Java 8新增的日期、时间API不仅包括了Instant、LocalDate、LocalDateTime、LocalTime等代表日期、时间的类,而且在java.time.format包下提供了一个DateTimeFormater格式器类,该类相当于前面介绍的DateFormat和SimpleDateFormat的合体,功能非常强大。
与DateFormat和SimpleDateFormat类似,DateTimeFormatter不仅可以将日期,时间对象格式化成字符串,也可以将特定格式的字符串解析成日期,时间对象。
为了使用DateTimeFormatter进行格式化或解析,必须先获取DateTimeFormattr对象,获取DateTimeFormatter对象有如下三种常见的方式。
①直接使用静态常量来创建DateTimeFormatter格式器。DateTimeFormatter类中包含了大量的形如ISO_LOCAL_DATE、ISO_LOCAL_TIME、ISO_LOCAL_DATE_TIME等静态常量,这些静态常量本身就是DateFormatter实例。
②使用代表不同风格的枚举值来创建DateTimeFormatter格式器。在FormatStyle风格类中定义了FULL、LONG、MEDIUM、SHORT四个枚举值,它们代表日期、时间的不同风格。
③根据模式字符串来创建DateFormat格式器。类似于SimpleDateFormat,可以采用模式字符串来创建DateFormat。
备注:
1.Date类是一个设计很糟糕的类,因此java官方推荐尽量少用Date的构造器和方法,推荐使用Calendar工具类;
2.simpledateformate 在 java.text包下,实例可变,存在线程安全问题;
3.time 遵循的时iso-8601标准,每次使用都是全新的实例,所以不存在线程安全问题;
Calendar
因为Date类在设计上存在一些缺陷,所以Java提供了Calendar类来更好地处理日期和时间。Calendar是一个抽象类,它用于表示日历。
历史上有着许多种纪年方法,它的差异实在太大了。为了统一计时,全世界通常选择最普及、最通用的日历:Gregorian Calendar,也就是日常介绍年份时常用的“公元几几年”。alendar类是一个抽象类,所以不能使用构造器来创建Calendar对象。但它提供了几个静态getInstance()方法来获取Calendar对象,这些方法根据TimeZone,Locale类来获取特定的Calendar,如果不指定TimeZone、Locale,则使用了默认的TimeZone、Locale来创建Calendar。
Calendar与Date都是表示日期的工具类,它们直接可以自由转换。
//创建一个默认的Calendar对象
Calendar calendar = Calendar.getInstance();
//从Calendar对象中取出Date对象
Date date = calendar.getTime();
//通过Date对象获得对应的Calendar对象
//因为Calendar/GregorianCalendar实例,然后调用其setTime()方法
Calendar instance2 = Calendar.getInstance();
instance2.setTime(date);
System.out.println(calendar);
System.out.println(instance2);测试结果:
java.util.GregorianCalendar[time=1534301717368,areFieldsSet=true,areAllFieldsSet=true,lenient=true,zone=sun.util.calendar.ZoneInfo[id="Asia/Shanghai",offset=28800000,dstSavings=0,useDaylight=false,transitions=19,lastRule=null],firstDayOfWeek=1,minimalDaysInFirstWeek=1,ERA=1,YEAR=2018,MONTH=7,WEEK_OF_YEAR=33,WEEK_OF_MONTH=3,DAY_OF_MONTH=15,DAY_OF_YEAR=227,DAY_OF_WEEK=4,DAY_OF_WEEK_IN_MONTH=3,AM_PM=0,HOUR=10,HOUR_OF_DAY=10,MINUTE=55,SECOND=17,MILLISECOND=368,ZONE_OFFSET=28800000,DST_OFFSET=0]
java.util.GregorianCalendar[time=1534301717368,areFieldsSet=true,areAllFieldsSet=true,lenient=true,zone=sun.util.calendar.ZoneInfo[id="Asia/Shanghai",offset=28800000,dstSavings=0,useDaylight=false,transitions=19,lastRule=null],firstDayOfWeek=1,minimalDaysInFirstWeek=1,ERA=1,YEAR=2018,MONTH=7,WEEK_OF_YEAR=33,WEEK_OF_MONTH=3,DAY_OF_MONTH=15,DAY_OF_YEAR=227,DAY_OF_WEEK=4,DAY_OF_WEEK_IN_MONTH=3,AM_PM=0,HOUR=10,HOUR_OF_DAY=10,MINUTE=55,SECOND=17,MILLISECOND=368,ZONE_OFFSET=28800000,DST_OFFSET=0]
Calendar类提供了大量访问,修改日期时间的方法,常用方法如下:
1. void add(int field,int amount):根据日历的规则,为给定的日历字段添加或减去指定的时间量。
2.int get(int field):返回指定日历字段的值。
3.int getActualMaximun(int field): 返回指定日历字段可能拥有的最大值。例如月,最大值为11.
4.int getActualMinimun(int field):返回指定日历字段可能拥有的最小值。例如月,最小值为0.
5.void roll(int field,int amount):与add()方法类似,区别在于加上amount后超多了该字段所能表示的最大范围时,也不会向上一个字段进位。
6.void set(int field,int value):将给定的日历字段设置为给定值。
7.void set(int year,int month,int date):设置Calendar对象的年,月,日三个字段的值。
8.void set(int year,int month,int date,int hourOfDay,int minute,int second):设置Calendar对象的年,月,日,时,分,秒6个字段的值。
上面的很多方法都需要一个int类型的field参数,field是Calendar类的类变量,如Calendar.YEAR,Calendar.MONTH等分别表示了年,月,日,小时,分钟,秒等时间字段。
注意:Calendar.MONTH子弹代表月份,月份的起始值不是1,而是0,所以设置8月时,用7而不是8.
Calendar calendar = Calendar.getInstance();
//取出年
System.out.println(calendar.get(Calendar.YEAR));
//取出月
System.out.println(calendar.get(Calendar.MONTH));
//取出日
System.out.println(calendar.get(Calendar.DATE));
//分别设置年月日小时分钟 秒
calendar.set(2003,10,23,12,32,23);
System.out.println(calendar.getTime());
//将Calendar的年前推1年
calendar.add(Calendar.YEAR,-1);
System.out.println(calendar.getTime());
//将Calendar的月前推8个月
calendar.roll(Calendar.MONTH,-8);
System.out.println(calendar.getTime());2018
7
15
Sun Nov 23 12:32:23 CST 2003
Sat Nov 23 12:32:23 CST 2002
Sat Mar 23 12:32:23 CST 2002
Calendar类还有如下几个注意点:
1.add与roll的区别
add(int field,int amount)的功能非常强大,add主要用于改变Calendar的特定字段的值。如果需要增加某字段的值,则让amount为正数;如果需要减少某字段的值,则让amount为负数即可。
注意:1.1当被修改的字段超出它允许的范围时,会发生进位,即上一级字段也会增大。例如:
Calendar c = Calendar.getInstance();
c.set(2003,7,23,0,0,0);//2003-8-23
c.add(Calendar.MONTH,6);//2003-8-23=>2004-2-231.2如果下一级字段也需要改变,那么该字段会修正到变化最小的值。例如:
Calendar cal2 = Calendar.getInstance();
cal2.set(2003,7,31,0,0,0);//2003-8-31
//因为进位后月份改为2月,2月没有31日,自动变为29日
cal2.add(Calendar.MONTH,6);//2003-8-31=>2004-2-29 对于上面的例子,8-31就会变成2-29.因为Month的下一级字段时DATE,从31到29改变最小。所以上面2003-8-31的MONTH字段增加6后,不是变成2004-3-2而是变成2004-2-29.
roll()规则与add()的处理规则不同:当被修改的字段超出它允许的范围时,上一级字段不会增大
Calendar cal3 = Calendar.getInstance();
cal3.set(2003,7,23,0,0,0);//2003-8-23
//Month字段“进位”,但YEAR字段并不增加
cal3.roll(Calendar.MONTH,6);//2003-8-23下一级子段的处理规则与add()相似:
Calendar cal4 = Calendar.getInstance();
cal4.set(2003,7,31,0,0,0);//2003-8-31
//MONTH字段“进位”后变成2,2月没有31日
//YEAR字段不会改变,2003年2月只有28日
cal4.roll(Calendar.MONTH,6);//2003-8-31=>2003-2-282.设置Calendar的容错性
调用Calendar对象的set()方法来改变指定时间字段的值时,由可能传入一个不合法的参数,例如为MONTH字段设置13,这将会导致怎样的后果那?看如下程序。
Calendar cal = Calendar.getInstance();
//结果时YEAR字段为1,MONTH字段为1(2月)
cal.set(Calendar.MONTH,13);//1
System.out.println(cal.getTime());
//关闭容错性
cal.setLenient(false);
//导致运行时异常
cal.set(Calendar.MONTH,13);//2
System.out.println(cal.getTime());Calendar提供了一个setLenient()用于设置它的容错性,Calendar默认支持较好的容错性,通过setLenient(false)可以关闭Calendar的容错性,让它进行严格的参数检查。
Calendar有两种解释日历字段的模式: lenient模式和non-lenient模式。
lenient模式:当Calendar处于lenient模式时,每个时间字段可接受超出它允许范围的值;
non-lenient模式:当Calendar处于non-lenient模式时,如果为某个时间字段设置的值超过了它允许的取值范围,程序将会抛出异常。
3.set()方法延迟修改
set(f,value)方法将日历字段f更改为value,此外它还设置了一个内部成员变量,以指示日历字段已经被更改。
尽管日历字段f是立即更改的,但该Calendar所代表的时间却不会立即修改,直到下次调用get()、getTime()、getTimeInMillis()、add()或roll()时才会重新计算日历的时间。
这被称为set()方法的延迟修改,采用延迟修改的优势就是多次调用set()不会触发多次不必要的计算(需要计算出一个代表实际时间的long型整数。
Calendar cal = Calendar.getInstance();
//结果时YEAR字段为1,MONTH字段为1(2月)
cal.set(Calendar.MONTH,13);//1
System.out.println(cal.getTime());
//关闭容错性
cal.setLenient(false);
//导致运行时异常
cal.set(Calendar.MONTH,13);//2
System.out.println(cal.getTime());如果程序员将①处代码注释起来,因为Calendar的set()方法具有延迟修改的特性,即调用set()方法后Calendar实际上并未计算真实的日期,它只是使用内部成员变量记录MONTH字段被修改为8,接着程序设置DATE字段为5,程序内部再次记录DATE字段为5——也就是9月5日。因此看到③处输出2003-9-5。
使用LocalDate、LocalTime、LocalDateTime
LocalDate、LocalTime、LocalDateTime 类的实例是不可变的对象,分别表示使用ISO-8601日历系统的日期、时间、日期和时间。它们提供了简单的日期或时间,并不包含当前的时间信息。也不包含与时区相关的信息。
注:ISO-8601日历系统是国际标准化组织制定的现代公民的日期和时间的表示法
1. LocalDate、LocalTime、LocalDateTime
LocalDateTime ldt = LocalDateTime.now();
System.out.println(ldt);
System.out.println(ldt.getYear());
System.out.println(ldt.getMonthValue());
System.out.println(ldt.getDayOfMonth());
LocalDateTime ld2 = LocalDateTime.of(2018, 8, 29, 8, 8, 20);
System.out.println(ld2);
LocalDateTime ld3 = ld2.plusYears(2);
System.out.println(ld3);
LocalDateTime ld4 = ld2.minusMonths(2);
System.out.println(ld4);2018-08-14T20:40:09.793
2018
8
14
2018-08-29T08:08:20
2020-08-29T08:08:20
2018-06-29T08:08:20
DateTimeFormatter[] formatters = new DateTimeFormatter[]{
//直接使用常量创建 DateTimerFormatter 格式器
DateTimeFormatter.ISO_LOCAL_DATE,
DateTimeFormatter.ISO_LOCAL_TIME,
DateTimeFormatter.ISO_LOCAL_DATE_TIME,
//使用本地化的不同风格来创建DateTimeFormatter格式器
DateTimeFormatter.ofLocalizedDateTime(FormatStyle.FULL, FormatStyle.MEDIUM),
DateTimeFormatter.ofLocalizedTime(FormatStyle.LONG),
//根据模式化字符串来创建DateTimeFormatter 格式器
DateTimeFormatter.ofPattern("Gyyyy%%MMM%%dd HH:mm:ss")
};
LocalDateTime date = LocalDateTime.now();
//依次使用不同的格式器对 LocalDateTime 进行格式化
for (int i = 0; i < formatters.length; i++) {
//下面两行代码的作用时间
System.out.println(date.format(formatters[i]));
System.out.println(formatters[i].format(date));
System.out.println("------------------");
}2018-08-14
2018-08-14
------------------
13:46:38.928
13:46:38.928
------------------
2018-08-14T13:46:38.928
2018-08-14T13:46:38.928
------------------
Disconnected from the target VM, address: '127.0.0.1:7850', transport: 'socket'
2018年8月14日 星期二 13:46:38
2018年8月14日 星期二 13:46:38
------------------
下午01时46分38秒
下午01时46分38秒
------------------
公元2018%%八月%%14 13:46:38
公元2018%%八月%%14 13:46:38
------------------
//定义一个任意格式的日期,时间字符串
String str1="2014==04==12 01时06分09秒";
//根据需要解析的日期,时间字符串定义解析所用的格式器
DateTimeFormatter formatter=DateTimeFormatter.ofPattern("yyyy==MM==dd HH时mm分ss秒");
//执行解析
LocalDateTime dt1 = LocalDateTime.parse(str1, formatter);
System.out.println(dt1); //输出2014-04-12T01:06:09
//---下面代码再次解析另一个字符串---
String str2="2014$$$四月$$$13 20小时";
DateTimeFormatter formatter2=DateTimeFormatter.ofPattern("yyyy$$$MMM$$$dd HH小时");
LocalDateTime dt2=LocalDateTime.parse(str2,formatter2);
System.out.println(dt2); //输出 2014-04-13T20:00
2. Instant : 时间戳 (使用 Unix 元年 1970年1月1日 00:00:00 所经历的毫秒值)
Instant ins = Instant.now();//默认使用 UTC 时区
System.out.println(ins);
OffsetDateTime odt = ins.atOffset(ZoneOffset.ofHours(8));
System.out.println(odt);
System.out.println(ins.getNano());
Instant ins2 = Instant.ofEpochSecond(5);
System.out.println(ins2);2018-08-14T12:48:15.599Z
2018-08-14T20:48:15.599+08:00
599000000
1970-01-01T00:00:05Z
3.Duration : 用于计算两个“时间”间隔
Period : 用于计算两个“日期”间隔
Instant ins1 = Instant.now();
System.out.println("--------");
Thread.sleep(1000);
Instant ins2 = Instant.now();
System.out.println("所耗费的时间为:"+ Duration.between(ins1,ins2));
System.out.println("--------");
LocalDate ld1 = LocalDate.now();
LocalDate ld2 = LocalDate.of(2011, 1, 1);
Period pe = Period.between(ld1, ld2);
System.out.println(pe.getYears());
System.out.println(pe.getMonths());
System.out.println(pe.getDays());--------
所耗费的时间为:PT1S
--------
-7
-7
-13
4. TemporalAdjuster : 时间校正器
LocalDateTime ldt = LocalDateTime.now();
System.out.println(ldt);//当前日期时间
LocalDateTime ldt2 = ldt.withDayOfMonth(10);//设置为当月10号
System.out.println(ldt2);
//获取下个周末
LocalDateTime ldt3 = ldt.with(TemporalAdjusters.next(DayOfWeek.SUNDAY));
System.out.println(ldt3);
//自定义:下一个工作日
LocalDateTime ldt5 = ldt.with((l) -> {
LocalDateTime ldt4 = (LocalDateTime) l;
DayOfWeek dow = ldt4.getDayOfWeek();
if(dow.equals(DayOfWeek.FRIDAY)){
return ldt4.plusDays(3);
}else if(dow.equals(DayOfWeek.SATURDAY)){
return ldt4.plusDays(2);
}else{
return ldt4.plusDays(1);
}
});
System.out.println(ldt5);2018-08-14T21:15:59.661
2018-08-10T21:15:59.661
2018-08-19T21:15:59.661
2018-08-15T21:15:59.661
5. DateTimeFormatter : 解析和格式化日期或时间
DateTimeFormatter dtf = DateTimeFormatter.ofPattern("yyyy年MM月dd日 HH:mm:ss");
LocalDateTime ldt = LocalDateTime.now();
String strDate = ldt.format(dtf);
System.out.println(strDate);
LocalDateTime newLdt = ldt.parse(strDate, dtf);
System.out.println(strDate);2018年08月14日 21:23:31
2018年08月14日 21:23:31
6.获取时区
Set<String> set = ZoneId.getAvailableZoneIds();
set.forEach(System.out::println); Asia/Aden
America/Cuiaba
Etc/GMT+9
Etc/GMT+8
Africa/Nairobi
------------------
6.ZonedDate、ZonedTime、ZonedDateTime : 带时区的时间或日期 LocalDateTime ldt = LocalDateTime.now(ZoneId.of("Asia/Shanghai"));
System.out.println(ldt);
ZonedDateTime zdt = ZonedDateTime.now(ZoneId.of("US/Pacific"));
System.out.println(zdt);2018-08-14T21:28:13.730
2018-08-14T06:28:13.732-07:00[US/Pacific]
二.新增Steam流API
流(Stream) 到底是什么呢?
是数据渠道,用于操作数据源(集合、数组等)所生成的元素序列。“集合讲的是数据,流讲的是计算!”
注意:
①Stream 自己不会存储元素。
②Stream 不会改变源对象。相反,他们会返回一个持有结果的新Stream。
③Stream 操作是延迟执行的。这意味着他们会等到需要结果的时候才执行。
Stream 的操作三个步骤
2.1. 创建 Stream
一个数据源(如:集合、数组),获取一个流,Java8 中的Collection 接口被扩展,提供了两个获取流的方法:
可以使用静态方法Stream.iterate() 和Stream.generate(), 创建无限流。
//1. Collection 提供了两个方法 stream() 与 parallelStream()
ArrayList<String> list = new ArrayList<>();
Stream<String> stream = list.stream(); //获取一个顺序流
Stream<String> parallelStream = list.parallelStream(); //获取一个并行流
//2.通过Arrays中的steam()获取一个数组流
Integer[] nums = new Integer[10];
Stream<Integer> stream1 = Arrays.stream(nums);
//3.通过stream类中静态方法of()
Stream<Integer> stream2 = Stream.of(1, 2, 3, 4, 5, 6);
//4.创建无限流
//迭代
Stream<Integer> stream3 = Stream.iterate(0, (x) -> x + 2).limit(10);
stream3.forEach(System.out::println);
//生成
Stream<Double> stream4 = Stream.generate(Math::random).limit(2);
stream4.forEach(System.out::println);2.2. 中间操作
一个中间操作链,对数据源的数据进行处理,多个中间操作可以连接起来形成一个流水线,除非流水线上触发终止操作,否则中间操作不会执行任何的处理,而在终止操作时一次性全部处理,称为“惰性求值”。
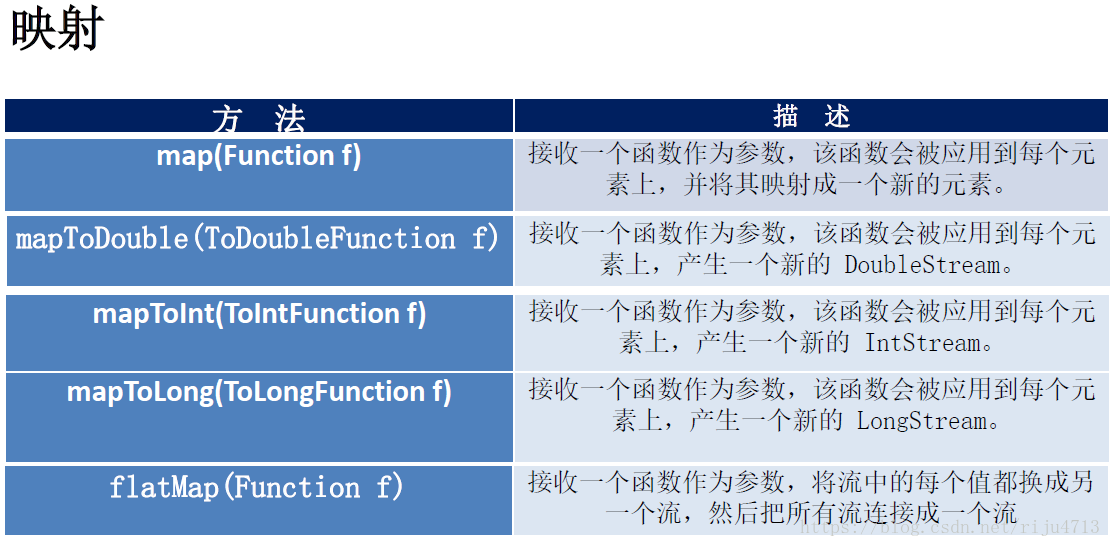
映射
map——接收 Lambda , 将元素转换成其他形式或提取信息。接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。
flatMap——接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流
2.2.1. 筛选与切片
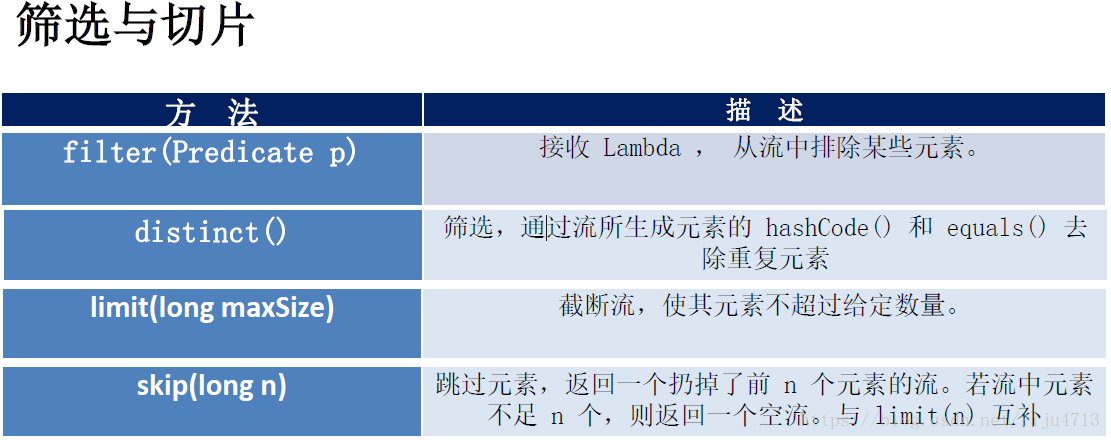
filter——接收 Lambda , 从流中排除某些元素。
limit——截断流,使其元素不超过给定数量。
skip(n) —— 跳过元素,返回一个扔掉了前 n 个元素的流。若流中元素不足 n 个,则返回一个空流。与 limit(n) 互补
distinct——筛选,通过流所生成元素的 hashCode() 和 equals() 去除重复元素
2.2.2. 内部迭代:迭代操作 Stream API 内部完成
List<Employee> emps = Arrays.asList(
new Employee(102, "李四", 59, 6666.66),
new Employee(101, "张三", 18, 9999.99),
new Employee(103, "王五", 28, 3333.33),
new Employee(104, "赵六", 8, 7777.77),
new Employee(104, "赵六", 8, 7777.77),
new Employee(104, "赵六", 8, 7777.77),
new Employee(105, "田七", 38, 5555.55)
);
//所有的中间操作不会做任何的处理
Stream<Employee> stream = emps.stream()
.filter((e) -> {
System.out.println("测试中间操作");
return e.getAge() <= 35;
});
//只有当做终止操作时,所有的中间操作会一次性的全部执行,成为"惰性求值"
stream.forEach(System.out::println);测试中间操作
测试中间操作
Employee [id=101, name=张三, age=18, salary=9999.99, status=null]
测试中间操作
Employee [id=103, name=王五, age=28, salary=3333.33, status=null]
测试中间操作
Employee [id=104, name=赵六, age=8, salary=7777.77, status=null]
测试中间操作
Employee [id=104, name=赵六, age=8, salary=7777.77, status=null]
测试中间操作
Employee [id=104, name=赵六, age=8, salary=7777.77, status=null]
测试中间操作
2.2.3.外部迭代
Iterator<Employee> it = emps.iterator();
while (it.hasNext()){
System.out.println(it.next());
}Employee [id=102, name=李四, age=59, salary=6666.66, status=null]
Employee [id=101, name=张三, age=18, salary=9999.99, status=null]
Employee [id=103, name=王五, age=28, salary=3333.33, status=null]
Employee [id=104, name=赵六, age=8, salary=7777.77, status=null]
Employee [id=104, name=赵六, age=8, salary=7777.77, status=null]
Employee [id=104, name=赵六, age=8, salary=7777.77, status=null]
Employee [id=105, name=田七, age=38, salary=5555.55, status=null]
2.2.4 limit的使用
emps.stream().filter((e)->{
System.out.println("短路!");// && ||
return e.getSalary()>=5000;
}).limit(3).forEach(System.out ::println); 短路!
Employee [id=102, name=李四, age=59, salary=6666.66, status=null]
短路!
Employee [id=101, name=张三, age=18, salary=9999.99, status=null]
短路!
短路!
Employee [id=104, name=赵六, age=8, salary=7777.77, status=null]
2.2.5 skip的使用
emps.parallelStream().filter((e)->e.getSalary()>=5000).skip(5).forEach(System.out::println);Employee [id=105, name=田七, age=38, salary=5555.55, status=null]
2.2.6 distinct的使用
emps.stream().distinct().forEach(System.out::println);Employee [id=102, name=李四, age=59, salary=6666.66, status=null]
Employee [id=101, name=张三, age=18, salary=9999.99, status=null]
Employee [id=103, name=王五, age=28, salary=3333.33, status=null]
Employee [id=104, name=赵六, age=8, salary=7777.77, status=null]
Employee [id=105, name=田七, age=38, salary=5555.55, status=null]
2.2.7 sorted的使用

emps.stream().map(Employee::getName).sorted().forEach(System.out::println);
System.out.println("----------------------");
emps.stream().sorted((x, y) -> {
if (x.getAge() == y.getAge()) {
return x.getName().compareTo(y.getName());
} else {
return Integer.compare(x.getAge(), y.getAge());
}
}).forEach(System.out::println);张三
李四
王五
田七
赵六
赵六
赵六
----------------------
Employee [id=104, name=赵六, age=8, salary=7777.77, status=null]
Employee [id=104, name=赵六, age=8, salary=7777.77, status=null]
Employee [id=104, name=赵六, age=8, salary=7777.77, status=null]
Employee [id=101, name=张三, age=18, salary=9999.99, status=null]
Employee [id=103, name=王五, age=28, salary=3333.33, status=null]
Employee [id=105, name=田七, age=38, salary=5555.55, status=null]
Employee [id=102, name=李四, age=59, salary=6666.66, status=null]
2.3. 终止操作(终端操作)
一个终止操作,执行中间操作链,并产生结果
终端操作会从流的流水线生成结果。其结果可以是任何不是流的值,例如:List、Integer,甚至是void 。

2.3.1
allMatch——检查是否匹配所有元素
anyMatch——检查是否至少匹配一个元素
noneMatch——检查是否没有匹配的元素
findFirst——返回第一个元素
findAny——返回当前流中的任意元素
count——返回流中元素的总个数
max——返回流中最大值
min——返回流中最小值
boolean b1 = emps.stream().allMatch((e) -> e.getStatus().equals(Employee.Status.BUSY));
System.out.println(b1);
boolean b11 = emps.stream().anyMatch((e) -> e.getStatus().equals(Employee.Status.BUSY));
System.out.println(b11);
boolean b12 = emps.stream().noneMatch((e) -> e.getStatus().equals(Employee.Status.BUSY));
System.out.println(b12);false
true
false
Optional<Employee> op2 = emps.parallelStream().filter((e) -> e.getStatus().equals(Employee.Status.FREE)).findAny();
System.out.println(op2.get()); long count = emps.stream().filter((e) -> e.getStatus().equals(Employee.Status.FREE)).count();
System.out.println(count);
Optional<Double> op = emps.stream().map(Employee::getSalary).max(Double::compare);
System.out.println(op.get());
Optional<Employee> op2 = emps.stream().min((e1, e2) -> Double.compare(e1.getSalary(), e2.getSalary()));
System.out.println(op2.get());3
9999.99
Employee [id=103, name=王五, age=28, salary=3333.33, status=VOCATION]
注意:流进行了终止操作后,不能再次使用 Stream<Employee> stream = emps.stream().filter((e) -> e.getStatus().equals(Employee.Status.FREE));
long count = stream.count();//
stream.map(Employee::getSalary).max(Double::compareTo);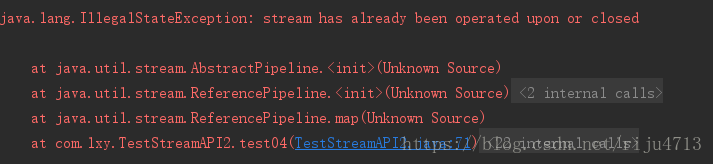
2.3.2 归约
reduce(T identity, BinaryOperator) / reduce(BinaryOperator) ——可以将流中元素反复结合起来,得到一个值。

备注:map 和reduce 的连接通常称为map-reduce 模式,因Google 用它来进行网络搜索而出名。
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
Integer sum = list.stream().reduce(0, (x, y) -> x + y);
System.out.println(sum);
System.out.println("--------------------");
Optional<Double> op = emps.stream().map(Employee::getSalary).reduce(Double::sum);
System.out.println(op.get()); 55
--------------------
48888.84000000001
2.3.2 分组
根据状态分组:
Map<Employee.Status, List<Employee>> map = emps.stream().collect(Collectors.groupingBy(Employee::getStatus));
System.out.println(map);{VOCATION=[Employee [id=103, name=王五, age=28, salary=3333.33, status=VOCATION]], FREE=[Employee [id=101, name=张三, age=18, salary=9999.99, status=FREE], Employee [id=104, name=赵六, age=8, salary=7777.77, status=FREE], Employee [id=104, name=赵六, age=8, salary=7777.77, status=FREE]], BUSY=[Employee [id=102, name=李四, age=79, salary=6666.66, status=BUSY], Employee [id=104, name=赵六, age=8, salary=7777.77, status=BUSY], Employee [id=105, name=田七, age=38, salary=5555.55, status=BUSY]]}
根据工资是否大于5000分组:
Map<Boolean, List<Employee>> map = emps.stream().collect(Collectors.partitioningBy((e) -> e.getSalary() >= 5000));
System.out.println(map);{false=[Employee [id=103, name=王五, age=28, salary=3333.33, status=VOCATION]], true=[Employee [id=102, name=李四, age=79, salary=6666.66, status=BUSY], Employee [id=101, name=张三, age=18, salary=9999.99, status=FREE], Employee [id=104, name=赵六, age=8, salary=7777.77, status=BUSY], Employee [id=104, name=赵六, age=8, salary=7777.77, status=FREE], Employee [id=104, name=赵六, age=8, salary=7777.77, status=FREE], Employee [id=105, name=田七, age=38, salary=5555.55, status=BUSY]]}
多级分组
Map<Employee.Status, Map<String, List<Employee>>> map = emps.stream().collect(Collectors.groupingBy(Employee::getStatus, Collectors.groupingBy((e) -> {
if (e.getAge() >= 60) {
return "老年";
} else if (e.getAge() >= 35) {
return "中年";
} else {
return "成年";
}
})));
System.out.println(map);{FREE={成年=[Employee [id=101, name=张三, age=18, salary=9999.99, status=FREE], Employee [id=104, name=赵六, age=8, salary=7777.77, status=FREE], Employee [id=104, name=赵六, age=8, salary=7777.77, status=FREE]]}, BUSY={成年=[Employee [id=104, name=赵六, age=8, salary=7777.77, status=BUSY]], 老年=[Employee [id=102, name=李四, age=79, salary=6666.66, status=BUSY]], 中年=[Employee [id=105, name=田七, age=38, salary=5555.55, status=BUSY]]}, VOCATION={成年=[Employee [id=103, name=王五, age=28, salary=3333.33, status=VOCATION]]}}

Collector 接口中方法的实现决定了如何对流执行收集操作(如收集到List、Set、Map)。但是Collectors 实用类提供了很多静态方法,可以方便地创建常见收集器实例,具体方法与实例如下表:


collect——将流转换为其他形式。接收一个 Collector接口的实现,用于给Stream中元素做汇总的方法
List<String> list = emps.stream().map(Employee::getName).collect(Collectors.toList());
list.forEach(System.out::println);
System.out.println("-----------------");
Set<String> set = emps.stream().map(Employee::getName).collect(Collectors.toSet());
set.forEach(System.out::println);
System.out.println("-----------------");
HashSet<String> hs = emps.stream().map(Employee::getName).collect(Collectors.toCollection(HashSet::new));
hs.forEach(System.out::println);李四
张三
王五
赵六
赵六
赵六
田七
String str = emps.stream().map(Employee::getName).collect(Collectors.joining(",", "----", "----"));
System.out.println(str);----李四,张三,王五,赵六,赵六,赵六,田七----
Optional<Double> sum = emps.stream().map(Employee::getSalary).collect(Collectors.reducing(Double::sum));
System.out.println(sum.get());48888.84000000001
并行流
并行流就是把一个内容分成多个数据块,并用不同的线程分别处理每个数据块的流。Stream API 可以声明性地通过parallel() 与sequential() 在并行流与顺序流之间进行切换。
Fork/Join 框架
Fork/Join 框架:就是在必要的情况下,将一个大任务,进行拆分(fork)成若干个小任务(拆到不可再拆时),再将一个个的小任务运算的结果进行join 汇总.

Fork/Join 框架与传统线程池的区别
采用“工作窃取”模式(work-stealing):
当执行新的任务时它可以将其拆分分成更小的任务执行,并将小任务加到线程队列中,然后再从一个随机线程的队列中偷一个并把它放在自己的队列中。
相对于一般的线程池实现,fork/join框架的优势体现在对其中包含的任务的处理方式上.在一般的线程池中,如果一个线程正在执行的任务由于某些原因无法继续运行,那么该线程会处于等待状态.而在fork/join框架实现中,如果某个子问题由于等待另外一个子问题的完成而无法继续运行.那么处理该子问题的线程会主动寻找其他尚未运行的子问题来执行.这种方式减少了线程的等待时间,提高了性能.