大家平时都用过hashMap,但是可能大家对hashMap的底层实现不太了解,同时对其中可能出现的hash冲突有些不了解,这几天我翻了下资料,也稍微了解下,记录下来,以免遗忘。
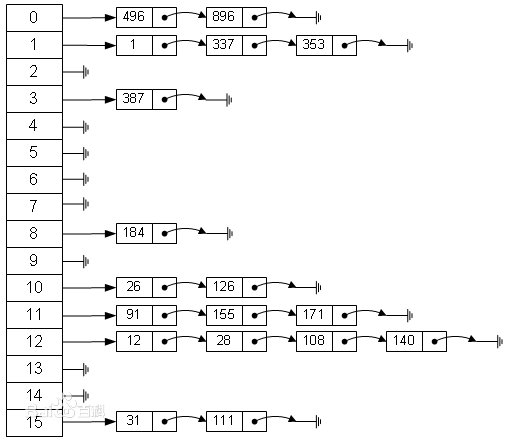
上图就是一个散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。但是当关键字数量比较大的时候,难免就会造成一个问题,就是不一样的关键字隐射到同一个地址上,这样就造成了一个问题,就是hash冲突。那么如何解决呢?
一般比较常用的方法有开放地址法:(内容来自百度百科)
1. 开放寻址法:Hi=(H(key) + di) MOD m,i=1,2,…,k(k<=m-1),其中H(key)为散列函数,m为散列表长,di为增量序列,可有下列三种取法:
1.1. di=1,2,3,…,m-1,称线性探测再散列;顺序查看表的下一单元,直至找到某个空单元,或查遍全表。
1.2. di=1^2,-1^2,2^2,-2^2,⑶^2,…,±(k)^2,(k<=m/2)称二次探测再散列;在表的左右进行跳跃式探测。
1.3. di=伪随机数序列,称伪随机探测再散列。根据产生的随机数进行探测。
2 再散列法:建立多个hash函数,若是当发生hash冲突的时候,使用下一个hash函数,直到找到可以存放元素的位置。
3 拉链法(链地址法):就是在冲突的位置上简历一个链表,然后将冲突的元素插入到链表尾端,
4 建立公共溢出区:将哈希表分为基本表和溢出表,将与基本表发生冲突的元素放入溢出表中。
底层的hashMap是由数组和链表来实现的,就是上面说的拉链法。首先当插入的时候,会根据key的hash值然后计算出相应的数组下标,计算方法是index = hashcode%table.length,(这个下标就是上面提到的bucket),当这个下标上面已经存在元素的时候那么就会形成链表,将后插入的元素放到尾端,若是下标上面没有存在元素的话,那么将直接将元素放到这个位置上。
当进行查询的时候,同样会根据key的hash值先计算相应的下标,然后到相应的位置上进行查找,若是这个下标上面有很多元素的话,那么将在这个链表上一直查找直到找到对应的元素。