目录
项目的开发经常用到celery后台任务,下面记录下我在项目中用到celery的地方以及自己的一些思考。
使用场景
- 在web开发时有一些耗时的操作需要执行,但是你又不想一直阻塞前端,那么可以尝试使用celery的后台任务,将请求发送到celery后台,然后前端不再阻塞,最后celery后台将任务完成之后将结果返回。用户就可以知道任务是否执行成功。
- 做数据库异步更新,可能要在某个时间点与远程数据库进行同步,更新的时间也比较久,不希望阻塞前端的进程。
代码编写
首先来看一下一个简单的celery后台任务。项目里的部署任务是一个耗时的函数,用户在前端点击了一个部署按钮之后可以执行其他操作,最后会将部署的结果返回给用户,更新任务状态。这里的修饰器是传入了celery任务的上下文。
@celery_ext.celery.task(base=RequestContextTask, ignore_result=True)
def deploy(**kwargs):
"""执行部署任务.
:param task_id: 任务 id
:param update_task_state_url: 更新任务状态通知的 URL
"""
# 更新任务状态
# 执行操作系统安装在全局flask框架入口init,一般在这个文件里我们创建全局的flask对象,然后进行插件初始化,并且注册视图和蓝图。我们初始化了celery_ext,进行插件的初始化
celery_ext = FlaskCeleryExt()
...
def create_app(config)
...
celery_ext.init_app(app)
...再来看下FlaskCeleryExt这个类,主要做的是对象一些初始化工作
class FlaskCeleryExt(object):
"""Flask-Celery extension."""
def __init__(self, app=None, create_celery_app=None):
"""Initialize the Flask-CeleryExt."""
self.create_celery_app = create_celery_app or pkg_create_celery_app
self.celery = None
if app is not None:
self.init_app(app)
def init_app(self, app):
"""Initialize a Flask application."""
# Follow the Flask guidelines on usage of app.extensions
if not hasattr(app, 'extensions'):
app.extensions = {} # pragma: no cover
app.extensions['flask-celeryext'] = self
self.celery = self.create_celery_app(app)当然啦,还有一些配置的工作。我们一般将全局的配置文件写在config.py里面。这里设置了celery broker url 以及一些后台任务的属性配置。也可以在设置BACKEND的URL。我们在setup app的时候会用到这些配置的参数。
class Config(object):
"""框架配置
配置 Flask 所必需的参数,其它系统参数应保存到数据库
"""
# celery
CELERY_BROKER_URL = 'amqp://guest:[email protected]:5672//'
CELERY_TASK_ALWAYS_EAGER = False
CELERY_TASK_EAGER_PROPAGATES_EXCEPTIONS = True在manage.py中添加启动命令行
@manager.option('-l', '--loglevel', dest='loglevel', default='info')
@manager.option('-c', '--concurrency', dest='concurrency', type=int, default=2)
def worker(loglevel='info', concurrency=2):
"""启动后台的 celery worker"""
from celery.apps.worker import Worker
worker_entry = Worker(app=celery, loglevel=loglevel, concurrency=concurrency)
worker_entry.start()最后在运行的时候,命令行需要启动rabbitmq以及celery worker。
# 运行rabbitmq
sudo service rabbitmq start
# 运行celery worker
celery worker -A manage.celery --loglevel=info底层实现
python修饰器
修饰器本身其实是一个python函数,他可以让其他函数在不需要做任何代码改动的前提下增加额外的功能。参数可以是一个函数,返回值也可以是一个函数,好处在于不需要修改原来函数的代码并且为他添加新的功能,也能使一些常用的函数代码模块得到重用,减少冗余度。另外修饰器可以进行叠加。celery用到修饰器的地方是设置celery后台任务的上下文。celery实现
celery是python多任务库来编写的任务队列工具,可以并行地执行一些任务。
python与celery之间使用了消息队列作为中间人来进行任务队列的管理。
中间件的选择可以是rabbitmq也可以是redis,看开发的需求吧。我们项目用的是rabbitmq。
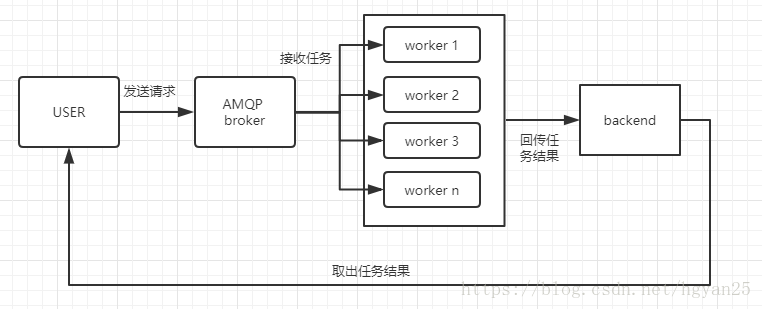
大致的一个逻辑图是这样子的:
worker是执行单元,其实也就是多个线程。
broker是消息中间件,用于接收并暂存消息队列。
backend是保存每次任务的结果。扫描二维码关注公众号,回复: 3393199 查看本文章