
该论文于2018年5月首次披露,提出了一种基于亚稳态机制(metastable)的共识协议族。作者是一个神秘团队Team Rocket(火箭队?)。
所谓亚稳态,是指系统在某段时间内处于稳定状态,但在另外一段时间内可能是不稳定的。稳态代表了系统的最低能量点,而亚稳态则是一个局部的而非全局的最低能量点。以下图中的小球为例,如果用比较小的力推小球,则会停留在位置1这个亚稳态上,而如果用比较大的力推,则会进入位置3这个真正的稳态上。

那么这个新的共识协议族有什么特点呢?
- 绿色(Green):消耗很少能源
- 安静(Quiescent):没有交易时不需要工作(出块)
- 高效(Efficient):节点交互复杂度O(knlogn) ~ O(kn)
如何实现以上目标?主要依赖以下几种措施:
- 并行共识模型:不使用单一复制状态机(RSM)模型,每个节点维护自己的RSM(可以互相转移所有权),系统对有关联的交易只维护偏序(partial order)
- 反复随机采样:引导诚实节点产生相同输出
- 亚稳态决策:亚稳态决策可以使得一个大网络快速推进到一个不可逆的状态(虽然不能100%保证)
既然是共识协议,必然绕不过安全性和活性的证明。我们先看一下这两个特性的定义:
- 安全性(Safety):nothing bad happens
- 活性(Liveness):something good eventually happens
该论文证明,文中提出的算法可以提供强概率安全性保证,并且保证诚实节点的活性。所谓“强概率安全保证”,是指共识被逆转的可能性小到可以被忽略(甚至小于哈希冲突的概率),实际上POW提供的也是强概率安全性保证。
另外,文中的理论分析是基于同步系统假设,而实验过程则是在部分同步系统中完成的,实验结果和理论分析基本吻合。
下面开始依次介绍这四种共识算法。
Slush(雪泥)
该算法的灵感来源于Gossip(流言)协议,或者也被称为Epidemic(传染病)协议,主要用于数据同步。
算法流程参见下图:

为了算法的通用性,这里是以颜色冲突为例:R表示红色,B表示蓝色,⊥表示没有颜色(初始状态)。
- 初始状态:没有颜色(⊥)
- 收到交易:染成交易中指定的颜色,同时发起查询
- 查询:在网络中随机选取k个节点,如果规定时间内没有收到k个回复,再多选一些节点,直到收到k个回复为止
- 收到查询:如果没有染色,染成查询中指定的颜色,并回复该颜色,同时自己也发起查询。否则直接回复自己当前的颜色
- 决策:收到k个回复后,如果某种颜色所占比例超过阈值α(0.5~1),则把自己染成那种颜色。然后继续进入下一轮查询,一共查询m轮,决定最终结果
可以证明,随着节点数n的增长,m呈对数级增长,因此可以有效控制通信量。
Slush算法是一种非拜占庭容错(BFT)算法,但却是后面三种BFT算法的基石。
Snowflake(雪花)
Slush算法是无状态记忆的(memoryless),节点不保存和其他节点的交互历史。
Snowflake算法在该基础上,为每个节点增加了一个查询计数器,用于累积该节点对当前颜色的信任度。如果连续β轮都选择该颜色,则接受该颜色。算法流程参见下图:

具体修改的部分:
- 每个节点维护一个计数器
- 每次颜色发生变化时,将该计数器清零
- 每次查询成功(收到αk个回复),并且颜色不变时,计数器加一
Snowball(雪球)
Snowflake记忆的状态是短暂的,每次颜色变化都会将计数器清零。为了使得系统更加难以被攻击,Snowball增加了一个置信度计数器,用于记录每种颜色被选择的次数。如果某种颜色被选次数超过另一种,则切换到该颜色,并等待查询计数器超过阈值。算法流程参见下图:

具体修改的部分:
- 每次查询成功,增加所选颜色的置信度计数器
- 如果某种颜色的置信度变得比另一种低,发生颜色切换
Avalanche(雪崩)
Avalanche在Snowball的基础上引入了DAG。这会带来两点好处:
- 更高效:对DAG某个顶点的投票隐含了对“从创世顶点到该顶点”这整条链的认可
- 更安全:DAG把各个交易的命运交织在了一起,因此共识更加难以被逆转(需要更多诚实节点的认可)
首先解释一下几个术语:
- 祖先集(ancestor set):每个交易可能有一到多个parent,从它们的parent一直追溯到创世顶点过程中的所有交易组成该交易的祖先集
- 子孙集(progeny):该交易的所有子孙后代交易的集合
- 冲突集(conflict set):如果两笔或多笔交易发生了冲突(例如使用了同样的UXTO input,即双花),那么它们组成一个冲突集
- 凭证(chit):如果某笔交易查询成功(超过阈值),则称该交易收到了一个凭证,否则凭证值为0
在下图中,阴影部分表标识的就是冲突集:
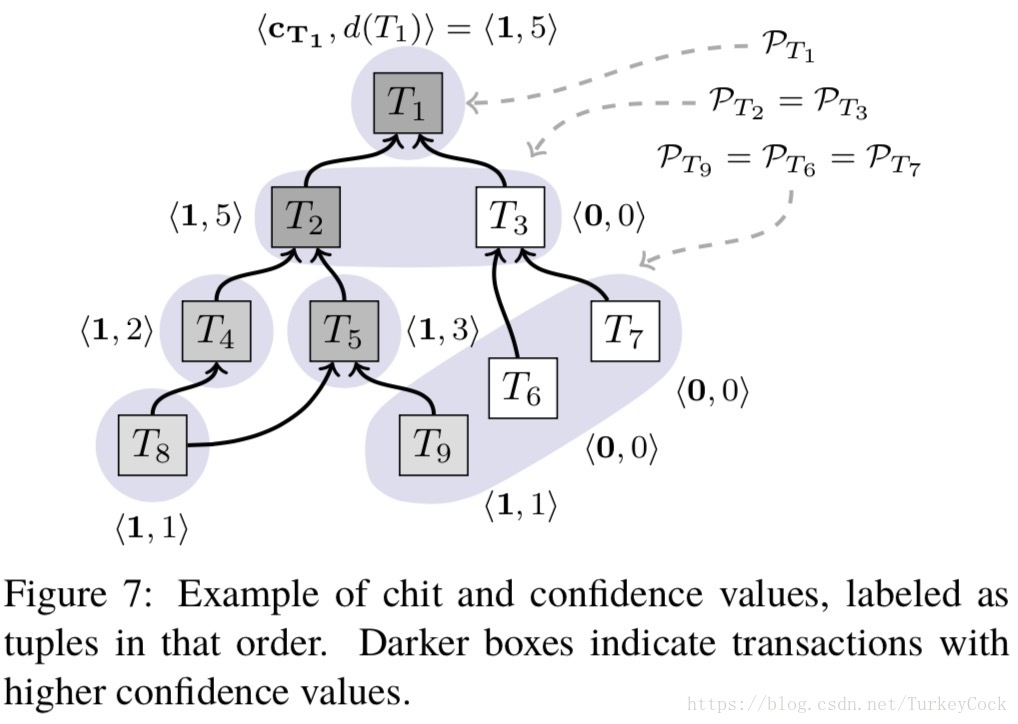
实际上,每个冲突集就是一个Snowball实例,但是置信度的计算方式略有不同,某笔交易的置信度是所有子孙交易的凭证值之和(c表示凭证,d表示置信度):
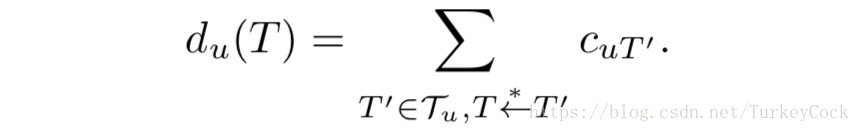
另外,节点在收到查询时,只有该笔交易的所有祖先都是它们对应的冲突集中的偏好选项时才会回复yes,此时称该笔交易时强偏好的(strongly preferred)。
注:上面这张图上似乎有一处谬误,T1的置信度应该是6而不是5。
算法主流程参见下图:

图中的“花写P”代表冲突集,P.pref代表该冲突集中的强偏好,P.last代表上次的强偏好。
Q代表已经查询过的交易的集合,每个交易只会查询一次。
那么,什么时候app(例如钱包节点)可以认可(accept)或者提交(commit)一笔交易呢?文中提到可以设定两种阈值,具体的数值由app来决定:
- 如果冲突集中只有一笔交易(即没有冲突),置信度超过β1即可提交,称为“安全早期提交(safe early commit)”
- 否则,如果冲突集中有多笔交易,根据Snowball协议,需要收到超过β2个连续查询回复才可以提交

交易父顶点的选择(Parent Selection)
既然是DAG,那么就就需要为每笔交易选择父顶点。这个选择算法将会影响活性,并且对DAG的形状起决定性作用。
DAG的形状既不能发散成树状(会导致交易难以被确认),也不能收敛成链状(会导致往前追溯的深度太长)。或者通俗一点说,不能太宽,也不能太窄~ 我们看看文中设计的算法:
首先定义一个集合ε,包含了该交易所有的强偏好祖先:
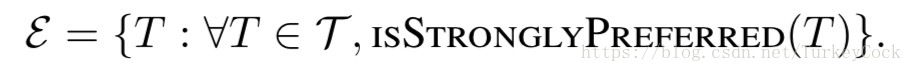
然后定义ε的一个子集ε’,包含ε中所有的冲突集为1或者置信度大于0的交易。如果ε’中的某个交易,它的所有直接子交易都不属于ε’,则把它选为父顶点:
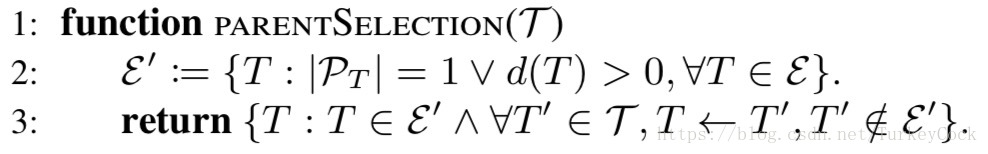
换句话说,优先选择子交易尚未被确认的顶点,或者子交易都存在冲突集的顶点。
安全性证明
文中使用马尔可夫链对网络中的状态转变建模。首先扫盲一下马尔可夫过程和马尔可夫链:
- 马尔可夫过程:将来的状态分布只取决于现在,跟过去无关!
- 马尔可夫链:时间、状态都是离散的马尔可夫过程称为马尔可夫链
还是以颜色为例,假设系统中一共有c个节点,si代表网络中有i个节点是红色的,有c-i个节点是蓝色的。因此整个网络的状态就在s0, s1, s2, …, sc之间来回转换,并且当前状态只和前一个状态相关,这样就构成了一个马尔可夫链。下面依次分析四种算法的安全性:
1. Slush的安全性
论文首先证明了一个引理:Slush一定会在有限时间内收敛(说实话没看懂。。)
其实我们更关心的应该是如何得出这些安全参数:α,k,m。
其中α只要大于0.5就可以了,对于Slush来说k=1是最优的,那么就只剩下m了,也就是要查询多少轮。定义p为从状态si转换到si+1的概率,q为从状态si退回si-1的概率,r为仍停留在si状态的概率,有如下公式:
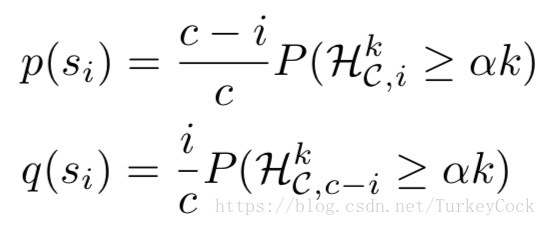
然后通过下面的递推公式就可以算出m了:
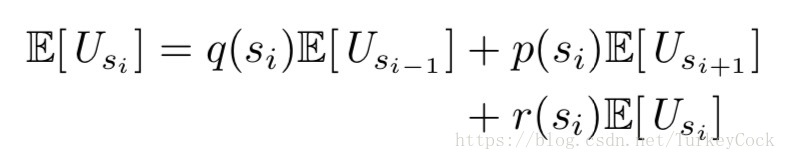
2. Snowflake的安全性
Snowflake和Slush有两个主要的区别:首先是引入了拜占庭节点,然后是需要等待连续确认β次。
这里首先提出了两个新概念:
- 相位偏移点:存在某个状态sps,超过这个状态后,系统收敛到红色的概率将会大于蓝色
- 不可回退点:在相位偏移点之后∆处存在一个不可回退点,使得系统能够回退到相位偏移点的最大概率小于ε(比如2的-32次方)
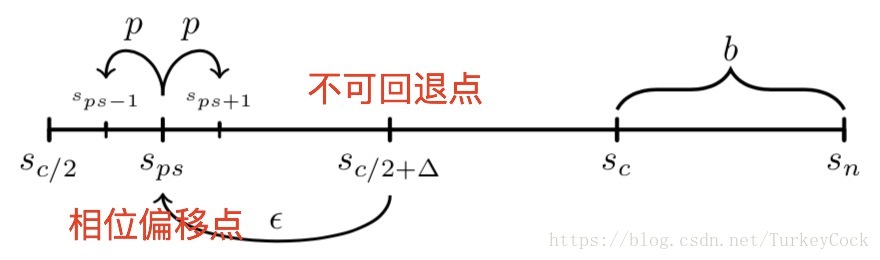
那么这个∆是怎么算出来的呢?文中并没有给出公式,只是说可以通过不断调整安全参数进行实验。
Snowflake有这么几个安全参数:α,k,β。
其中α等于(n-b)/n,这里n是节点数,b是拜占庭节点数。β会影响时延和安全性,因此一般先固定β,然后不断调整k来完成系统设计。
3. Snowball的安全性
Snowball和Snowflake相比有一个区别:节点会保存不同颜色的累积置信度。
这里的证明同样没看懂,反正最终得到一个定理:在相同的安全参数配置下,Snowball比Snowflake更安全。
4. Avalanche的安全性
这个就更水了,在极端情况下,即所有交易都在一个冲突集里的情况下,Avalanche就退化成了Snowball,既然Snowball是安全的,Avalanche肯定也是安全的啦。
活性证明
- Slush: 非BFT协议,一定会在有限轮结束
- Snowflake & Snowball: 拜占庭节点唯一的作恶方式是不回复(因为无法伪造签名),超时后节点会重新选择节点继续发起查询,因此在有限的时间和轮次后一定会结束
- Avalanche: 通过两种机制保证活性
- Eventually good ancestry(最终好祖先):交易可以重新选择父节点然后重试,最终会成功
- Sufficient chits(确保收到足够凭证):节点会检察没有足够子孙的交易,发送空交易触发查询以增加它的置信度。空交易只有一个父节点,并且没有任何副作用
- 最差情况下,退化为Snowball
考虑网络节点变化
网络中的节点有可能随时退出和加入,需要在这种情况下调整系统的配置以保证安全性:
把网络中的操作划分为多个纪元(比如根据区块个数),在每个纪元中有r个节点加入和r’个节点离开。最坏情况下,有r个拜占庭节点加入,有r’个诚实节点退出,按照这种极端情况重新选择网络安全参数,称为一次“view update”。
通信复杂度
- Snowflake & Snowball: O(knlogn) (已被“传染病算法“证明)
- Avalanche: 每个节点O(k), 总复杂度O(kn)
实验结果
论文声称基于Avalanche实现了类似BitCoin的系统,然后跟BitCoin以及Algoran进行了性能对比。
安全参数配置:k=10, α=0.8, β1=11, β2=150
网络配置:2000个节点,36M带宽,20%的拜占庭节点
实验结果:
- BitCoin:3~7 tps,10~60分钟的确认时延
- Algorand:2M区块情况下,159 tps,22秒确认时延 / 10M区块情况下,364 tps,50秒确认时延
- Avalanche:1300+ tps,4.2秒确认时延
文中的最后一段还把目前所有主流和前沿的共识算法都分析了一遍,最后的结论当然是Avalanche完胜,吊打所有渣渣算法,哈哈。
个人总结
这套算法是一个无leader、基于亚稳态、不依赖PoW的拜占庭容错共识协议族。算法本身是非常直观和易懂的,但是个人感觉理论证明部分不是很清晰,很多公式都不知道是从何推导而来的,另外关于安全参数的计算也没有非常严谨的数学公式。如果文中对安全性和活性的证明确实成立的话,这将是一个非常牛逼的算法,或许会对区块链领域产生更强的推进作用。
参考:
https://ipfs.io/ipfs/QmUy4jh5mGNZvLkjies1RWM4YuvJh5o2FYopNPVYwrRVGV.
https://en.wikipedia.org/wiki/Metastability
http://soft-matter.seas.harvard.edu/index.php/Metastable_state
https://zh.coursera.org/lecture/cloud-computing/1-4-safety-and-liveness-sFeOE
https://blog.csdn.net/carmencsdsndsiw9e3f/article/details/70236685
更多文章欢迎关注“鑫鑫点灯”专栏:https://blog.csdn.net/turkeycock