1 Kafka的背景介绍
1.1 了解什么是消息系统
消息系统负责将数据从一个应用程序传输到另一个应用程序,因此应用程序可以专注于数据,但不担心如何共享它。
1.2 JMS消息系统
JMS是什么:JMS是Java提供的一套技术规范,用来进行消息系统的传递
JMS干什么用:用来异构系统 集成通信,缓解系统瓶颈,提高系统的伸缩性增强系统用户体验,使得系统模块化和组件化变得可行并更加灵活
通过什么方式:生产消费者模式(生产者、服务器、消费者)
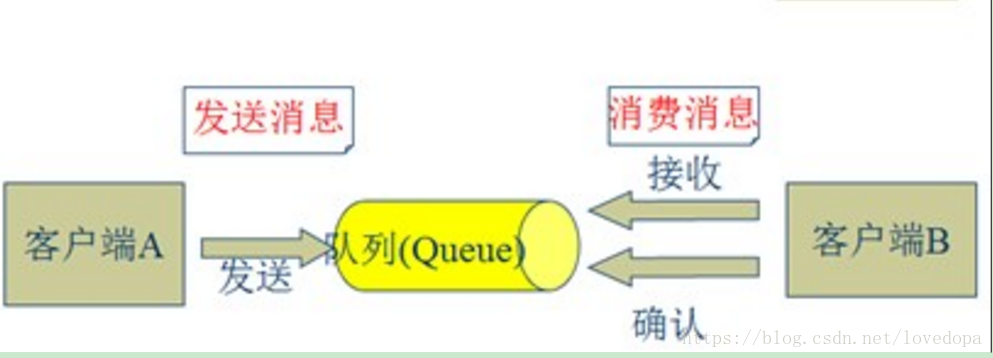
1.3 JMS的消息传输模型
消息在客户端应用程序和消息传递系统之间异步排队。 有两种类型的消息模式可用 - 一种是点对点,另一种是发布 - 订阅(pub-sub)消息系统。 大多数消息模式遵循 pub-sub 。
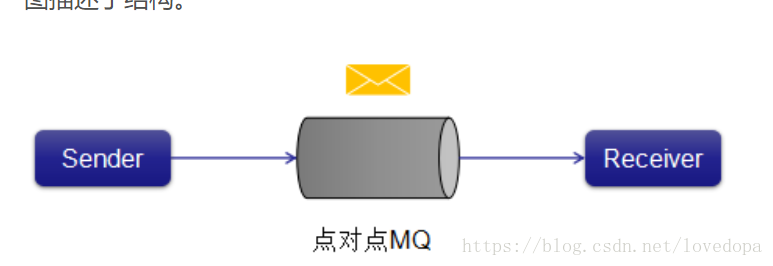
1.3.1 点对点消息系统
在点对点系统中,消息被保留在队列中。 一个或多个消费者可以消耗队列中的消息,但是特定消息只能由最多一个消费者消费。 一旦消费者读取队列中的消息,它就从该队列中消失。 该系统的典型示例是订单处理系统,其中每个订单将由一个订单处理器处理,但多个订单处理器也可以同时工作。
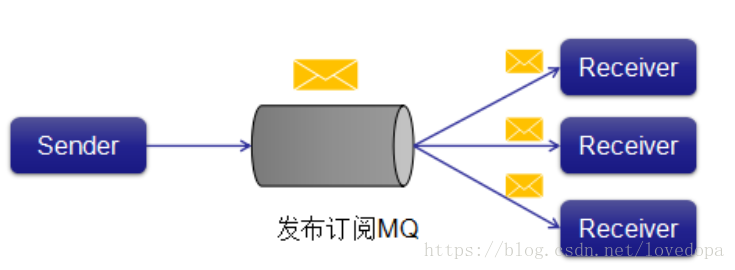
1.3.2发布 - 订阅消息系统
在发布 - 订阅系统中,消息被保留在主题中。 与点对点系统不同,消费者可以订阅一个或多个主题并使用该主题中的所有消息。 在发布 - 订阅系统中,消息生产者称为发布者,消息使用者称为订阅者。 一个现实生活的例子是Dish电视,它发布不同的渠道,如运动,电影,音乐等,任何人都可以订阅自己的频道集,并获得他们订阅的频道时可用。 -
产生数据的方法:
queue.put(object) 数据生产
queue.take(object) 数据消费
1.3.3 常见的JMS消息服务器
JMS消息服务器 ActiveMQ
分布式消息中间件 Metamorphosis
分布式消息中间件 RocketMQ
其他MQ-如
l.NET消息中间件 DotNetMQ
l基于HBase的消息队列 HQueue
lGo 的 MQ 框架 KiteQ
lAMQP消息服务器 RabbitMQ
lMemcacheQ 是一个基于 MemcacheDB 的消息队列服务器。
1.4 为什么需要消息队列-☆☆☆☆☆
消息系统的核心作用就是三点:解耦,异步和并行
以用户注册的案列来说明消息系统的作用
用户注册的一般流程
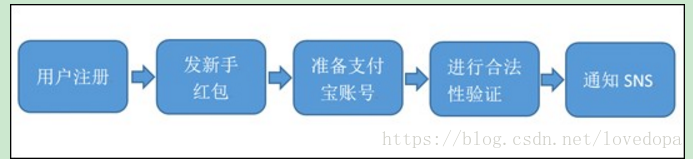
问题:随着后端流程越来越多,每步流程都需要额外的耗费很多时间,从而会导致用户更长的等待延迟。
用户注册的并行执行
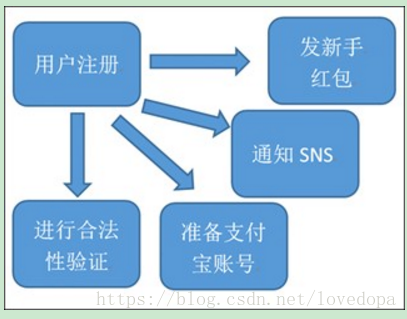
问题:系统并行的发起了4个请求,4个请求中,如果某一个环节执行1分钟,其他环节再快,用户也需要等待1分钟。如果其中一个环节异常之后,整个服务挂掉了。
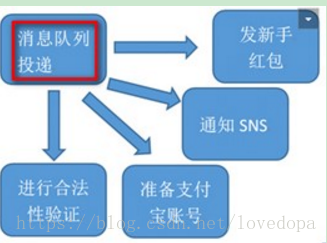
用户注册的最终一致
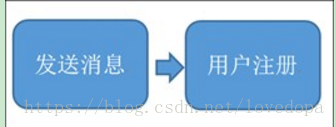
1、 保证主流程的正常执行、执行成功之后,发送MQ消息出去。
2、 需要这个destination的其他系统通过消费数据再执行,最终一致。
1.5 什么是Kafka
Apache Kafka是一个分布式发布 - 订阅消息系统和一个强大的队列,可以处理大量的数据,并使您能够将消息从一个端点传递到另一个端点。 Kafka适合离线和在线消息消费。 Kafka消息保留在磁盘上,并在群集内复制以防止数据丢失。 Kafka构建在ZooKeeper同步服务之上。 它与Apache Storm和Spark非常好地集成,用于实时流式数据分析。
Kafka专为分布式高吞吐量系统而设计。 与其他消息传递系统相比,Kafka具有更好的吞吐量,内置分区,复制和固有的容错能力,这使得它非常适合大规模消息处理应用程序。
Kafka可以在许多用例中使用, 其中一些列出如下:
指标 - Kafka通常用于操作监控数据。 这涉及聚合来自分布式应用程序的统计信息,以产生操作数据的集中馈送。
日志聚合解决方案 - Kafka可用于跨组织从多个服务收集日志,并使它们以标准格式提供给多个服务器。
流处理 - 流行的框架(如Storm和Spark Streaming)从主题中读取数据,对其进行处理,并将处理后的数据写入新主题,供用户和应用程序使用。 Kafka的强耐久性在流处理的上下文中也非常有用。
1.6 Kafka的相关架构
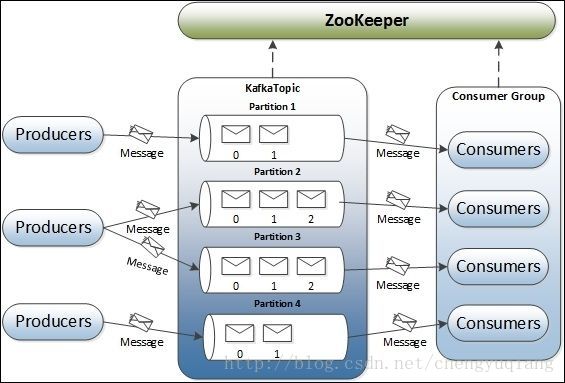
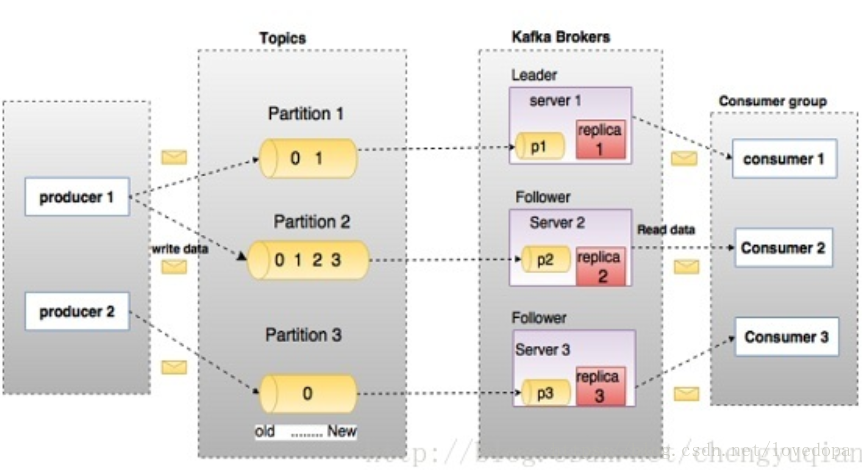
深入学习Kafka之前,必须了解主题(Topic)、经纪人(Broker)、生产者(Producer)或者发布者,以及消费者(Consumer)或者订阅者等主要术语。 下图说明了主要术语,表格详细描述了图表组件。
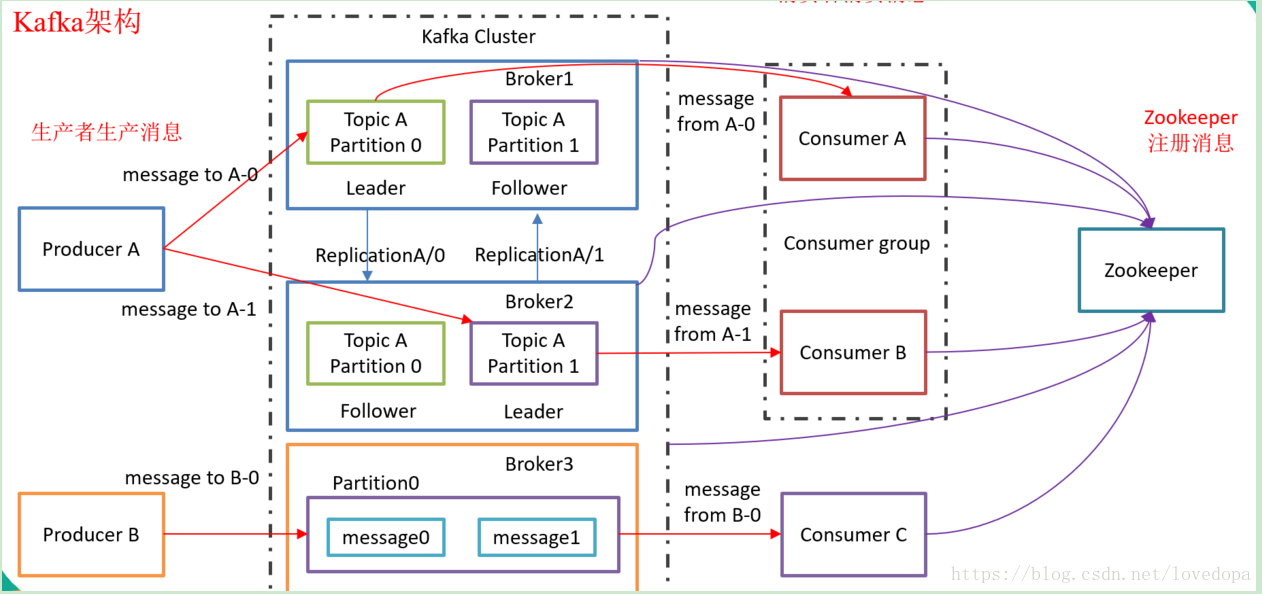
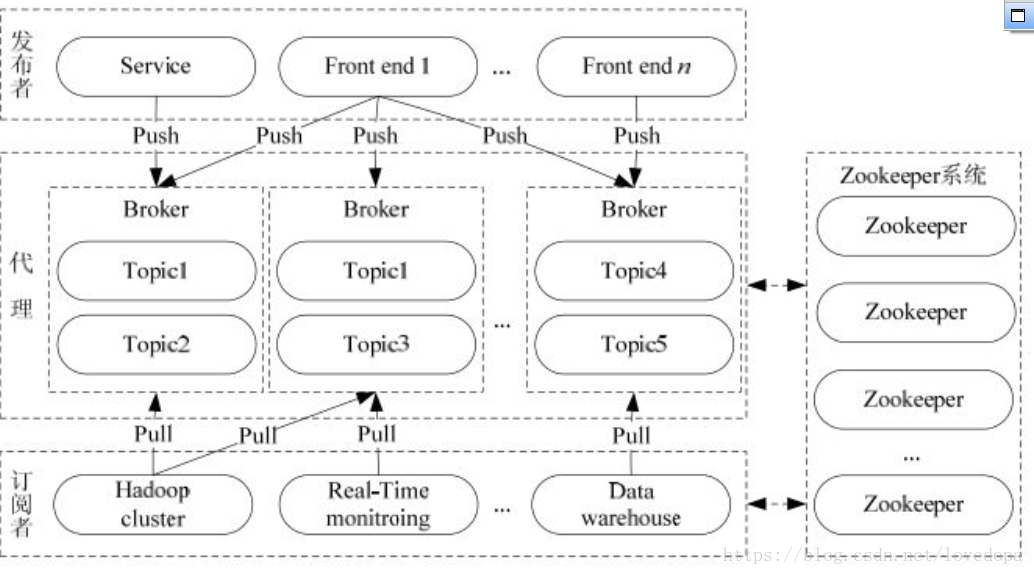
Broker:
Kafka集群包含一个或多个服务器,这种服务器被称为broker -
Topic :
每条发布到Kafka集群的消息都有一个类别,这个类别被称为topic。
(物理上不同topic的消息分开存储,逻辑上一个topic的消息虽然保存于一个或多个broker上但用户只需指定消息的topic即可生产或消费数据而不必关心数据存于何处)
Producer:
负责发布消息到Kafka broker
Consumer:
消费消息。每个consumer属于一个特定的consuer group(可为每个consumer指定group name,若不指定group name则属于默认的group)。使用consumer high level API时,同一topic的一条消息只能被同一个consumer group内的一个consumer消费,但多个consumer group可同时消费这一消息。
Zookeeper:
依赖集群保存meta信息,其实就是消息的同步中心。
Partition :
parition是物理上的概念,每个topic包含一个或多个partition,创建topic时可指定parition数量。每个partition对应于一个文件夹,该文件夹下存储该partition的数据和索引文件
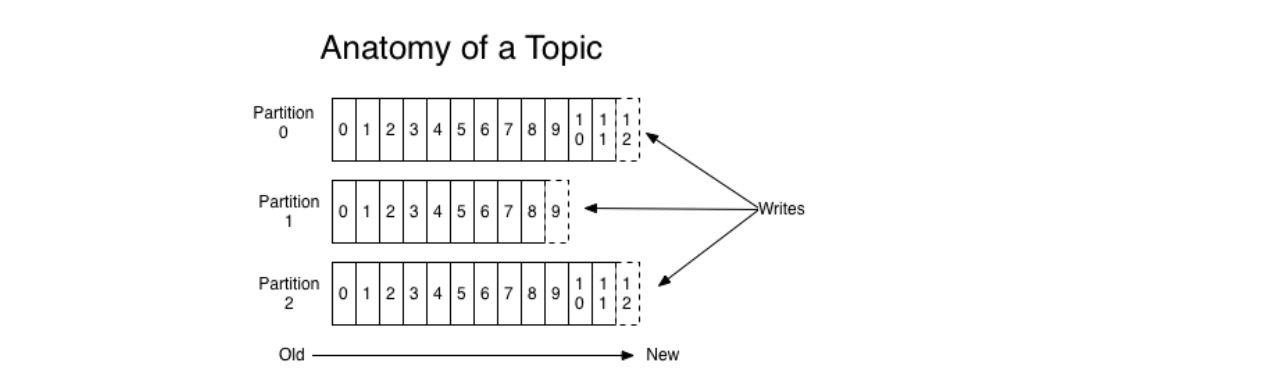
一个Topic可以分成多个Partition,这是为了平行化处理。
每个Partition内部消息有序,其中每个消息都有一个offset序号。
一个Partition只对应一个Broker,一个Broker可以管理多个Partition。