
什么是动作识别?给定一个视频,通过机器来识别出视频里的主要动作类型。
动作识别表面是简单的分类问题,但从本质上来说,是视频理解问题,很多因素都会影响其中,比如不同类型视频中空间时间信息权重不同?视频长短不一致?视频中动作持续的起始终止时间差异很大?视频对应的语义标签是否模糊?
本文主要对比video-level 动作识别的经典方法TSN,及其拓展变形版本的TRN和ECO。
Temporal Segment Network[1], ECCV2016
TSN提出的背景是当时业界做动作识别都是用Two-stream CNN 和C3D 比较多,它们都有个通病,就是需要密集采样视频帧,比如C3D 中使用的是连续采样间隔的16 frames,这样当输入是个Long视频,计算量很庞大~
故文中就提出了 稀疏时间采样策略 ,就是不管输入视频的长短,直接分成K个Segment,然后在每个Segment再随机找出一个时间小片,分别用shared CNN 来提取空间上的特征,再进行feature-level 的融合,最后再Softmax 分类:
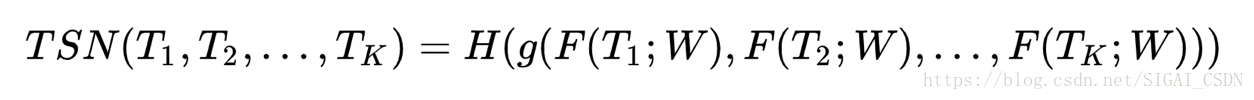
公式中Tk表示第K个Segment;函数F表示CNN网络出来的特征;G表示特征融合函数;H表示分类层Softmax。
整个网络框架图如下,很简洁:
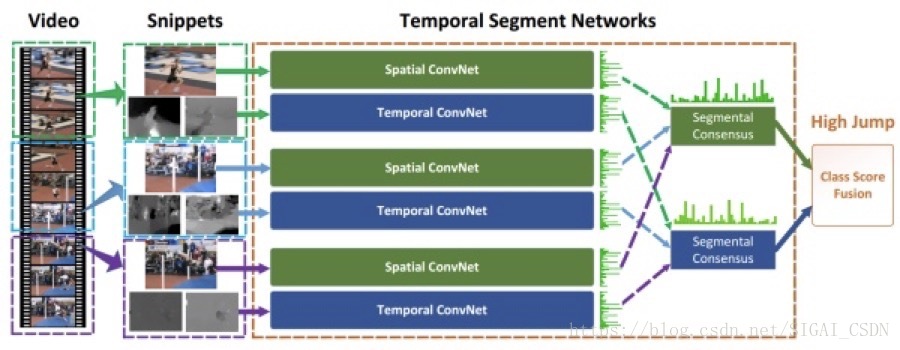
TSN[1]
由于其中没有使用3D conv,故为了更好进行temporal 特征提取,文中也使用了类似双流的多模态输入:即上图的Spatial ConvNet 的输入可以是RGB图 或者RGB差异图;Temporal ConvNet 的输入可以是 光流图 或者wrapped光流:

不同模态输入[1]
从实验结果来看,使用Average fusion去融合特征效果最好;而当使用三模态输入(Optical Flow + Warped Flow + RGB)时,在HMDB51和UCF101超state-of-the-art;不过若只是RGB作为输入的话,性能不如C3D~
总结:
Pros:通过Sparse temporal sampling 可以扔掉很多冗余帧,初步满足实际应用的real-time要求。
Cons: 对于Temporal特征欠考虑,更多地是focus 在apperance feature。文中亦无对比超参K值(Default K=3)的选取对结果的影响 及Segment内部采样小片策略。
Temporal Relation Network[2], ECCV2018
TRN致力于探索时间维度上的关系推理,那问题来了,怎么样才能找到特征间在时间上的传播关系呢?其实像传统的3D conv架构(C3D,P3D,R(2+1)D, I3D),也是有Temporal conv 在里头,也能从不同感受野即multi-temporal-scale来得到联系。本文是在TSN框架上,提出用于video-level的实时时间关系推理框架。
TRN的main contribution 有两个:
- 设计了新型的fusion函数来表征不同temporal segment 的relation,文中是通过MLP( concat feature -- ReLU -- FC -- ReLU -- FC)的结构来实现,而TSN中的fusion函数只是通过简单的average pooling
- 通过时间维度上Multi-scale 特征融合,来提高video-level鲁棒性,起码能抗快速动作和慢速动作干扰。
下图的框架图一目了然,算法实现流程就是先均匀地采样出不同scale的Segment 来对应2-frame, 3-frame, ..., N-frame relation;然后对每个Segment里小片提取Spatial feature,进行MLP 的temporal fusion,送进分类器;最后将不同scale的分类score叠加来作最后预测值。
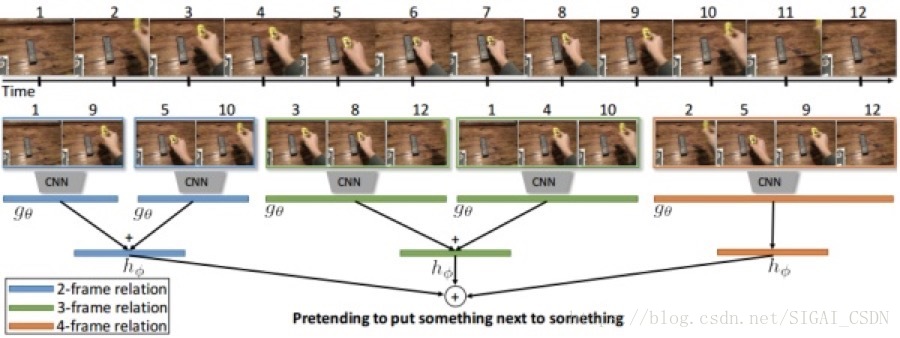
TRN[2]
两个实现的细节点需要注意:
1. 对采样下来的N-frame,必须保持时序性,即从先到后;这样后面的temporal fusion环节MLP才能学会推理动作的时间关系。
2. 不同scale的采样帧对应的MLP 都是独立的,不share参数,因为含的帧数信息量也不同,输入给MLP的大小自然也不同。
文中给出了几个非常有趣的实验结果:
1.如下图所示,在不同的数据集, TRN和TSN的性能差异很大。这说明什么问题呢?在UCF, Kinectics, Moments里两者的性能相近,说明这三个数据集的动作与空间上下文具有强相关性,而对于时间上下文相关性较弱;而Something-something, Jester, Charades 里动作较为复杂,时间上下文联系较强,TRN的性能明显高于TSN
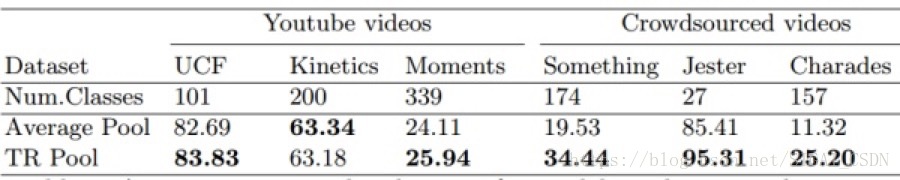
不同的fusion方式在6个数据集上的性能[2]
2. 保持帧间时序对于TRN的重要性,如下图所示,可见乱序输入的TRN在动作复杂的something-something数据集下性能严重下降;而在UCF101里并不严重,因为该数据集需要更多的是空间上下文信息。
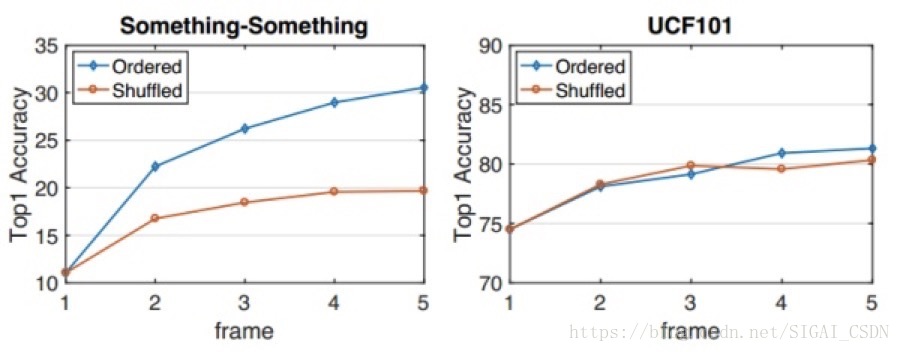
正序和乱序的性能[2]
总结:
Pros:
更鲁棒的action/activity 时空特征表达方式,即MLP fusion + Multi-scale。
Cons:
Spatial 和temporal 的联系还是太少,只在最后embedding feature时用MLP融合了一下~~另应对比不同的fusion方式,如LSTM/GRU与MLP的性能差异~
ECO[3], ECCV2018
本文通过trade-off TSN系列 和3Dconv系列,来实现实时的online video understanding(文中夸张地描述到ECO runs at 675 fps (at 970 fps with ECOLite) on a Tesla P100 GPU)。
ECO的主要贡献:
- 使用TSN 稀疏采样来减少不必要的冗余帧的前提下,对采样帧的mid/high-level 进行spatio-temporal 特征fusion,故比TRN 只在最后特征层来做temporal fusion的时空表达能力更强~
2. 提出了一整套工程化的Online video understanding 框架。
来看看轻量级的ECO-Lite的网络框架图,对N个中的每个Segment中的帧来提取特征到某一层K*28*28,然后通过3D-ResNet(当然拉,这里你也可以使用convLSTM + SPP 等方式来对比下效果) 提取N个Segment的时空特征,最后再分类。
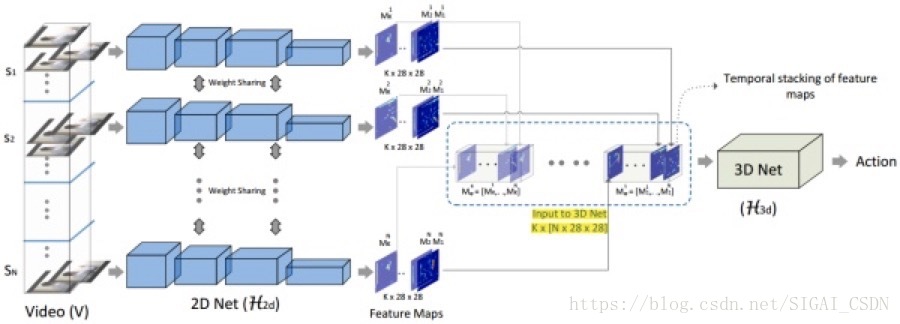
ECO Lite[3]
完整的ECO框架就是在ECO-Lite 的基础上,再接一个类似TSN 的average pooling 的2D 分支,最后再将两个分支特征进行融合及分类:
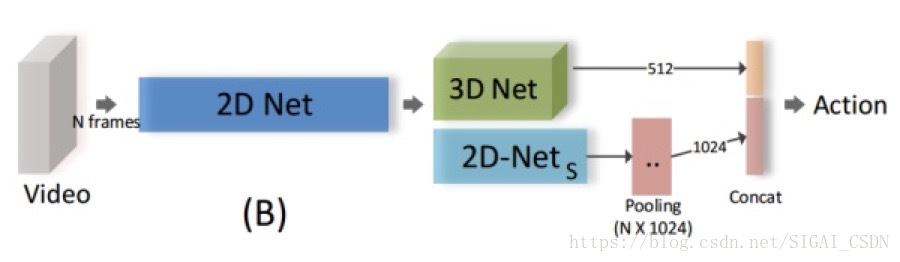
Full ECO[3]
在Something-something数据集下,集成{16, 20, 24, 32} 下采样帧数的四个ECO-Lite子网络的average score的方法,性能远超Multi-scale TRN:

something-something性能[3]
总结与展望:
当硬件的计算能力在上升,且成本下降后,无疑以后通过Sparse sampling后,直接从头到尾进行3Dconv 出来的时空表征会更优 。而这个Sparse sampling,是否可以通过temporal attention去自动选择最优的帧来计算也很重要。
Reference:
[1] Limin Wang, Temporal Segment Networks: Towards Good Practices for Deep Action Recognition, ECCV2016
[2]Bolei Zhou, Temporal Relational Reasoning in Videos,ECCV2018
[3]Mohammadreza Zolfaghari, ECO: Efficient Convolutional Network for Online Video Understanding,ECCV2018
推荐阅读
[1]机器学习-波澜壮阔40年【获取码】SIGAI0413.
[2]学好机器学习需要哪些数学知识?【获取码】SIGAI0417.
[3] 人脸识别算法演化史【获取码】SIGAI0420.
[4]基于深度学习的目标检测算法综述 【获取码】SIGAI0424.
[5]卷积神经网络为什么能够称霸计算机视觉领域?【获取码】SIGAI0426.
[6] 用一张图理解SVM的脉络【获取码】SIGAI0428.
[7] 人脸检测算法综述【获取码】SIGAI0503.
[8] 理解神经网络的激活函数 【获取码】SIGAI2018.5.5.
[9] 深度卷积神经网络演化历史及结构改进脉络-40页长文全面解读【获取码】SIGAI0508.
[10] 理解梯度下降法【获取码】SIGAI0511.
[11] 循环神经网络综述—语音识别与自然语言处理的利器【获取码】SIGAI0515
[12] 理解凸优化 【获取码】SIGAI0518
[13] 【实验】理解SVM的核函数和参数 【获取码】SIGAI0522
[14]【SIGAI综述】行人检测算法 【获取码】SIGAI0525
[15] 机器学习在自动驾驶中的应用—以百度阿波罗平台为例(上)【获取码】SIGAI0529
[16]理解牛顿法【获取码】SIGAI0531
[17] 【群话题精华】5月集锦—机器学习和深度学习中一些值得思考的问题【获取码】SIGAI 0601
[18] 大话Adaboost算法 【获取码】SIGAI0602
[19] FlowNet到FlowNet2.0:基于卷积神经网络的光流预测算法【获取码】SIGAI0604
[20] 理解主成分分析(PCA)【获取码】SIGAI0606
[21] 人体骨骼关键点检测综述 【获取码】SIGAI0608
[22]理解决策树 【获取码】SIGAI0611
[23] 用一句话总结常用的机器学习算法【获取码】SIGAI0611
[24] 目标检测算法之YOLO 【获取码】SIGAI0615
[25] 理解过拟合 【获取码】SIGAI0618
[26]理解计算:从√2到AlphaGo ——第1季从√2谈起 【获取码】SIGAI0620
[27] 场景文本检测——CTPN算法介绍 【获取码】SIGAI0622
[28] 卷积神经网络的压缩和加速 【获取码】SIGAI0625
[29] k近邻算法 【获取码】SIGAI0627
[30]自然场景文本检测识别技术综述 【获取码】SIGAI0627
[31] 理解计算:从√2到AlphaGo ——第2季神经计算的历史背景 【获取码】SIGAI0704
[32] 机器学习算法地图【获取码】SIGAI0706
[33] 反向传播算法推导-全连接神经网络【获取码】SIGAI0709
[34] 生成式对抗网络模型综述【获取码】SIGAI0709.
[35]怎样成为一名优秀的算法工程师【获取码】SIGAI0711.
[36] 理解计算:从根号2到AlphaGo——第三季神经网络的数学模型【获取码】SIGAI0716
[37]【技术短文】人脸检测算法之S3FD 【获取码】SIGAI0716
[38] 基于深度负相关学习的人群计数方法【获取码】SIGAI0718
[39] 流形学习概述【获取码】SIGAI0723
[40] 关于感受野的总结 【获取码】SIGAI0723
[41] 随机森林概述 【获取码】SIGAI0725
[42] 基于内容的图像检索技术综述——传统经典方法【获取码】SIGAI0727
[43] 神经网络的激活函数总结【获取码】SIGAI0730
[44] 机器学习和深度学习中值得弄清楚的一些问题【获取码】SIGAI0802
[45] 基于深度神经网络的自动问答系统概述【获取码】SIGAI0803
[46] 反向传播算法推导——卷积神经网络 【获取码】SIGAI0806
[47] 机器学习与深度学习核心知识点总结写在校园招聘即将开始时 【获取码】SIGAI0808
[48] 理解Spatial Transformer Networks【获取码】SIGAI0810
[49]AI时代大点兵-国内外知名AI公司2018年最新盘点【获取码】SIGAI0813
[50] 理解计算:从√2到AlphaGo ——第2季神经计算的历史背景 【获取码】SIGAI0815
[51] 基于内容的图像检索技术综述--CNN方法 【获取码】SIGAI0817
[52]文本表示简介 【获取码】SIGAI0820
[53]机器学习中的最优化算法总结【获取码】SIGAI0822
[54]【AI就业面面观】如何选择适合自己的舞台?【获取码】SIGAI0823
[55]浓缩就是精华-SIGAI机器学习蓝宝书【获取码】SIGAI0824
[56]DenseNet详解【获取码】SIGAI0827
[57]AI时代大点兵国内外知名AI公司2018年最新盘点【完整版】【获取码】SIGAI0829
[58]理解Adaboost算法【获取码】SIGAI0831
[59]深入浅出聚类算法【获取码】SIGAI0903
[60]机器学习发展历史回顾【获取码】SIGAI0905
[61] 网络表征学习综述【获取码】SIGAI0907
[62]视觉多目标跟踪算法综述(上)【获取码】SIGAI0910
[63] 计算机视觉技术self-attention最新进展【获取码】SIGAI0912
[64] 理解Logistic回归【获取码】SIGAI0914
[65] 机器学习中的目标函数总结【获取码】SIGAI0917
[66] 人脸识别中的活体检测算法综述【获取码】SIGAI0919
[67] 机器学习与深度学习常见面试题(上)【获取码】SIGAI0921
原创声明:本文为SIGAI 原创文章,仅供个人学习使用,未经允许,不能用于商业目的