先类Object中有众多Native方法,如hashCode()、wait()等,他们的执行很多时候是借助于操作系统,但是JVM需要对他们做一些规范,来处理他们的执行过程。此区域,可以有不同的实现方法,向我们常用的Sun的JVM就是本地方法栈和JVM虚拟机栈是同一个。
20实现原子更新操作
实现原子的更新操作
1.利用synchronize加锁
2.通过锁和cas循环来实现原子操作。
CAS 操作 compare and swap ,比较和更新,CAS的语义为:"我认为v的值应该为A,如果是,将V的值更新为B",CAS 有三个操作数,内存值V,期望值A,更新值B,当且仅当V=A 时,才实现V=B的操作。 当多线程使用CAS同时更新一个变量时,只有其中一个变量能更新变量的值,其他线程失败,失败的线程并不会被挂起,而是被告知竞争失败,并再次尝试。
通用化的实现模式:
1.首先,声明共享变量为volatile;
2.然后,使用CAS的原子条件更新来实现线程之间的同步;
3.同时,配合以volatile的读/写和CAS所具有的volatile读和写的内存语义来实现线程之间的通信。
AQS,非阻塞数据结构和原子变量类(java.util.concurrent.atomic包中的类),这些concurrent包中的基础类都是使用这种模式来实现的,而concurrent包中的高层类又是依赖于这些基础类来实现的。
21linux的常用命令 推荐看(参考来源)
1.cd命令
2.ls命令
3.grep命令
4.find命令
5.cp命令
6.mv命令
7.rm命令
8.ps命令
9.kill命令
10.killall命令
11.file命令
12.tar命令
压缩:tar -jcv -f filename.tar.bz2 要被处理的文件或目录名称
查询:tar -jtv -f filename.tar.bz2
解压:tar -jxv -f filename.tar.bz2 -C 欲解压缩的目录
注:文件名并不定要以后缀tar.bz2结尾,这里主要是为了说明使用的压缩程序为bzip2
13.cat命令
该命令用于查看文本文件的内容,后接要查看的文件名,通常可用管道与more和less一起使用,从而可以一页页地查看数据。例如:
cat text | less # 查看text文件中的内容
# 注:这条命令也可以使用less text来代替
14.chgrp命令
该命令用于改变文件所属用户组,它的使用非常简单,它的基本用法如下:
chgrp [-R] dirname/filename
-R :进行递归的持续对所有文件和子目录更改
# 例如:
chgrp users -R ./dir # 递归地把dir目录下中的所有文件和子目录下所有文件的用户组修改为users
15.chown命令
该命令用于改变文件的所有者,与chgrp命令的使用方法相同,
16.chmod命令
该命令用于改变文件的权限,一般的用法如下:
chmod [-R] xyz 文件或目录
-R:进行递归的持续更改,即连同子目录下的所有文件都会更改
同时,chmod还可以使用u(user)、g(group)、o(other)、a(all)和+(加入)、-(删除)、=(设置)跟rwx搭配来对文件的权限进行更改。
# 例如://7表示4+2+1 5表示4+0+1
chmod 0755 file # 把file的文件权限改变为-rxwr-xr-x
chmod g+w file # 向file的文件权限中加入用户组可写权限
17.vim命令
该命令主要用于文本编辑,它接一个或多个文件名作为参数,如果文件存在就打开,如果文件不存在就以该文件名创建一个文件。
18.# 把源文件test.c按照c99标准编译成可执行程序test
gcc -o test test.c -lm -std=c99
#把源文件test.c转换为相应的汇编程序源文件test.s
gcc -S test.c
19.time命令
该命令用于测算一个命令(即程序)的执行时间。它的使用非常简单,就像平时输入命令一样,不过在命令的前面加入一个time即可,例如:
time ./process
time ps aux22.ArrayList和LinkedList//之前出现过
两个不同
底层实现不同,适用场景不同,都是线程不安全的。22讲一下SpringMVC的请求流程
1.客户端发出一个HTTP请求,web应用服务器接受这个请求,如果与web.xml配置文件中的指定的DispatcherServlet请求映射路径相互匹配。那么web容器就会将该请求转给DispatcherServlet处理,
2.DispatcherServlet接受这个请求之后,根据请求的信息按照某种机制寻找恰当的映射处理器来处理这个请求
3.DispatcherServlet根据映射处理器来选择并决定将请求派送给哪个控制器。
4.控制器处理这个请求,并返回一个ModelAndView给DispatcherServlet,其中包含;视图逻辑名和模型数据信息
5.由于ModelAndView里面包含的是视图逻辑名,而不是真正的视图对象,因此DispatcherServlet需要通过viewresolver完成视图逻辑名到真实视图对象的解析功能。
6.得到真实的视图对象之后,DispatcherServlet就是要VIEW对象对 ModelAndView里面的模型数据进行渲染
7.最终客户端得到返回的响应,可能就是一个普通的html页面等形式。23.ConcurrentHashMap的优化点,性能怎么样?多读的场景怎么优化?
ConcurrentHashMap是线程安全的,使用分段锁的方式实现的,hashtable也是线程安全的,但是hashtable是对整个table进行加锁,但是ConcurrentHashMap是对segmengt进行加锁,默认情况下可以允许16个线程并发进行,所以性能得到了优化。
多读操作的优化点:
对于put操作,可以一律添加到Hash链的头部。但是对于remove操作,可能需要从中间删除一个节点,这就需要将要删除节点的前面所有节点整个复制一遍,最后一个节点指向要删除结点的下一个结点。为了确保读操作能够看到最新的值,将value设置成volatile,这避免了加锁。 remove操作要注意一个问题:如果某个读操作在删除时已经定位到了旧的链表上,那么此操作仍然将能读到数据,只不过读取到的是旧数据而已,这在多线程里面是没有问题的。
HashEntry 类的 value 域被声明为 Volatile 型,Java 的内存模型可以保证:某个写线程对 value 域的写入马上可以被后续的某个读线程“看”到。在 ConcurrentHashMap 中,不允许用 null作为键和值,当读线程读到某个 HashEntry 的 value 域的值为 null 时,便知道产生了冲突——发生了重排序现象,需要加锁后重新读入这个 value 值。这些特性互相配合,使得读线程即使在不加锁状态下,也能正确访问 ConcurrentHashMap。
在看源码实现时,对HashEntry 的 value 域的值可能为 null有些疑惑,网上都是说发生了重排序现象,后来仔细想想不完全正确,重排序发生在删除操作时,这只是其中的一个原因,尽管ConcurrentHashMap不允许将value为null的值加入,但现在仍然能够读到一个为空的value就意味着此值对当前线程还不可见,主要因为HashEntry还没有完全构造完成导致的,所以对添加和删除(对链表的结构性修改都可能会导致value为null)。24.JVM的类加载机制
jvm的类加载机制主要指的是java虚拟机将class文件加载进内存里,经过验证,准备,解析等过程,将calss文件转换成jvm能够识别的。
jvm的类加载机制主要是指类加载 验证 准备 解析 初始化这几个过程
1.类加载,主要是根据类的全限定名加载类的字节码二进制流(可以是网络或者是jar包),将类的静态存储结构转换成方法区中的运行时数据,为这个类生成java.util.class类的对象,可以通过这个实例对象找到类的信息。(反射就是在依赖这个实现的)
2.验证 验证是验证字节码二进制流中的格式是否正确,是否有着对jvm不利的结构等。
3.准备 为类变量分配内存,并将其初始化为0
4.解析 将类中的间接引用转换成直接引用
5.初始化 根据程序员的意愿初始化成员变量等
类加载机制主要是双亲委派机制
只有字节码二进制流还有类加载器都是一样的时候才说明这两个类是相同的。
类加载器有1启动类加载器 2.扩展类加载器3.系统类加载器(通常我们就是用的这个),4.自定义类加载器
双亲委派机制主要指的是某个类加载器要加载某个类的时候,首先不会选择自己去加载,而是将其交给自己的父类加载器,依次类推,只有父类加载器没有才自己去加载。
25.HashMap,解决hash冲突的方法
1.7版本 数组+链表
1.8版本 数组+链表/红黑树
利用链表和合适的加载因子和hash函数
26.static的具体用法,都可以用到哪些地方?
static修饰里面不可以有this super关键字使用,因为static表示的是类相关的,不是一定要有对象实例的。
1.static修饰变量,表示变量是全局变量,放在方法区里面,在类加载阶段的准备阶段被分配内存,初始化为0,在初始化阶段才被被初始化成为想要的值。
2.static修饰代码块,是在类加载的时候就已经加载了,只加载一次,这种代码块的执行顺序在构造函数之前,不可以人为调用的。
3.static修饰方法,静态方法可以直接由类名调用,静态方法只能使用静态变量和调用静态方法。
4.static可以用来修饰内部类,表示的是内部静态类,可以不用外部类的实例对象就可以直接调用,不是类加载的时候就加载了,而是第一次调用的时候才加载。
父类静态初始块》子类静态初始块》父类的代码块》父类的构造函数》子类的代码块》子类的构造函数
static关键字主要有以下四种使用场景:
1、修饰成员变量和成员方法
2、静态代码块
3、修饰类(只能修饰内部类)
4、静态导包(用来导入类中的静态资源,1.5之后的新特性)
修饰成员变量和成员方法(最常用)
被static修饰的成员属于类,不属于单个这个类的某个对象,被类中所有对象共享,可以并且建议通过类名调用
调用格式:
类名.静态变量名
类名.静态方法名()
用public修饰的static成员变量和成员方法可以理解为全局变量和全局方法,当声明它为类的对象时,不生成static变量的副本,而是类的所有实例共享同一个static变量。
static变量前可以有private修饰,表示这个变量只能在本类中使用,但是不能在其他类中通过类名来直接引用
静态方法中不能用this和super关键字,不能直接访问所属类的实例变量和实例方法,因为this和super是随着构造方法而出现,而静态优先于构造出现,所以静态只能访问静态,不能访问非静态,但是非静态可以访问静态。
一般在需要实现以下两个功能时推荐用static修饰:
1.表征类的属性或者被类中所有对象共享
2.方便资源调用
静态代码块:
1.静态代码块定义在类中方法外
2.静态代码块的格式是
static {
语句体;
}
3.它优先于主方法执行、优先于构造代码块执行,当以任意形式第一次使用到该类时执行
4.该类不管创建多少对象,静态代码块只执行一次
一个类中的静态代码块可以有多个,位置可以随便放,它不在任何的方法体内,JVM加载类时会执行这些静态的代码块,如果静态代码块有多个,JVM将按照它们在类中出现的先后顺序依次执行它们,每个代码块只会被执行一次。
静态代码块对于定义在它之后的静态变量,可以赋值,但是不能访问
静态内部类:
普通类是不允许声明为静态的,只有内部类才可以被static修饰的内部类可以直接作为一个普通类来使用,而不需实例一个外部类
27.抽象类和接口的区别,成员变量的问题
抽象类和接口的区别
1.他们的语法上的区别,抽象类的关键字是abstrct,是用exthend继承的,接口的相关关键字是interface是使用implemnt实现的,
抽象类中可以有抽象方法,也可以没有,abstrct不能和static, final一起用。
接口中的方法都是抽象方法,而且也可以有变量,但是都是static final修饰的。
一个类可以继承一个父类,但是可以实现多个接口
抽象类是用来捕捉子类的通用特性的 。它不能被实例化,只能被用作子类的超类。
接口是抽象方法的集合。如果一个类实现了某个接口,那么它就继承了这个接口的抽象方法。这就像契约模式,如果实现了这个接口,那么就必须确保使用这些方法。接口只是一种形式,接口自身不能做任何事情。
第一点. 接口是抽象类的变体,接口中所有的方法都是抽象的。而抽象类是声明方法的存在而不去实现它的类。
第二点. 接口可以多继承,抽象类不行
第三点. 接口定义方法,不能实现,而抽象类可以实现部分方法。
第四点. 接口中基本数据类型为static 而抽类象不是的。
当你关注一个事物的本质的时候,用抽象类;当你关注一个操作的时候,用接口。
| 参数 | 抽象类 | 接口 |
| 默认的方法实现 | 它可以有默认的方法实现 | 接口完全是抽象的。它根本不存在方法的实现 |
| 实现 | 子类使用extends关键字来继承抽象类。如果子类不是抽象类的话,它需要提供抽象类中所有声明的方法的实现。 | 子类使用关键字implements来实现接口。它需要提供接口中所有声明的方法的实现 |
| 构造器 | 抽象类可以有构造器 | 接口不能有构造器 |
| 与正常Java类的区别 | 除了你不能实例化抽象类之外,它和普通Java类没有任何区别 | 接口是完全不同的类型 |
| 访问修饰符 | 抽象方法可以有public、protected和default这些修饰符 | 接口方法默认修饰符是public。你不可以使用其它修饰符。 |
| main方法 | 抽象方法可以有main方法并且我们可以运行它 | 接口没有main方法,因此我们不能运行它。 |
| 多继承 | 抽象方法可以继承一个类和实现多个接口 | 接口只可以继承一个或多个其它接口 |
| 速度 | 它比接口速度要快 | 接口是稍微有点慢的,因为它需要时间去寻找在类中实现的方法。 |
| 添加新方法 | 如果你往抽象类中添加新的方法,你可以给它提供默认的实现。因此你不需要改变你现在的代码。 | 如果你往接口中添加方法,那么你必须改变实现该接口的类。 |
28.i++与++i的区别
i++是先读取i的值进行操作,再进行i=i+1的
++i的是先进行i=i+1,再进行读取i的值进行操作29.解释一下你对于spring的理解,spring的拦截器和filter有什么区别?
30.SpringMVC与其他框架如Struts2的区别
区别1:
Struts2 的核心是基于一个Filter即StrutsPreparedAndExcuteFilter
SpringMvc的核心是基于一个Servlet即DispatcherServlet(前端控制器)
区别2:
Struts2是基于类开发的,传递的参数是通过类的属性传递(属性驱动和模型驱动),所以只能设计成多例prototype
SpringMvc是基于类中的方法开发的,也就是一个url对应一个方法,传递参数是传到方法的形参上面,所以既可以是单例模式也可以是多例模式singiton
区别3:
Struts2采用的是值栈存储请求以及响应数据,OGNL存取数据
SpringMvc采用request来解析请求内容,然后由其内部的getParameter给方法中形参赋值,再把后台处理过的数据通过ModelAndView对象存储,Model存储数据,View存储返回的页面,再把对象通过request传输到页面去。
31.MYSQL事务的acid解释一下,mysql索引的数据结构是什么解释一下 索引推荐阅读
事务指的是用户定义的一系列数据操作,这些操作要么全做,要不就全部做
事务的acid指的是原子性,一致性,隔离性,持久性
原子性:事务中各项操作,要么全做要么全不做,任何一项操作的失败都会导致整个事务的失败;
一致性:指的是事务执行的前后的总体状态应该是保持一致的,比如转账事务,之前总额是100,那么事务执行完之后总额也应该是100. 事务结束后系统状态是一致的;
隔离性:并发的事务执行过程中是不知道别的事务的存在的,相互隔离的。并发执行的事务彼此无法看到对方的中间状态;
持久性:事务的执行结果是持久的,事务完成后所做的改动都会被持久化,即使发生灾难性的失败。通过日志和同步备份可以在故障发生后重建数据。
数据库的索引:
数据库的索引是可以加快查询速度的数据结构,它相当于目录,通过目录去查找
数据库索引的数据结构:
1.hash索引:建立若干个桶,将索引属性按照其散列函数映射到相应的桶中,桶中存放着索引属性值和相应的元组指针。
2.B树索引:将索引属性组织成B树形式,B树的内部节点存放着数据。
3.B+树索引:将索引属性组织成B+树形式,B+树的叶节点是属性值和相应的元组指针。
4.顺序文件索引:针对按指定属性值升序或者降序存储的关系,在该属性上建立一个顺序索引文件
回答的时候回答:
1.B树和B+树:
2.B树的定义
3.B+树的定义
4.为什么使用B树,B+树,而不用二分查找或者红黑树
5.为什么使用B+树作为索引比较好?而不是B+树。
先从B-Tree分析,根据B-Tree的定义,可知检索一次最多需要访问h个节点。数据库系统的设计者巧妙利用了磁盘预读原理,将一个节点的大小设为等于一个页,这样每个节点只需要一次I/O就可以完全载入。为了达到这个目的,在实际实现B-Tree还需要使用如下技巧:
每次新建节点时,直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了一个node只需一次I/O。
B-Tree中一次检索最多需要h-1次I/O(根节点常驻内存),渐进复杂度为O(h)=O(logdN)。一般实际应用中,出度d是非常大的数字,通常超过100,因此h非常小(通常不超过3)。
综上所述,用B-Tree作为索引结构效率是非常高的。
而红黑树这种结构,h明显要深的多。由于逻辑上很近的节点(父子)物理上可能很远,无法利用局部性,所以红黑树的I/O渐进复杂度也为O(h),效率明显比B-Tree差很多。
上文还说过,B+Tree更适合外存索引,原因和内节点出度d有关。从上面分析可以看到,d越大索引的性能越好,而出度的上限取决于节点内key和data的大小:
dmax = floor(pagesize / (keysize + datasize + pointsize)) (pagesize – dmax >= pointsize)
或
dmax = floor(pagesize / (keysize + datasize + pointsize)) – 1 (pagesize – dmax < pointsize)
floor表示向下取整。由于B+Tree内节点去掉了data域,因此可以拥有更大的出度,拥有更好的性能。
32.TCP的三次握手和四次握手
1.客户端主动打开,发送连接请求报文段,将SYN标识位置为1,Sequence Number置为x(TCP规定SYN=1时不能携带数据,x为随机产生的一个值),然后进入SYN_SEND状态
2.服务器收到SYN报文段进行确认,将SYN标识位置为1,ACK置为1,Sequence Number置为y,3.Acknowledgment Number置为x+1,然后进入SYN_RECV状态,这个状态被称为半连接状态
客户端再进行一次确认,将ACK置为1(此时不用SYN),Sequence Number置为x+1,Acknowledgment Number置为y+1发向服务器,最后客户端与服务器都进入ESTABLISHED状态
为什么在第3步中客户端还要再进行一次确认呢?这主要是为了防止已经失效的连接请求报文段突然又传回到服务端而产生错误的场景:
所谓"已失效的连接请求报文段"是这样产生的。正常来说,客户端发出连接请求,但因为连接请求报文丢失而未收到确认。于是客户端再次发出一次连接请求,后来收到了确认,建立了连接。数据传输完毕后,释放了连接,客户端一共发送了两个连接请求报文段,其中第一个丢失,第二个到达了服务端,没有"已失效的连接请求报文段"。
现在假定一种异常情况,即客户端发出的第一个连接请求报文段并没有丢失,只是在某些网络节点长时间滞留了,以至于延误到连接释放以后的某个时间点才到达服务端。本来这个连接请求已经失效了,但是服务端收到此失效的连接请求报文段后,就误认为这是客户端又发出了一次新的连接请求。于是服务端又向客户端发出请求报文段,同意建立连接。假定不采用三次握手,那么只要服务端发出确认,连接就建立了。
由于现在客户端并没有发出连接建立的请求,因此不会理会服务端的确认,也不会向服务端发送数据,但是服务端却以为新的传输连接已经建立了,并一直等待客户端发来数据,这样服务端的许多资源就这样白白浪费了。
采用三次握手的办法可以防止上述现象的发生。比如在上述的场景下,客户端不向服务端的发出确认请求,服务端由于收不到确认,就知道客户端并没有要求建立连接。
客户端没有数据再需要发送给服务端时,就需要释放客户端的连接,这整个过程为:
1.客户端发送一个报文给服务端(没有数据),其中FIN设置为1,Sequence Number置为u,客户端进入FIN_WAIT_1状态
2.服务端收到来自客户端的请求,发送一个ACK给客户端,Acknowledge置为u+1,同时发送Sequence Number为v,服务端年进入CLOSE_WAIT状态
3.服务端发送一个FIN给客户端,ACK置为1,Sequence置为w,Acknowledge置为u+1,用来关闭服务端到客户端的数据传送,服务端进入LAST_ACK状态
4.客户端收到FIN后,进入TIME_WAIT状态,接着发送一个ACK给服务端,Acknowledge置为w+1,Sequence Number置为u+1,最后客户端和服务端都进入CLOSED状态
为什么TCP连接的建立只需要三次握手而TCP连接的释放需要四次握手呢:
因为服务端在LISTEN状态下,收到建立请求的SYN报文后,把ACK和SYN放在一个报文里发送给客户端。而连接关闭时,当收到对方的FIN报文时,仅仅表示对方没有需要发送的数据了,但是还能接收数据,己方未必数据已经全部发送给对方了,所以己方可以立即关闭,也可以将应该发送的数据全部发送完毕后再发送FIN报文给客户端来表示同意现在关闭连接。
从这个角度而言,服务端的ACK和FIN一般都会分开发送。
33.满二叉树
一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是满二叉树
34.java的map实现有哪些?
1.hashmap
2.hashtable
3.treemap
4.concrrunthashmap35.JVM垃圾回收算法
1.可达性分析算法
2.引用计数法36.JVM如何监控内存情况 参考
jstate37.JVM运行时分区//之前出现过
38.分析快排的时间复杂度,手写归并排序
快速排序最好的时间复杂度是O(nlogn)
最坏的时间复杂度是o(n^2)一开始数据是有序的
空间复杂度是O(logn)
39.TCP建立与释放连接//之前出现过
40.线程状态之间转换
线程的状态有5种
1.新建状态 线程刚被创建
2.运行状态 运行状态的线程可以是正在执行的,也可以是正在等待cpu分配执行时间的线程
3.无限期等待状态 处于这个状态下的线程不会被CPU分配执行时间,需要被其他的线程显示的唤醒
4.限期等待状态 处于这个状态下的线程不会被CPU分配执行时间,不需要被其他的线程显示的唤醒,到了一定时间就会由系统自动唤醒
5.阻塞状态 线程被阻塞了,阻塞状态和等待状态是不一样的,因为阻塞状态是在等待着获取一个排他锁,这个事件将会在另一个线程放弃这个锁的时候发生,而等待状态是在等待一段时间,或者唤醒动作的发生。
6.结束状态 已终止线程的线程状态,线程已经结束执行。
新建状态可以由start()转换为运行状态,
运行状态和无限等待状态会w由ait(),notify()来转化。
synchronized会由运行状态变为阻塞状态。
运行状态和有限等待状态会sleep()来转化。
run()结束以后就进入结束状态(Terninated)
sleep()是放弃cpu资源,但是不放弃锁的占有权,是thread的静态方法。
wait(),notify()是放弃锁的占有权。是object类的方法。
41.java线程池
42.java如何判断死锁
“什么是死锁?”开始。答案很简单,当有两个或更多的线程在等待对方释放锁并无限期地卡住时,这种情况就称为死锁。这只会发生在多线程的情况下。
1.利用Jstack查看死锁
进入进入jdk安装目录的bin下面,输入jps,先查看我们要检测死锁的进程:
进程Test的进程号:8384,然后执行:Jstack -l 8384
2.Jconsole
Jconsole是JDK自带的图形化界面工具,使用JDK给我们的的工具JConsole,可以通过打开cmd然后输入jconsole打开。
死锁的例子
public static void main(String[] args) {
final Object a = new Object();
final Object b = new Object();
Thread threadA = new Thread(new Runnable() {
public void run() {
synchronized (a) {
try {
System.out.println("now i in threadA-locka");
Thread.sleep(1000l);
synchronized (b) {
System.out.println("now i in threadA-lockb");
}
} catch (Exception e) {
// ignore
}
}
}
});
Thread threadB = new Thread(new Runnable() {
public void run() {
synchronized (b) {
try {
System.out.println("now i in threadB-lockb");
Thread.sleep(1000l);
synchronized (a) {
System.out.println("now i in threadB-locka");
}
} catch (Exception e) {
// ignore
}
}
}
});
threadA.start();
threadB.start();
}
有三个线程T1 T2 T3,如何保证他们按顺序执行
public class Test {
// 1.现在有T1、T2、T3三个线程,你怎样保证T2在T1执行完后执行,T3在T2执行完后执行
public static void main(String[] args) {
final Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
System.out.println("t1");
}
});
final Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
try {
//引用t1线程,等待t1线程执行完
t1.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("t2");
}
});
Thread t3 = new Thread(new Runnable() {
@Override
public void run() {
try {
//引用t2线程,等待t2线程执行完
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("t3");
}
});
t3.start();
t2.start();
t1.start();//这三个线程启动没有先后顺序的
}
}43.死锁产生的条件
死锁产生的原因:
1)系统资源不足;
2)进程(线程)推进的顺序不恰当;
3)资源分配不当。
如果系统资源充足,进程的资源请求都能够得到满足,死锁出现的可能性就很低,否则就会因争夺有限的资源而陷入
死锁;其次,进程运行推进顺序与速度不同,也可能产生死锁。
死锁的条件:
1)互斥条件:简单的说就是进程抢夺的资源必须是临界资源,一段时间内,该资源只能同时被一个进程所占有。
2)请求和保持条件:当一个进程持有了一个(或者更多)资源,申请另外的资源的时候发现申请的资源被其他进程所持有,当前进程阻塞,但不会是放自己所持有的资源。
3)不可抢占条件:进程已经获得的资源在未使用完毕的情况下不可被其他进程所抢占
在很多情况下这些条件都是合乎要求的。例如,为确保结果的一致性和数据库的完整性,互斥是非常有必要的。同理,不能随意的进行资源抢占。比如,当涉及数据资源时,必须提供回滚恢复机制(rollback recovery machanism)以支持抢占资源,这样才能把进程和他的资源恢复到以前适当的状态,使得进程最终可以重复他的动作。
前三个条件都是死锁存在的必要条件,但不是充分条件。对死锁的产生还需要第四个条件:
4)循环等待条件:存在一个封闭的进程链,使得每个进程至少占有此链中下一个进程所需要的一个资源。
这里所说的资源不仅包括硬件资源或者其他的资源,还包括锁,锁也是一种资源,锁的争用也会导致死锁
处理死锁的基本方法
1.预防死锁:通过设置一些限制条件,去破坏产生死锁的必要条件
2.避免死锁:在资源分配过程中,使用某种方法避免系统进入不安全的状态,从而避免发生死锁
3.检测死锁:允许死锁的发生,但是通过系统的检测之后,采取一些措施,将死锁清除掉
4.解除死锁:该方法与检测死锁配合使用
避免死锁的方式-银行家算法
https://www.cnblogs.com/Kevin-ZhangCG/p/9038223.html
44.可重入锁与不可重入锁
可重入锁
一个同步方法可以调用另外一个同步方法,一个线程已经拥有某个对象的锁,再次申请的时候仍然会得到该对象的锁
常用的可重入锁有Synchronize以及我们以后会提到的ReentrantLock都是可重入锁
不可重入锁
当前线程获取这把锁后,要想再拿到这把锁,必须释放当前持有的锁,这时我们称这个锁是不可重入的。
45.数据库范式//之前出现过
46.JAVA多态体现在哪些方面
满足这三个条件 1.有继承 2. 有重写 3. 要有父类引用指向子类对象
47.说一下spring IOC AOP//之前出现过
48.java除了用new创建对象以外还可以怎么创建?
1.利用克隆
2。利用反序列化
3.利用反射49.接口和抽象类的区别,各自的用法//之前出现过


50.详细讲讲hashmap的知识,hashtable效率低,我想用线程安全的hashmap怎么办?(讲了concurrenthashmap)


51.JVM参数Xms,Xmx是干什么用的?


52.你熟悉jvm的哪方面的知识(jvm内存布局,垃圾回收)




JAVA8的相关特性
Java 8 相关知识
关于 Java8 中新知识点,面试官会让你说说 Java8 你了解多少,下边主要阐述我所了解,并且在面试中回答的 Java8 新增知识点。
0.1 HashMap 的底层实现有变化:HashMap 是数组 + 链表 + 红黑树(JDK1.8 增加了红黑树部分)实现。
02. JVM 内存管理方面,由元空间代替了永久代。
区别:
1. 元空间并不在虚拟机中,而是使用本地内存;
2. 默认情况下,元空间的大小仅受本地内存限制;
3. 也可以通过 -XX:MetaspaceSize 指定元空间大小。
03. Lambda 表达式(也称为闭包),允许我们将函数当成参数传递给某个方法,或者把代码本身当做数据处理。
04. 函数式接口:指的是只有一个函数的接口,java.lang.Runnable 和 java.util.concurrent.Callable 就是函数式接口的例子;java8 提供了一个特殊的注解 @Functionallnterface 来标明该接口是一个函数式接口。
05. 引入重复注解:Java 8 中使用 @Repeatable 注解定义重复注解。
06. 接口中可以实现方法 default 方法。
07. 注解的使用场景拓宽: 注解几乎可以使用在任何元素上:局部变量、接口类型、超类和接口实现类,甚至可以用在函数的异常定义上。
08. 新的包 java.time 包
包含了所有关于日期、时间、时区、持续时间和时钟操作的类。
这些类都是不可变的、线程安全的。53.java并发控制的几种方法
1.互斥同步
synchronized
concurrent包中的ReentrantLock
2.非阻塞同步
CAS
3.ThreadLocal54.java线程的创建方式
1.继承Thread类
2.实现runnable接口
3.实现callable接口。package com.callable.runnable;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
/**
* Created on 2016/5/18.
*/
public class CallableImpl implements Callable<String> {
public CallableImpl(String acceptStr) {
this.acceptStr = acceptStr;
}
private String acceptStr;
@Override
public String call() throws Exception {
// 任务阻塞 1 秒
Thread.sleep(1000);
return this.acceptStr + " append some chars and return it!";
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
Callable<String> callable = new CallableImpl("my callable test!");
FutureTask<String> task = new FutureTask<>(callable);
long beginTime = System.currentTimeMillis();
// 创建线程
new Thread(task).start();
// 调用get()阻塞主线程,反之,线程不会阻塞
String result = task.get();
long endTime = System.currentTimeMillis();
System.out.println("hello : " + result);
System.out.println("cast : " + (endTime - beginTime) / 1000 + " second!");
}
}55.runnable和callable的区别

56.线程池的几种线程
创建线程要花费昂贵的资源和时间,如果任务来了才创建线程那么响应时间会变长,而且一个进程能创建的线程数有限。为了避免这些问题,在程序启动的时候就创建若干线程来响应处理,它们被称为线程池,里面的线程叫工作线程。从JDK1.5开始,Java API提供了Executor框架让你可以创建不同的线程池。比如单线程池,每次处理一个任务;数目固定的线程池或者是缓存线程池(一个适合很多生存期短的任务的程序的可扩展线程池)
线程池的作用,就是在调用线程的时候初始化一定数量的线程,有线程过来的时候,先检测初始化的线程还有空的没有,没有就再看当前运行中的线程数是不是已经达到了最大数,如果没有,就新分配一个线程去处理。
就像餐馆中吃饭一样,从里面叫一个服务员出来;但如果已经达到了最大数,就相当于服务员已经用尽了,那没得办法,另外的线程就只有等了,直到有新的“服务员”为止。
线程池的优点就是可以管理线程,有一个高度中枢,这样程序才不会乱,保证系统不会因为大量的并发而因为资源不足挂掉。




57.cacheThreadPool的任务队列满了以后,怎么处理?
就把任务放在任务队列中58.Mysql联合索引需要满足什么?
创建复合索引时,应该仔细考虑列的顺序。对索引中的所有列执行搜索或仅对前几列执行搜索时,复合索引非常有用;仅对后面的任意列执行搜索时,复合索引则没有用处。
创建复合索引时应该将最常用作限制条件的列放在最左边,依次递减。
3,索引不会包含有NULL值的列
只要列中包含有NULL值都将不会被包含在索引中,复合索引中只要有一列含有NULL值,那么这一列对于此复合索引就是无效的。所以我们在数据库设计时不要让字段的默认值为NULL。
4,使用短索引
对串列进行索引,如果可能应该指定一个前缀长度。例如,如果有一个CHAR(255)的 列,如果在前10 个或20 个字符内,多数值是惟一的,那么就不要对整个列进行索引。短索引不仅可以提高查询速度而且可以节省磁盘空间和I/O操作。59.Mysql的inner join和left join的区别?left join返回的结果数一定会比inner join的多吗?
left join(左联接) 返回包括左表中的所有记录和右表中联结字段相等的记录
right join(右联接) 返回包括右表中的所有记录和左表中联结字段相等的记录
inner join(等值连接) 只返回两个表中联结字段相等的行60.spring的aop,动态代理有几种实现方式?//出现过
两种
1.JDK动态代理 实现共同接口
2.GCLI字节码生成技术,子类继承父类61.web开发分为几层,每层都做什么?
三层
1.视图层
2.控制层
3.模型层
62.手写懒汉式单例模式
双重检验机制63.讲讲java中的锁
1.自旋锁
2.64.MySql存储引擎
1.InnoDB
2.Myisam
3.mymemory65.讲讲B树
B树是多路树
最小度t来定义B树。一棵最小度为t的B树是满足如下四个条件的平衡多叉树:
每个节点最多包含2t−1个关键字;除根节点外的每个节点至少有t−1个关键字(t≤2t≤2),根节点至少有一个关键字;
一个节点uu中的关键字按非降序排列:u.key1≤u.key2≤…u.keynu.key1≤u.key2≤…u.keyn;
每个节点的关键字对其子树的范围分割。设节点u有n+1个指针,指向其n+1棵子树,指针为u.p1,…u.pnu.p1,…u.pn,关键字kiki为u.piu.pi所指的子树中的关键字,有k1≤u.key1≤k2≤u.key2…k1≤u.key1≤k2≤u.key2…成立;
所有叶子节点具有相同的深度,即树的高度hh。这表明B树是平衡的。平衡性其实正是B树名字的来源,B表示的正是单词Balanced;
B+树和B树相比,主要的不同点在以下3项:
内部节点中,关键字的个数与其子树的个数相同,不像B树种,子树的个数总比关键字个数多1个
所有指向文件的关键字及其指针都在叶子节点中,不像B树,有的指向文件的关键字是在内部节点中。换句话说,B+树中,内部节点仅仅起到索引的作用,
在搜索过程中,如果查询和内部节点的关键字一致,那么搜索过程不停止,而是继续向下搜索这个分支。
根据B+树的结构,我们可以发现B+树相比于B树,在文件系统,数据库系统当中,更有优势,原因如下:
B+树的磁盘读写代价更低
B+树的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说I/O读写次数也就降低了。
B+树的查询效率更加稳定
由于内部结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
B+树更有利于对数据库的扫描
B树在提高了磁盘IO性能的同时并没有解决元素遍历的效率低下的问题,而B+树只需要遍历叶子节点就可以解决对全部关键字信息的扫描,所以对于数据库中频繁使用的range query,B+树有着更高的性能。
66.慢查询优化思路
建索引的几大原则
1.最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
2.=和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式
3.尽量选择区分度高的列作为索引,区分度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是1,而一些状态、性别字段可能在大数据面前区分度就是0,那可能有人会问,这个比例有什么经验值吗?使用场景不同,这个值也很难确定,一般需要join的字段我们都要求是0.1以上,即平均1条扫描10条记录
4.索引列不能参与计算,保持列“干净”,比如from_unixtime(create_time) = ’2014-05-29’就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。所以语句应该写成create_time = unix_timestamp(’2014-05-29’);
5.尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可67.讲讲nio
通道 和 缓冲区 是 NIO 中的核心对象,几乎在每一个 I/O 操作中都要使用它们。
通道是对原 I/O 包中的流的模拟。到任何目的地(或来自任何地方)的所有数据都必须通过一个 Channel 对象。一个 Buffer 实质上是一个容器对象。发送给一个通道的所有对象都必须首先放到缓冲区中;同样地,从通道中读取的任何数据都要读到缓冲区中。
什么是缓冲区?
Buffer 是一个对象, 它包含一些要写入或者刚读出的数据。 在 NIO 中加入 Buffer 对象,体现了新库与原 I/O 的一个重要区别。在面向流的 I/O 中,您将数据直接写入或者将数据直接读到 Stream 对象中。
在 NIO 库中,所有数据都是用缓冲区处理的。在读取数据时,它是直接读到缓冲区中的。在写入数据时,它是写入到缓冲区中的。任何时候访问 NIO 中的数据,您都是将它放到缓冲区中。
缓冲区实质上是一个数组。通常它是一个字节数组,但是也可以使用其他种类的数组。但是一个缓冲区不 仅仅 是一个数组。缓冲区提供了对数据的结构化访问,而且还可以跟踪系统的读/写进程。
什么是通道?
Channel是一个对象,可以通过它读取和写入数据。拿 NIO 与原来的 I/O 做个比较,通道就像是流。
正如前面提到的,所有数据都通过 Buffer 对象来处理。您永远不会将字节直接写入通道中,相反,您是将数据写入包含一个或者多个字节的缓冲区。同样,您不会直接从通道中读取字节,而是将数据从通道读入缓冲区,再从缓冲区获取这个字节。
通道类型
通道与流的不同之处在于通道是双向的。而流只是在一个方向上移动(一个流必须是 InputStream 或者 OutputStream 的子类), 而 通道 可以用于读、写或者同时用于读写。
因为它们是双向的,所以通道可以比流更好地反映底层操作系统的真实情况。特别是在 UNIX 模型中,底层操作系统通道是双向的。
状态变量
可以用三个值指定缓冲区在任意时刻的状态:
position
limit
capacity
这三个变量一起可以跟踪缓冲区的状态和它所包含的数据。我们将在下面的小节中详细分析每一个变量,还要介绍它们如何适应典型的读/写(输入/输出)进程。在这个例子中,我们假定要将数据从一个输入通道拷贝到一个输出通道。
1、面向流与面向缓冲
面向流 的 I/O 系统一次一个字节地处理数据。一个输入流产生一个字节的数据,一个输出流消费一个字节的数据。为流式数据创建过滤器非常容易。链接几个过滤器,以便每个过滤器只负责单个复杂处理机制的一部分,这样也是相对简单的。不利的一面是,面向流的 I/O 通常相当慢。
一个 面向块 的 I/O 系统以块的形式处理数据。每一个操作都在一步中产生或者消费一个数据块。按块处理数据比按(流式的)字节处理数据要快得多。但是面向块的 I/O 缺少一些面向流的 I/O 所具有的优雅性和简单性。
Java IO和NIO之间第一个最大的区别是,IO是面向流的,NIO是面向缓冲区的。 Java IO面向流意味着每次从流中读一个或多个字节,直至读取所有字节,它们没有被缓存在任何地方。此外,它不能前后移动流中的数据。如果需要前后移动从流中读取的数据,需要先将它缓存到一个缓冲区。 Java NIO的缓冲导向方法略有不同。数据读取到一个它稍后处理的缓冲区,需要时可在缓冲区中前后移动。这就增加了处理过程中的灵活性。但是,还需要检查是否该缓冲区中包含所有您需要处理的数据。而且,需确保当更多的数据读入缓冲区时,不要覆盖缓冲区里尚未处理的数据。
2、阻塞与非阻塞IO
Java IO的各种流是阻塞的。这意味着,当一个线程调用read() 或 write()时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了。Java NIO的非阻塞模式,使一个线程从某通道发送请求读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,就什么都不会获取,而不是保持线程阻塞,所以直至数据变的可以读取之前,该线程可以继续做其他的事情。 非阻塞写也是如此。一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。 线程通常将非阻塞IO的空闲时间用于在其它通道上执行IO操作,所以一个单独的线程现在可以管理多个输入和输出通道(channel)。
3、选择器(Selectors)
Java NIO的选择器允许一个单独的线程来监视多个输入通道,你可以注册多个通道使用一个选择器,然后使用一个单独的线程来“选择”通道:这些通道里已经有可以处理的输入,或者选择已准备写入的通道。这种选择机制,使得一个单独的线程很容易来管理多个通道。68.写一条SQL,求某一年当中的某个月的每天订单总量和总的金额


69.volatile

volatile
它所修饰的变量不保留拷贝,直接访问主内存中的。
在Java内存模型中,有main memory,每个线程也有自己的memory (例如寄存器)。为了性能,一个线程会在自己的memory中保持要访问的变量的副本。这样就会出现同一个变 量在某个瞬间,在一个线程的memory中的值可能与另外一个线程memory中的值,或者main memory中的值不一致的情况。 一个变量声明为volatile,就意味着这个变量是随时会被其他线程修改的,因此不能将它cache在线程memory中。70.synchronized

当它用来修饰一个方法或者一个代码块的时候,能够保证在同一时刻最多只有一个线程执行该段代码。
● 当两个并发线程访问同一个对象object中的这个synchronized(this)同步代码块时,一个时间内只能有一个线程得到执行。另一个线程必须等待当前线程执行完这个代码块以后才能执行该代码块。
● 然而,当一个线程访问object的一个synchronized(this)同步代码块时,另一个线程仍然可以访问该object中的非synchronized(this)同步代码块。
● 尤其关键的是,当一个线程访问object的一个synchronized(this)同步代码块时,其他线程对object中所有其它synchronized(this)同步代码块的访问将被阻塞。
● 当一个线程访问object的一个synchronized(this)同步代码块时,它就获得了这个object的对象锁。结果,其它线程对该object对象所有同步代码部分的访问都被暂时阻塞。
● 以上规则对其它对象锁同样适用.
71.sql 所有科目大于80的学生姓名
select name from stu
group by name
having name not in (
select name from stu
where score <80)72.多线程下的单例模式
1.双重检验单例
2.静态方法单例
3.synchronized单例73.七层网络模型
1.应用层
2.表示层
3.会话层
4.传输层
5.网络层
6.链路层
7.物理层
74.进程通信方式
进程通信的目的
1、数据传输
一个进程需要将它的数据发送给另一个进程。
2、资源共享
多个进程之间共享同样的资源。
3、通知事件
一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件
4、进程控制
有些进程希望完全控制另一个进程的执行(如 Debug 进程),此时控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变。
1、管道( pipe )
管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
2、有名管道(FIFO)
名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。
3、信号
用于通知接收进程某个事件已经发生,主要作为进程间以及同一进程不同线程之间的同步手段。
4、信号量
信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。
5、消息队列
消息队列是消息的链表,存放在内核中。一个消息队列由一个标识符(即队列ID)来标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
6、共享内存
共享内存(Shared Memory),指两个或多个进程共享一个给定的存储区。
特点:
共享内存是最快的一种 IPC,因为进程是直接对内存进行存取。
因为多个进程可以同时操作,所以需要进行同步。
信号量+共享内存通常结合在一起使用,信号量用来同步对共享内存的访问。
7、套接字
套接字也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同机器间的进程通信
75.linux命令,找出在文件A而不在文件B的内容
76.MyISAM和Innodb区别,实现
MyIASM没有提供对数据库事务的支持,也不支持行级锁和外键,因此当INSERT(插入)或UPDATE(更新)数据时即写操作需要锁定整个表,效率便会低一些。不过和Innodb不同,MyIASM中存储了表的行数,于是SELECT COUNT(*) FROM TABLE时只需要直接读取已经保存好的值而不需要进行全表扫描。如果表的读操作远远多于写操作且不需要数据库事务的支持,那么MyIASM也是很好的选择。
二、Innodb引擎
Innodb引擎提供了对数据库ACID事务的支持,并且实现了SQL标准的四种隔离级别,MySQL运行时Innodb会在内存中建立缓冲池,用于缓冲数据和索引。但是该引擎不支持FULLTEXT类型的索引,而且它没有保存表的行数,当SELECT COUNT(*) FROM TABLE时需要扫描全表。当需要使用数据库事务时,该引擎当然是首选。由于锁的粒度更小,写操作不会锁定全表,所以在并发较高时,使用Innodb引擎会提升效率。但是使用行级锁也不是绝对的,如果在执行一个SQL语句时MySQL不能确定要扫描的范围,InnoDB表同样会锁全表。
三、使用场景
大尺寸的数据集趋向于选择InnoDB引擎,因为它支持事务处理和故障恢复。数据库的大小决定了故障恢复的时间长短,InnoDB可以利用事务日志进行数据恢复,这会比较快。主键查询在InnoDB引擎下也会相当快,不过需要注意的是如果主键太长也会导致性能问题。大批的INSERT语句(在每个INSERT语句中写入多行,批量插入)在MyISAM下会快一些,但是UPDATE语句在InnoDB下则会更快一些,尤其是在并发量大的时候。
1.MYISAM是表锁 INNODB支持表锁和行锁
2.INNODB是支持事务的
都是B+树实现的,但是叶子节点存储的数据是不同的,INNODB存储的是真实的文件数据,MYISAM是存储地址
MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址。

同样也是一颗B+Tree,data域保存数据记录的地址。因此,MyISAM中索引检索的算法为首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。
MyISAM的索引方式也叫做“非聚集”的,之所以这么称呼是为了与InnoDB的聚集索引区分。
InnoDB索引实现
虽然InnoDB也使用B+Tree作为索引结构,但具体实现方式却与MyISAM截然不同。
第一个重大区别是InnoDB的数据文件本身就是索引文件。从上文知道,MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。

这里以英文字符的ASCII码作为比较准则。聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。
了解不同存储引擎的索引实现方式对于正确使用和优化索引都非常有帮助,例如知道了InnoDB的索引实现后,就很容易明白为什么不建议使用过长的字段作为主键,因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大。再例如,用非单调的字段作为主键在InnoDB中不是个好主意,因为InnoDB数据文件本身是一颗B+Tree,非单调的主键会造成在插入新记录时数据文件为了维持B+Tree的特性而频繁的分裂调整,十分低效,而使用自增字段作为主键则是一个很好的选择。
77.数据库隔离级别//之前出现过
1.可串行化
2.可重复读
3.读已提交
4读未提交78.java内存模型
java内存模型中规定了所有变量都存贮到主内存(如虚拟机物理内存中的一部分)中。
每一个线程都有一个自己的工作内存(如cpu中的高速缓存)。
线程中的工作内存保存了该线程使用到的变量的主内存的副本拷贝。
线程对变量的所有操作(读取、赋值等)必须在该线程的工作内存中进行。
不同线程之间无法直接访问对方工作内存中变量。线程间变量的值传递均需要通过主内存来完成。
Java内存模型对一个线程所做的变动能被其它线程可见提供了保证,它们之间是先行发生关系。
这个关系定义了一些规则让程序员在并发编程时思路更清晰。比如,先行发生关系确保了:
● 线程内的代码能够按先后顺序执行,这被称为程序次序规则。
● 对于同一个锁,一个解锁操作一定要发生在时间上后发生的另一个锁定操作之前,也叫做管程锁定规则。
● 前一个对volatile的写操作在后一个volatile的读操作之前,也叫volatile变量规则。
● 一个线程内的任何操作必需在这个线程的start()调用之后,也叫作线程启动规则。
● 一个线程的所有操作都会在线程终止之前,线程终止规则。
● 一个对象的终结操作必需在这个对象构造完成之后,也叫对象终结规则。79.GC.G1
GC是垃圾收集
80.sql 每门科目最高的两个人
SELECT a.name, a.subject, a.score FROM stuscore AS a WHERE
(SELECT COUNT(*) FROM stuscore AS b
WHERE b.subject = a.subject AND b.score >= a.score) <= 2
ORDER BY a.subject ASC, a.score DESC81.CAS
CAS(Compare And Swap)
什么是CAS
CAS(Compare And Swap),即比较并交换。是解决多线程并行情况下使用锁造成性能损耗的一种机制,CAS操作包含三个操作数——内存位置(V)、预期原值(A)和新值(B)。如果内存位置的值与预期原值相匹配,那么处理器会自动将该位置值更新为新值。否则,处理器不做任何操作。无论哪种情况,它都会在CAS指令之前返回该位置的值。CAS有效地说明了“我认为位置V应该包含值A;如果包含该值,则将B放到这个位置;否则,不要更改该位置,只告诉我这个位置现在的值即可。81.慢查询
通过MySQL数据库开启慢查询
mysql>set global slow_query_log=ON
mysql>set global long_query_time = 3600;
mysql>set global log_querise_not_using_indexes = ON;
四、分析慢查询日志
方式一:通过工具分析
MySQL自带了mysqldumpslow工具用来分析slow query日志,除此之外,还有一些好用的开源工具。
这里假设保存的日志名为long.log
列出记录次数最多的10个sql语句:
mysqldumpslow -s c -t 10 long.log
1
列出返回记录集最多的10个sql语句:
mysqldumpslow -s r -t 10 long.log
1
方式二:直接分析mysql慢查询日志
# Time: 121017 17:38:54
# User@Host: root[root] @ localhost [127.0.0.1]
# Query_time: 3.794217 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 4194304
SET timestamp=1350466734;
select * from wei where text='orange';
# Time: 121017 17:46:22
# User@Host: root[root] @ localhost [127.0.0.1]
# Query_time: 3.819219 Lock_time: 0.000000 Rows_sent: 0 Rows_examined: 4194304
SET timestamp=1350467182;
select * from wei where text='long';
82.高并发同步的系统设计问题
83.加密算法
84.tcp长,短连接,长连接的特点
85.手写一个延迟加载且线程安全的单例模式
86.为什么使用volatilea关键字。synchronized锁住了什么?如果构造函数中使用了远程调用是否会发生中断?
87.数组的排序有哪些方法?https://blog.csdn.net/weixin_41835916/article/details/81661314
89,讲一下快排的实现,非递归呢?用栈
90.java的多态怎么实现,
重载,重写,转型91.Java的字符串比较怎么做?直接用==会怎么样?
字符串的比较是重写了equal的方法,比较字符串的内容
==比较的是内存地址92.java的容器用过哪些?map是怎么实现的。红黑树是什么结构,和平衡二叉树的区别呢?为什么用红黑树不用平衡二叉树?源码分析
93.java的垃圾回收说一下
1.垃圾回收的区域
2.怎么判断应该是要回收的垃圾
3.垃圾回收算法
4.垃圾收集器94.网络这块学过吗?tcp与udp的区别,两个udp能够有序到达吗?为什么会乱序?

95.操作系统的内存管理,线程调度
https://blog.csdn.net/justloveyou_/article/details/78304294
96.网络编程了解吗?epoll的实现呢?
97.服务器端的sorket编程怎么做?
98二叉平衡树是什么?
99.双向链表是什么?
100.https为什么是安全的?
101索引的作用,为什么可以加快查询速度,所有都可以加索引吗?
102,负载均衡了解吗?
103.第一范式,第二范式是什么?//之前出现过
第一范式是:表中的每一列都必须是纯净的,不能是可以再分割的
第二范式:表中的非主键属性不能依赖与主属性的部分。
104.输入网址后的全过程
解析:经典的网络协议问题。
答:
由域名→IP 地址
寻找 IP 地址的过程依次经过了浏览器缓存、系统缓存、hosts 文件、路由器缓存、 递归搜索根域名服务器。
建立 TCP/IP 连接(三次握手具体过程)
由浏览器发送一个 HTTP 请求
经过路由器的转发,通过服务器的防火墙,该 HTTP 请求到达了服务器
服务器处理该 HTTP 请求,返回一个 HTML 文件
浏览器解析该 HTML 文件,并且显示在浏览器端
这里需要注意:
HTTP 协议是一种基于 TCP/IP 的应用层协议,进行 HTTP 数据请求必须先建立 TCP/IP 连接
可以这样理解:HTTP 是轿车,提供了封装或者显示数据的具体形式;Socket 是发动机,提供了网络通信的能力。
两个计算机之间的交流无非是两个端口之间的数据通信 , 具体的数据会以什么样的形式展现是以不同的应用层协议来定义的。105tcp和udp的区别
回答发送数据前是否存在建立连接的过程;
TCP过确认机制,丢包可以重发,保证数据的正确性;UDP不保证正确性,只是单纯的负责发送数据包;
UDP 是面向报文的。发送方的 UDP 对应用程序交下来的报文,在添加首部后就向下交付给 IP 层。既不拆分,也不合并,而是保留这些报文的边界,因 此,应用程序需要选择合适的报文大小;
UDP 的头部,只有 8 个字节,相对于 TCP 头部的 20 个字节信息包的额外开销很小。106.java和c++的区别,重构和重载的区别
107设计模式
108.stringbuilder和stringbuffer的区别
109.static变量的线程安全问题。
110.static代码块什么时候执行?
111.bio nio aio
112.垃圾回收怎么定位垃圾
1.计数引用法
2.可达性分析法113.oom怎么处理

114.future
115.线程的几种创建方式
1.继承Thread类
2.实现了runnable接口
3.实现了callable接口。重写call方法,并用furthurtask包装。116.线程池的参数,拒绝策略,队列类型
1.核心池
2.最大线程数
3.最长空闲时间
4.时间单位
5.任务队列
6.拒绝策略
任务队列类型
1.ArrayBlockedQueqe
2.LinkedBlockedQueqe
3.SynchrniedBlockedQueqe
拒绝策略
1.放弃并且抛出异常
2.放弃但没有抛出异常
3.放弃队列最开始的线程
4.调用线程来处理
117.右连接
右边表的行全部存在,左边表的某些行的属性不存在则为空118.sql语句, join操作
1.内连接
2.左连接
3.右连接119.hibernate怎么批量查询id主键,//
120.aop失效,主要是动态代理的底层原理
122.java内存模型//前面出现过
123.双亲委派模型,tomcat怎么实现不同应用之间的jar包隔离,怎么实现同一个行用不同版本的jar的隔离

124.epoll的具体实现
125.数据库的锁,悲观锁,乐观锁,其实现原理还有哪些?
127,hashmap的实现,其底层的数据结构,初始长度,扩容机制,以及为什么,多线程下会发生什么问题
https://blog.csdn.net/weixin_41835916/article/details/80338170
128.hash冲突的解决方案有哪些?
129.linux的使用命令用过哪些?
130 object有哪些方法?wait()和notify()在哪里用?
131,常量存放在哪个位置?如果常量太多引起了fullGc怎么办?
133.怎么实现禁止重排序,内存屏障?
134.先行发生规则的理解
135.spring ioc的理解与aop
136,.java反射用过吗?对他的理解
https://blog.csdn.net/weixin_41835916/article/details/81540163
137.怎么保证线程安全,锁机制,sychronized的锁膨胀机制
139.进程与线程的区别

141.面向对象的5大原则有哪些?
145.mysql支持位图索引吗?
146。服务器的jvm参数怎么配?配过吗?
147.红黑树
148.cache,buffer的区别
149.final finally finalize区别
1.final用于修饰变量和方法,修饰变量表示不可变,是常量。修饰方法表示变量是不可重写的。
2.finally用于异常处理中,用于最后的资源清扫等
3.finalize是在垃圾回收前使用的,是最后一次拯救自己的机会152.Linux查看tomcat进程并杀掉
154.设计实现一个阻塞队列
155.并发包了解,countdownLatch和circlebarrier的区别作用
157.写观察者模式,讲一讲装饰模式和代理模式
158.linux命令 端口占用
159.你怎么学习的,看书看博客
160集合关系说一遍
161.string stringbuilder stringbuffer
string是不可变的类,它是有final修饰的类,
stringbuffer和stringbuilder是可以变的,
stringbuffer是线程安全的,
stringbuilder不是线程安全的
162.switch中可以用string吗?为什么
可以啊。因为在jdk1.7之后就规定了可以使用string了
jdk1.7并没有新的指令来处理switch string,而是通过调用switch中string.hashCode,将string转换为int从而进行判断。163.equal与==的区别
object中的equal方法是进行对象间的内存比较的,==也是
但是比如string中会重写equal方法,实现了是进行内容的的比较164.jvm内存结构
1程序计数器
2.堆
3.方法区(1.8就没有了,变为元数据位于本地了)
4.虚拟机栈
5.本地方法栈165.各部分会发生什么异常
166.如何判断是否需要回收对象
168.hashmap结构
169hashmap扩容
179.为什么是2n扩容/
180,负载因为为什么是0.75
181.怎么找到hashcode位置
182.数据库了解吗?视图与表的区别?索引的优缺点
184.线程调度和进程调度的方法
184.怎么避免死锁
在有些情况下死锁是可以避免的。三种用于避免死锁的技术:
加锁顺序(线程按照一定的顺序加锁)
加锁时限(线程尝试获取锁的时候加上一定的时限,超过时限则放弃对该锁的请求,并释放自己占有的锁)
死锁检测
185,堆和栈的区别
186.栈与队列的区别
188.数据库了解哪些?第三范式 数据库数据太多,该怎么存储,索引及作用
190.迭代器模式了解吗?迭代器失效知道吗?
192.多线程编程会吗?

193.fork的原理
195epoll的优势
196.多线程的使用场景
197,linux进程管理相关命令
200.实现lock锁,手写aqs
201,数据库,问in like嵌套用索引吗?explain各字段代表什么
http://www.cnitblog.com/aliyiyi08/archive/2008/09/09/48878.html
202,http状态吗,结合代码去分析怎么写返回不同的状态码
207.linux关于查找日志的命令
208.http https(如何保证安全)
209http请求和响应报文
210.手写请求头响应头
211.优先队列数据结构
212.红黑树与AVL树的区别
215建索引的应用题
216.数据库中unique key与primary key的区别
了标识数据库记录唯一性,不允许记录重复,且键值不能为空,主键也是一个特殊索引。
二,相同点:Unique key与primarykey 约束都强调唯一性。
三, 不同点:
1.一个表只能有一个PRIMARY KEY,但可以有多个UNIQUE KEY ;
2.unique key 约束只针对非主键列,允许有空值。Primary key 约束针对主键列,不允许有空值。
primary key = unique + not null
UNIQUE KEY的用途:主要是用来防止数据插入的时候重复的。217,数据表设计应该注意什么?
218.http的get方法与post方法分别在场景中使用。
219.hashmap hashtable,手画hashmap多线程下扩容死循环的过程,然后concurrenhashmap的设计
220,spring中的beanfacory与applicationcontext的设计,以及如何加载beandefinition和如何解决循环依赖问题,spring的事务管理,如何suspend,resume,connection绑定threadlocal ?????
221.lock,synchronized的设计
222.三次握手过程中滑动窗口的更新过程,拥塞窗口,缓冲区中发送窗口和接受窗口的组成。还有快速重传,快速恢复,粘包问题(阅读tcp/ip协议)????
223.sql b+树,b树,hash索引,隔离级别,gap lock next key locking在rr下怎么解决幻读的,还有serializeable怎么加锁????
224.mysql case
225.os内存管理 中断机制 软中断 内存管理的常用内存管理算法????
226.你熟悉哪个数据结构?(链表)
227.写个反转链表,优化
228.写一个取100个数的前k大数
229.b和b+树的区别 b+树除了能索引还可以干嘛?
231.线程共享的方式
232.int 和interger的区别和用法,如果在项目中用怎么用?
234说说面向对象的特性,怎么使用
封装 继承 多态236.TCP与UDP的区别,和应用场景
238.了解死锁吗?
239.造成死锁的四个条件,写一个死锁的情况
240,查看进程的命令
243http和https的端口号
245.502 504的状态码表示什么?
246分布式事务
247.hashset底层原理 hashmap底层原理
248.arraylist扩容
249.http状态码
250一堆ip查找
252.tcp面向数据流是怎么理解的
253.滑动窗口机制
254tcp怎么上层传来的数据分块
255.ping的原理,用到了什么协议,哪一层的?
Ping其实属于一个通讯协议,是TCP/IP协议的一部分;Ping发送一个ICMP也就是因特网信报控制协议;发消息给目的地并报告是否收到所希望的ICMP echo(ICMP回声应答)。是用来检查网络是否通畅或者网络连接速度的命令;原理如下:利用网络机器IP地址的唯一性,给目标IP地址发送一个数据包,再要求对方返回一个同样大小的数据包来确定两台网络机器是否连接相同,时延是多少。应用格式:ping空格IP地址。
- 256,红黑树特点,怎么插入的。
红黑树的5个特点:
1。根节点是黑色的
2.结点不是黑色就是红色
3.红结点的孩子结点都是红色的
4.每条到叶子结点的路径上的黑节点个数相同
5.每个叶子节点(NIL结点)都是黑色的。将一个节点插入到红黑树中,需要执行哪些步骤呢?首先,将红黑树当作一颗二叉查找树,将节点插入;然后,将节点着色为红色;最后,通过"旋转和重新着色"等一系列操作来修正该树,使之重新成为一颗红黑树。详细描述如下:
第一步: 将红黑树当作一颗二叉查找树,将节点插入。
红黑树本身就是一颗二叉查找树,将节点插入后,该树仍然是一颗二叉查找树。也就意味着,树的键值仍然是有序的。此外,无论是左旋还是右旋,若旋转之前这棵树是二叉查找树,旋转之后它一定还是二叉查找树。这也就意味着,任何的旋转和重新着色操作,都不会改变它仍然是一颗二叉查找树的事实。
好吧?那接下来,我们就来想方设法的旋转以及重新着色,使这颗树重新成为红黑树!
第二步:将插入的节点着色为"红色"。
为什么着色成红色,而不是黑色呢?为什么呢?在回答之前,我们需要重新温习一下红黑树的特性:
(1) 每个节点或者是黑色,或者是红色。
(2) 根节点是黑色。
(3) 每个叶子节点是黑色。 [注意:这里叶子节点,是指为空的叶子节点!]
(4) 如果一个节点是红色的,则它的子节点必须是黑色的。
(5) 从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。
将插入的节点着色为红色,不会违背"特性(5)"!少违背一条特性,就意味着我们需要处理的情况越少。接下来,就要努力的让这棵树满足其它性质即可;满足了的话,它就又是一颗红黑树了。o(∩∩)o...哈哈
第三步: 通过一系列的旋转或着色等操作,使之重新成为一颗红黑树。
第二步中,将插入节点着色为"红色"之后,不会违背"特性(5)"。那它到底会违背哪些特性呢?
对于"特性(1)",显然不会违背了。因为我们已经将它涂成红色了。
对于"特性(2)",显然也不会违背。在第一步中,我们是将红黑树当作二叉查找树,然后执行的插入操作。而根据二叉查找数的特点,插入操作不会改变根节点。所以,根节点仍然是黑色。
对于"特性(3)",显然不会违背了。这里的叶子节点是指的空叶子节点,插入非空节点并不会对它们造成影响。
对于"特性(4)",是有可能违背的!
那接下来,想办法使之"满足特性(4)",就可以将树重新构造成红黑树了。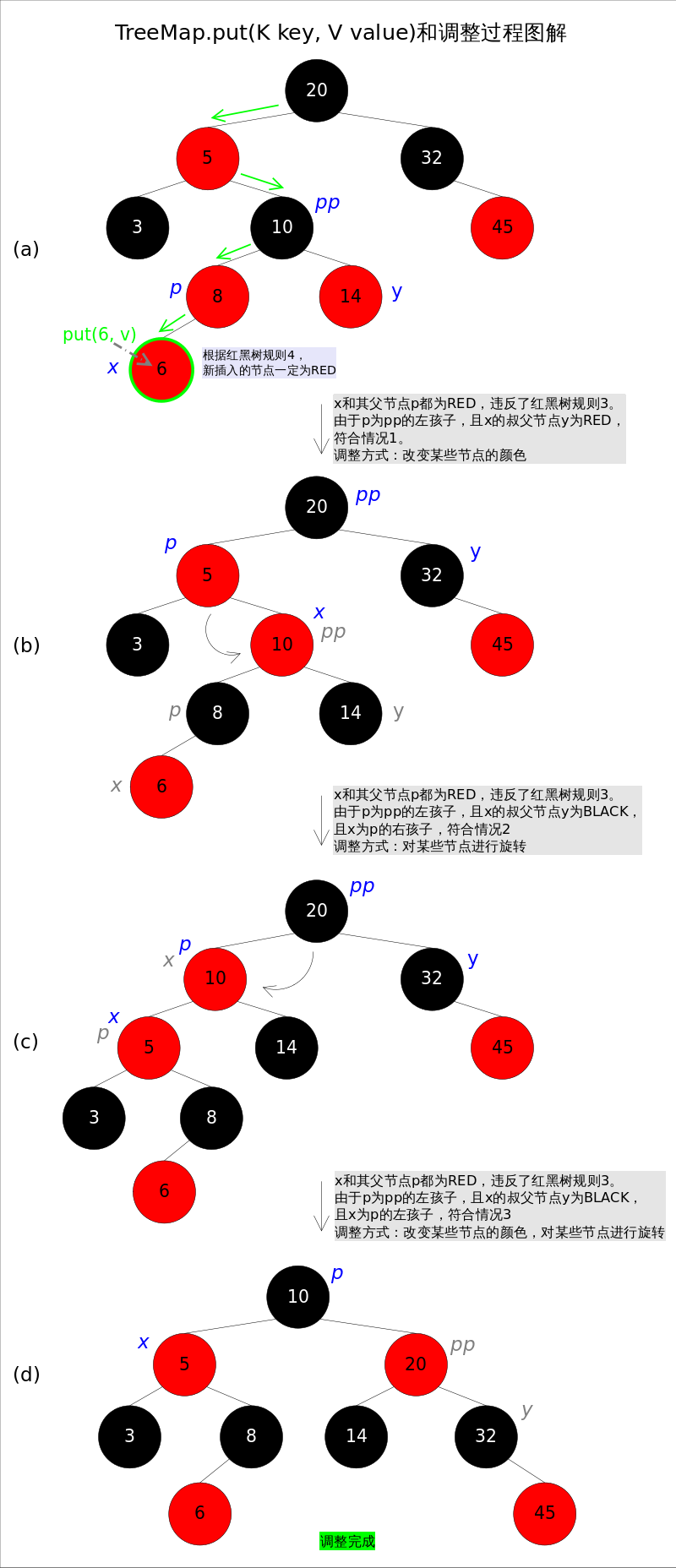
258.对面向对象的理解?
面向对象是一种思想,是基于面向过程而言的,就是说面向对象是将功能等通过对象来实现,将功能封装进对象之中,让对象去实现具体的细节;这种思想是将数据作为第一位,而方法或者说是算法作为其次,这是对数据一种优化,操作起来更加的方便,简化了过程。面向对象有三大特征:封装性、继承性、多态性,其中封装性指的是隐藏了对象的属性和实现细节,仅对外提供公共的访问方式,这样就隔离了具体的变化,便于使用,提高了复用性和安全性。对于继承性,就是两种事物间存在着一定的所属关系,那么继承的类就可以从被继承的类中获得一些属性和方法;这就提高了代码的复用性。继承是作为多态的前提的。多态是说父类或接口的引用指向了子类对象,这就提高了程序的扩展性,也就是说只要实现或继承了同一个接口或类,那么就可以使用父类中相应的方法,提高程序扩展性,但是多态有一点不好之处在于:父类引用不能访问子类中的成员。
类是面向对象中的一个很重要的概念,因为类是很多个具有相同属性和行为特征的对象所抽象出来的,对象是类的一个实例。
然后,围绕类的三个特征来说了:封装、继承和多态。
1、封装:面向对象语言的精髓
把一些属性和方法封装起来,形成一个类;
类的属性一般私有;
类的方法:该公开的公开,该私有的私有;方法,封装了实现的过程,接口是参数和返回值;
举例:1)get/set 方法;对某一个属性只提供get不提供set方法,就是只读的,在类的外部不能修改;2)提供统一的参数检查,在set上给与检查,判断合法性和安全性;将属性都私有,并且提供set/get 方法,做成了通用的组件,叫JavaBean;
2. 继承:面向对象的主要功能
继承是一种构建新类的方式,他是基于已有的类的定义为基础,构建新的类,已有的类称为父类,新构建的类称为子类,子类能调用父类的非private修饰的成员,同时还可以自己添加一些新的成员,扩充父类,甚至重写父类已有的方法,更其表现符合子类的特征。让子类的表现更独特,更专业。
3.多态
从一定角度来看,封装和继承几乎都是为多态而准备的。这是我们最后一个概念,也是最重要的知识点。
多态是同一个行为具有多个不同表现形式或形态的能力。多态性是对象多种表现形式的体现
类中多个方法的重载叫多态,父子类中方法的覆盖也叫多态。
因此多态有两种体现:一个是方法的重装,一个是方法的覆盖。
多态有方法的多态和对象的多态(一个对象多种形态)。
259,二叉平衡树 二叉查找树 红黑树
261.concurrentmap介绍一下
262.sql注入
sql是使用动态拼接的方式,所以sql传入的方式可能改变sql的语义。
动态拼接就是在java中java变量和sql语句混合使用:select * from user where userName=’”+userName+”’ and password = ‘”+password”’
所以要使用preparedStatement的参数化sql,通过先确定语义,再传入参数,就不会因为传入的参数改变sql的语义。(通过setInt,setString,setBoolean传入参数)263,设计模式,单例,工厂,迭代 ,适配
设计模式(背下一个例子+uml图+场景)
1.单例模式
恶汉式
双重检查锁机制
静态类的形式
2.简单工厂模式
3.工厂方法模式
4.抽象工厂模式
4.观察者模式
5.策略模式
6.适配器模式
7.迭代器模式
8.模板模式


老师则是被观察者,被学生观察:
//被观察者的接口
public interface Subject {
//注册观察者
void registerObserver(Observer observer);
//移除观察者
void removeObserver(Observer observer);
//通知观察者
void notifyObservers(String msg);
}
public class TeacherSubject implements Subject{
//用来存放和记录观察者
private List<Observer> observers=new ArrayList<Observer>();
@Override
public void registerObserver(Observer obj) { //增加观察者
observers.add(obj);
}
@Override
public void removeObserver(Observer obj) { //删除观察者
int i = observers.indexOf(obj);
if( i >= 0 )
observers.remove(obj);
}
@Override
public void notifyObservers(String msg) { //通知消息
for(Observer observer : observers) {
observer.update(msg);
}
}
}
测试代码:
public class Test {
public static void main(String[] args){
TeacherSubject teacher = new TeacherSubject();
StudentObserver studentObserver1 = new StudentObserver("鸣人");
StudentObserver studentObserver2 = new StudentObserver("佐助");
teacher.registerObserver(studentObserver1);
teacher.registerObserver(studentObserver2);
teacher.notifyObservers("发作业啦");
}
}
//运行结果:
//鸣人收到消息:发作业啦
//佐助收到消息:发作业啦
265.深度优先
(1)深度优先遍历(利用栈和递归来实现)
思路:先以一个点为起点,这里假如是点A,那么就将A相邻的点放入堆栈,然后在栈中再取出栈顶的顶点元素(假如是点B),再将B相邻的且没有访问过的点放入栈中,不断这样重复操作直至栈中元素清空。这个时候你每次从栈中取出的元素就是你依次访问的点,以此实现遍历。import java.io.IOException;
import java.util.Scanner;
public class MatrixUDG {
private char[] mVexs; // 顶点集合
private int[][] mMatrix; // 邻接矩阵
/*
* 创建图(自己输入数据)
*/
public MatrixUDG() {
// 输入"顶点数"和"边数"
System.out.printf("input vertex number: ");
int vlen = readInt();
System.out.printf("input edge number: ");
int elen = readInt();
if ( vlen < 1 || elen < 1 || (elen > (vlen*(vlen - 1)))) {
System.out.printf("input error: invalid parameters!\n");
return ;
}
// 初始化"顶点"
mVexs = new char[vlen];
for (int i = 0; i < mVexs.length; i++) {
System.out.printf("vertex(%d): ", i);
mVexs[i] = readChar();
}
// 初始化"边"
mMatrix = new int[vlen][vlen];
for (int i = 0; i < elen; i++) {
// 读取边的起始顶点和结束顶点
System.out.printf("edge(%d):", i);
char c1 = readChar();
char c2 = readChar();
int p1 = getPosition(c1);
int p2 = getPosition(c2);
if (p1==-1 || p2==-1) {
System.out.printf("input error: invalid edge!\n");
return ;
}
mMatrix[p1][p2] = 1;
mMatrix[p2][p1] = 1;
}
}
/*
* 创建图(用已提供的矩阵)
*
* 参数说明:
* vexs -- 顶点数组
* edges -- 边数组
*/
public MatrixUDG(char[] vexs, char[][] edges) {
// 初始化"顶点数"和"边数"
int vlen = vexs.length;
int elen = edges.length;
// 初始化"顶点"
mVexs = new char[vlen];
for (int i = 0; i < mVexs.length; i++)
mVexs[i] = vexs[i];
// 初始化"边"
mMatrix = new int[vlen][vlen];
for (int i = 0; i < elen; i++) {
// 读取边的起始顶点和结束顶点
int p1 = getPosition(edges[i][0]);
int p2 = getPosition(edges[i][1]);
mMatrix[p1][p2] = 1;
mMatrix[p2][p1] = 1;
}
}
/*
* 返回ch位置
*/
private int getPosition(char ch) {
for(int i=0; i<mVexs.length; i++)
if(mVexs[i]==ch)
return i;
return -1;
}
/*
* 读取一个输入字符
*/
private char readChar() {
char ch='0';
do {
try {
ch = (char)System.in.read();
} catch (IOException e) {
e.printStackTrace();
}
} while(!((ch>='a'&&ch<='z') || (ch>='A'&&ch<='Z')));
return ch;
}
/*
* 读取一个输入字符
*/
private int readInt() {
Scanner scanner = new Scanner(System.in);
return scanner.nextInt();
}
/*
* 返回顶点v的第一个邻接顶点的索引,失败则返回-1
*/
private int firstVertex(int v) {
if (v<0 || v>(mVexs.length-1))
return -1;
for (int i = 0; i < mVexs.length; i++)
if (mMatrix[v][i] == 1)
return i;
return -1;
}
/*
* 返回顶点v相对于w的下一个邻接顶点的索引,失败则返回-1
*/
private int nextVertex(int v, int w) {
if (v<0 || v>(mVexs.length-1) || w<0 || w>(mVexs.length-1))
return -1;
for (int i = w + 1; i < mVexs.length; i++)
if (mMatrix[v][i] == 1)
return i;
return -1;
}
/*
* 深度优先搜索遍历图的递归实现
*/
private void DFS(int i, boolean[] visited) {
visited[i] = true;
System.out.printf("%c ", mVexs[i]);
// 遍历该顶点的所有邻接顶点。若是没有访问过,那么继续往下走
for (int w = firstVertex(i); w >= 0; w = nextVertex(i, w)) {
if (!visited[w])
DFS(w, visited);
}
}
/*
* 深度优先搜索遍历图
*/
public void DFS() {
boolean[] visited = new boolean[mVexs.length]; // 顶点访问标记
// 初始化所有顶点都没有被访问
for (int i = 0; i < mVexs.length; i++)
visited[i] = false;
System.out.printf("DFS: ");
for (int i = 0; i < mVexs.length; i++) {
if (!visited[i])
DFS(i, visited);
}
System.out.printf("\n");
}
/*
* 广度优先搜索(类似于树的层次遍历)
*/
public void BFS() {
int head = 0;
int rear = 0;
int[] queue = new int[mVexs.length]; // 辅组队列
boolean[] visited = new boolean[mVexs.length]; // 顶点访问标记
for (int i = 0; i < mVexs.length; i++)
visited[i] = false;
System.out.printf("BFS: ");
for (int i = 0; i < mVexs.length; i++) {
if (!visited[i]) {
visited[i] = true;
System.out.printf("%c ", mVexs[i]);
queue[rear++] = i; // 入队列
}
while (head != rear) {
int j = queue[head++]; // 出队列
for (int k = firstVertex(j); k >= 0; k = nextVertex(j, k)) { //k是为访问的邻接顶点
if (!visited[k]) {
visited[k] = true;
System.out.printf("%c ", mVexs[k]);
queue[rear++] = k;
}
}
}
}
System.out.printf("\n");
}
/*
* 打印矩阵队列图
*/
public void print() {
System.out.printf("Martix Graph:\n");
for (int i = 0; i < mVexs.length; i++) {
for (int j = 0; j < mVexs.length; j++)
System.out.printf("%d ", mMatrix[i][j]);
System.out.printf("\n");
}
}
public static void main(String[] args) {
char[] vexs = {'A', 'B', 'C', 'D', 'E', 'F', 'G'};
char[][] edges = new char[][]{
{'A', 'C'},
{'A', 'D'},
{'A', 'F'},
{'B', 'C'},
{'C', 'D'},
{'E', 'G'},
{'F', 'G'}};
MatrixUDG pG;
// 自定义"图"(输入矩阵队列)
//pG = new MatrixUDG();
// 采用已有的"图"
pG = new MatrixUDG(vexs, edges);
pG.print(); // 打印图
pG.DFS(); // 深度优先遍历
pG.BFS(); // 广度优先遍历
}
}聚簇索引和非聚簇索引
聚簇索引
聚簇索引的数据的物理存放顺序与索引顺序是一致的,即:只要索引是相邻的,那么对应的数据一定也是相邻地存放在磁盘上的。聚簇索引要比非聚簇索引查询效率高很多。
聚集索引这种主+辅索引的好处是,当发生数据行移动或者页分裂时,辅助索引树不需要更新,因为辅助索引树存储的是主索引的主键关键字,而不是数据具体的物理地址。
③非聚簇索引
非聚集索引,类似于图书的附录,那个专业术语出现在哪个章节,这些专业术语是有顺序的,但是出现的位置是没有顺序的。每个表只能有一个聚簇索引,因为一个表中的记录只能以一种物理顺序存放。但是,一个表可以有不止一个非聚簇索引。
算法题篇
1.给两个数组,找到他们的交集
class Solution {
public int[] intersect(int[] nums1, int[] nums2) {
Arrays.sort(nums1);
Arrays.sort(nums2);
int i = 0, j = 0, index = 0;
while(i < nums1.length && j < nums2.length){
if(nums1[i] == nums2[j]){
nums1[index++] = nums2[j];
i++;
j++;
} else if(nums1[i] < nums2[j]){
i++;
} else{
j++;
}
}
return Arrays.copyOf(nums1, index);
}
}public class Solution {
public int[] intersect(int[] nums1, int[] nums2) {
HashMap<Integer, Integer> map = new HashMap<Integer, Integer>();
ArrayList<Integer> result = new ArrayList<Integer>();
for(int i = 0; i < nums1.length; i++)
{
if(map.containsKey(nums1[i])) map.put(nums1[i], map.get(nums1[i])+1);
else map.put(nums1[i], 1);
}
for(int i = 0; i < nums2.length; i++)
{
if(map.containsKey(nums2[i]) && map.get(nums2[i]) > 0)
{
result.add(nums2[i]);
map.put(nums2[i], map.get(nums2[i])-1);
}
}
int[] r = new int[result.size()];
for(int i = 0; i < result.size(); i++)
{
r[i] = result.get(i);
}
return r;
}
}2.大数处理:两个文件,一个文件100多万行,每行1k,大部分是相同的,找出他们的不同位置
1.每个文件分为不同的小部分
2.每个小部分进行比较3.大数问题:10G重复URL文件,有限没存,输出唯一的url的排序,写伪代码?
4.给定二叉树输出给定值的层数
5.合并有序数组
剑指offer
6.判断两个链表是否交叉?
剑指offer
7.实现数组去重找出数组中重复次数最多的
8.如何从35个数中取7个不重复的数
9.手写二分查找
10.情景题:我想让网站每一天最多有不同的人访问,同时对于已经获取访问权限的用户再访问时依然可以,设计代码
11.地铁换乘路线
12.括号
14.一个数组,只有一个数出现了一次,其它数都出现了两次,找到出现一次的数。
将数组中的数全部异或,最后得到的数就是不一样的那个数字15..一个数组,只有一个数出现了一次,其它数都出现了3次,找到出现一次的数。
import java.util.Scanner;
public class AppearOnce3 {
public static void main(String[] args){
Scanner scan = new Scanner(System.in);
String s = scan.nextLine();
String[] strArr = s.split(" ");
int len = strArr.length;
int[] nums = new int[len];
for(int i = 0; i < len; i++)
nums[i] = Integer.parseInt(strArr[i]);
System.out.println(appearOnce(nums));
}
public static int appearOnce(int[] nums){
int len = nums.length;
int[] bits = new int[32];
for(int i = 0 ; i < len; i++)
for(int j = 0; j < 32; j++)
bits[j] += ((nums[i]>>j)&1);
int result = 0;
for(int i = 0 ; i < 32; i++){
if(bits[i] % 3 == 1) result += 1 << i;
}
return result;
}
}
16.有10条线程,需要同时执行,自己知道的做法全部都说出来
17.手撕topk快排算法/
18.有n个物品,每次最多拿100个,然后每走一步就会掉1个,求走了100米之后剩余的最大数量
19.二叉树宽度
20.连续子数组最大和
21.数据量很大的文件排序
22.有序数组两个数相加等于某个数的组合
23.给定ABC之间的大小关系,按顺序输出
24.几个概率题,求期望
25.一个二维数组,每行每列都是升序排列,求这个数组中第k小的数
26.5亿条淘宝订单,每条订单包含不同的商品号,每个商品号对应不同的购买数量,求出销量最高的100个商品
27,以上的题目,假设分为500个100万级的数据,对他们进行归并的时间 复杂度是多少,如何确定拆分的数量级大小
28.多个有序链表合并
29,剑指offer的跳台阶问题
30字符编辑距离问题
31.手写快排,时间空间复杂度分析
32.用两个栈实现一个队列
33.在一个数组中找到任意和为taret的数
34.找到数组中出现频次最高的数
35.字符串反转i am student
36.大量的数中的前m个数
37.写一个二分查找
38.用数组实现生产者消费者
39.给定数组,求逆序对
40.二叉树中序遍历递归与非递归遍历
41.手撕四则运算加括号,即给一个字符串包含括号和+-*,给出最后结果
44.整形数据转换成字符串
45.atoi写一下
46.在一个栈里面取最大值
47.二叉树的非递归遍历(广度优先)
48.代码实现提取url中穿的参数和值,保存键对值
49.代码实现N的平方根。不考虑四舍五入取平方根
50。手写反转链表
51.手写快排
52.数组中只有两位数出现了一次,别的数组出现了两次,
53.单源最短路径问题
54.二叉搜索树的第k个结点,怎么设计结构?
55.有一个文件,里面是很多英文,现在要根据里面字母的出现频率从多到少依次输出这些字母(IO流+map+快排)
56.树的深度遍历
57.从右下走到左上有几种走法
58.写一个求二叉树左结点的和
59.N硬币换M元钱
60给定一个整形数组和一个整数target,返回2个元素的下标,它们满足相加的和为target。
你可以假定每个输入,都会恰好有一个满足条件的返回结果。
public class Solution {
public int[] twoSum(int[] nums, int target) {
Map<Integer,Integer> map=new HashMap<>();
for(int i=0;i<nums.length;i++){
Integer index=map.get(target-nums[i]);
if(index==null){
map.put(nums[i],i);
}else{
return new int[]{i,index};
}
}
return new int[]{0,0};
}
}62.实现一个atoi函数来把字符串转换为整型变量。
1. 前面的空格
2. 除去前面的空格后,可以以“+、-、0”开头,需要做对应的处理
3. 除了起始处可以出现前2种情况提到的非数字字符,其他地方一旦出现,则忽略该字符以及其后的字符
4. 考虑边界,即是否超出Integer.MAX_VALUE,Integer.MIN_VALUE。
class Solution {
public:
int myAtoi(string str) {
int length = str.size();
long long ret_64 = 0;
int op = 1;
int p = 0;
while (str[p] == ' ') ++p;
if (str[p] == '+' || str[p] == '-') {
if (str[p] == '-') op = -1;
p++;
}
for (int i = p; i < length; ++i)
if ('0' <= str[i] && str[i] <= '9') {
ret_64 = ret_64 * 10 + (str[i] - '0');
if ((op == -1 && ret_64 > 2147483648LL)) return -2147483648;
if ((op == 1 && ret_64 > 2147483647LL)) return 2147483647;
} else break;
return (int)ret_64 * op;
}
};
不喜欢篇
1.什么时候确定的技术方向
2.为什么不读研
3.对创业公司的看法
4.未来的职业规划
5.对工作态度看法
6.性格上的优缺点
7.课余生活参加了什么活动或者社团
8.你有什么爱好或者特长