版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u013985879/article/details/82856180
一 . 创建工程 >>scrapy startproject xici_proxyip_project
二. 创建spider >> cd xici_proxyip_project
>> scrapy genspider xicispider xicidaili.com
三. Item 编写
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class XiciProxyipProjectItem(scrapy.Item):
# define the fields for your item here like:
IP = scrapy.Field()
PORT = scrapy.Field()
ADDRESS = scrapy.Field() #地址
ANONY = scrapy.Field() #匿名
TYPE = scrapy.Field() #类型
SPEED = scrapy.Field() #速度
ACTIVE_TIME= scrapy.Field() #存活时间
LAST_CHECK_TIME = scrapy.Field()#验证时间四.spider 编写
# -*- coding: utf-8 -*-
import scrapy
import logging
from xici_proxyip_project.items import XiciProxyipProjectItem
log = logging.getLogger()
class XicispiderSpider(scrapy.Spider):
name = 'xicispider'
allowed_domains = ['xicidaili.com']
start_urls = [
'http://xicidaili.com/nn/1',
]
def start_requests(self):
reqs = []
for i in range(1,3):
#加headers,否则返回503
req = scrapy.Request("http://www.xicidaili.com/nn/{}".format(i),headers=
{
'Host': 'www.xicidaili.com',
'Referer': 'http://www.xicidaili.com/nn/{}'.format(i),
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'
}
)
reqs.append(req)
return reqs
def parse(self, response):
xc_items = XiciProxyipProjectItem()
trlist = response.css("table tr")[1:]
#总页数, class = pagination属性的div标签下的不是class=next_page 的a 标签, 有点瑕疵
# totalPage = response.xpath("//div[@class='pagination']/a[not(@class='next_page')]/text()").extract()[-1]
# items = []
for i in trlist:
xc_items["IP"] =i.xpath("td/text()").extract()[0]
xc_items["PORT"] =i.xpath("td/text()").extract()[1]
xc_items["ADDRESS"] = i.xpath('string(td[4])').extract()[0].strip()
xc_items["ANONY"] =i.xpath("td/text()").extract()[4]
xc_items["TYPE"] =i.xpath("td/text()").extract()[5]
xc_items["SPEED"] =i.xpath("td/div/@title").extract()[0]
xc_items["ACTIVE_TIME"] = i.xpath("td/text()").extract()[-2]
xc_items["LAST_CHECK_TIME"] =i.xpath("td/text()").extract()[-1]
# log.info("IP=",xc_items["IP"],",PORT=",xc_items["PORT"],",ADDRESS=",xc_items["ADDRESS"],
# ",ANONY=",xc_items["ANONY"],",TYPE=",xc_items["TYPE"],",SPEED=",xc_items["SPEED"],",ACTIVE_TIME=",xc_items["ACTIVE_TIME"],",LAST_CHECK_TIME=",xc_items["LAST_CHECK_TIME"])
# items.append(xc_items) #用append只会循环输出最后一条数据,用yield
yield xc_items
五. settings 配置
1.把robots.txt 规则关闭
ROBOTSTXT_OBEY = False2. DEFAULT_REQUEST_HEADERS 可以关闭了
六. 编写Pipeline
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json
class XiciProxyipProjectPipeline(object):
def __init__(self):
self.filename=open(r"E:\0802\data\xici.txt","wb")
def process_item(self, item, spider):
text = json.dumps(dict(item),ensure_ascii=False)+"\n"
self.filename.write(text.encode("utf-8"))
def close_spider(self,spider):
self.filename.close()
七.设置settings 关于pipeline 的开关
ITEM_PIPELINES = {
'xici_proxyip_project.pipelines.XiciProxyipProjectPipeline': 300,
}八.运行爬虫
扫描二维码关注公众号,回复:
3389517 查看本文章

>> scrapy crawl xicispider
参考文章,不过有所升级:西刺网站爬虫代码解读
补充:存Mysql
1.conda install pymysql (python 3.X 版本)
2.重新编写pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json
import pymysql
class XiciProxyipProjectPipeline(object):
def __init__(self):
# self.filename=open(r"E:\0802\data\xici.txt","wb")
self.client = pymysql.connect(
host='127.0.0.1',
port=3306,
user='root',
passwd='XXXX',
db='test',
# charset='utf-8'
)
self.cur = self.client.cursor()
def process_item(self, item, spider):
# text = json.dumps(dict(item),ensure_ascii=False)+"\n"
# self.filename.write(text.encode("utf-8"))
# {"IP": "121.31.100.28", "PORT": "8123", "ADDRESS": "广西防城港", "ANONY": "高匿",
# "TYPE": "HTTP", "SPEED": "7.502秒", "ACTIVE_TIME": "827天", "LAST_CHECK_TIME": "18-09-26 12:32"}
sql = 'insert into xicidb(IP,PORT,ADDRESS,ANONY,TYPE,SPEED,ACTIVE_TIME,LAST_CHECK_TIME) VALUES (%s,%s,%s,%s,%s,%s,%s,%s)'
list = (item['IP'],item['PORT'],item['ADDRESS'],item['ANONY'],item['TYPE'],item['SPEED'],item['ACTIVE_TIME'],item['LAST_CHECK_TIME'])
self.cur.execute(sql,list)
self.client.commit()
return item
# def close_spider(self,spider):
# self.filename.close()
3.运行spider >> scrapy crawl xicispider
效果图:

补充:2018年9月28日01:05:33
注意:
1.check the manual that corresponds to your MySQL server version for the right syntax
这种问题一般需要检查一下你的mysql 是不是正确,我就是在最后个 %s 多了个逗号,浪费了些时间排查
2.pymysql.err.InternalError: (1366, "Incorrect string value: '\\xE6\\xB5\\x99\\xE6\\xB1\\x9F...' for column 'ADDRESS' at row 1")
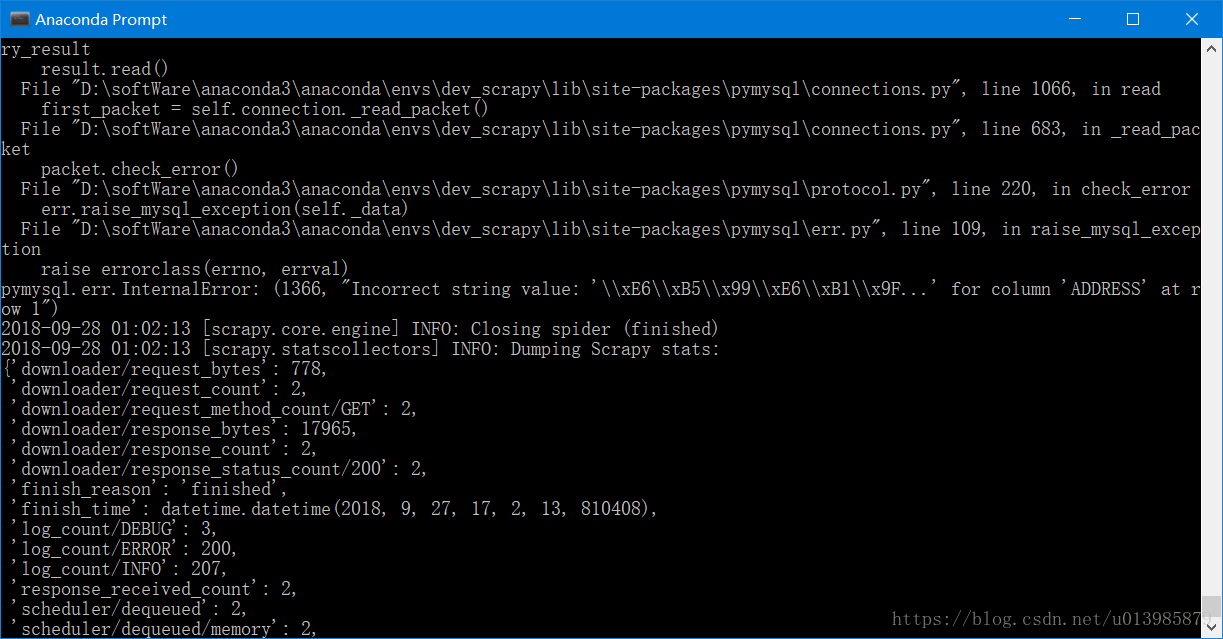
解决方案:
