之前写的样条插值算法只能在本地执行,但是我想要的是可在hive中执行的jar包,为了符合我的要求,经过痛苦、气愤、悲伤等一系列过程,终于实现了;
想要实现可在hive中执行的jar包,以下是具体步骤:
1。java程序的书写规范

2.java程序如下所示,输入三个参数,x,y,key; x,y为ArrayList<string>格式列表,key为double型的数。返回double型的数;
1 import java.util.ArrayList; 2 import org.apache.hadoop.hive.ql.exec.UDF; 3 4 /** 5 * 样条插值法 6 * @author 91911 7 */ 8 public class SplineInterpolator extends UDF { 9 public double evaluate(ArrayList<String> x,ArrayList<String> y, double key) { 10 return new org.apache.commons.math3.analysis.interpolation.SplineInterpolator() 11 .interpolate(toArray(x),toArray(y)) 12 .value(key); 13 } 14 15 // String转Double 16 public double[] toArray(ArrayList<String> list) { 17 double[] array = new double[list.size()]; 18 for(int i=0;i<list.size();i++){ 19 array[i] = Double.valueOf(list.get(i)); 20 } 21 return array; 22 } 23 }
3.将java包达成jar包
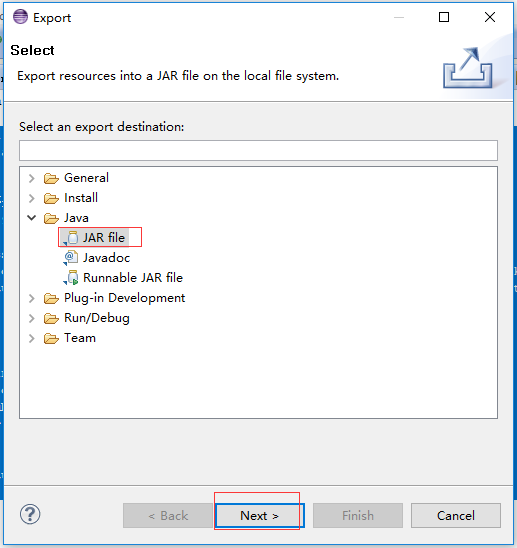
File>Export>JAR file>选择jar包路径>完成
选择jar包类型
选择输出路径
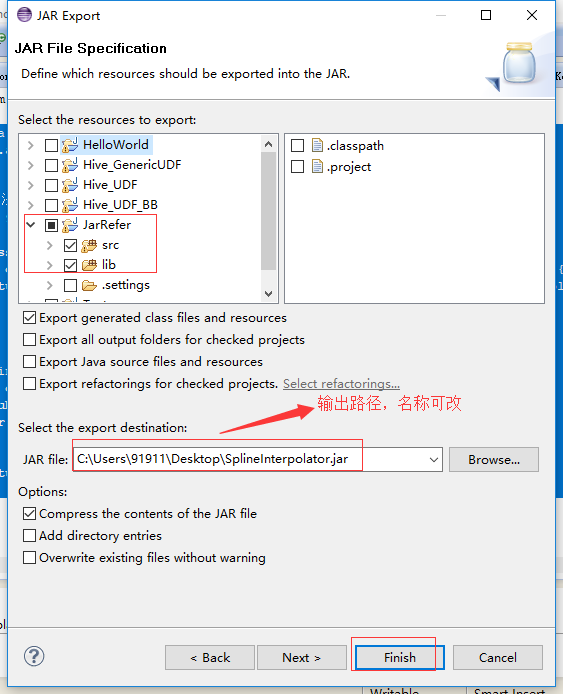
4.将打好的jar包上传至接口机(本地)
5.在hive上新建一个测试表
CREATE TABLE `dim_ia_test_ysf1`(
`x` array<string>,
`y` array<string>)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '|'
COLLECTION ITEMS TERMINATED BY ','
STORED AS textfile;
将数据导入即可
6.测试jar包是否可用
先添加jar包,将java路径(函数)命名为ytf,再使用ytf函数;
add jar /data/all_ana_pro/yuanshufang/function/SplineInterpolatorImpl.jar;
create temporary function ytf as 'com.SplineInterpolatorImplNew';
set hive.limit.optimize.enable=true;
set hive.fetch.task.conversion=more;
select ytf(x,y,0.5) from dim_ia_test_ysf1;
说明:add jar部分为jar包路径;
ytf(x,y,z)—x,y为ArrayList<string>格式列表,z为double型数组,需要手动输入(因为新建的表只有x,y两列);
以上就是完整的过程,从写程序到jar包执行成功;