版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/fuqiuai/article/details/79458331
相关文章:
简介
又叫K-均值算法,是非监督学习中的聚类算法。
基本思想
k-means算法比较简单。在k-means算法中,用cluster来表示簇;容易证明k-means算法收敛等同于所有质心不再发生变化。基本的k-means算法流程如下:
选取k个初始质心(作为初始cluster,每个初始cluster只包含一个点);
repeat:
对每个样本点,计算得到距其最近的质心,将其类别标为该质心所对应的cluster;
重新计算k个cluster对应的质心(质心是cluster中样本点的均值);
until 质心不再发生变化 repeat的次数决定了算法的迭代次数。实际上,k-means的本质是最小化目标函数,目标函数为每个点到其簇质心的距离的平方和:
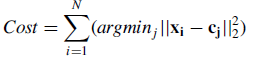
N是元素个数,x表示元素,c(j)表示第j簇的质心
算法复杂度
时间复杂度是O(nkt) ,其中n代表元素个数,t代表算法迭代的次数,k代表簇的数目
优缺点
优点
- 简单、快速;
- 对大数据集有较高的效率并且是可伸缩性的;
- 时间复杂度近于线性,适合挖掘大规模数据集。
缺点
- k-means是局部最优,因而对初始质心的选取敏感;
- 选择能达到目标函数最优的k值是非常困难的。
代码
代码已在github上实现,这里也贴出来
# coding:utf-8
import numpy as np
import matplotlib.pyplot as plt
def loadDataSet(fileName):
'''
加载测试数据集,返回一个列表,列表的元素是一个坐标
'''
dataList = []
with open(fileName) as fr:
for line in fr.readlines():
curLine = line.strip().split('\t')
fltLine = list(map(float,curLine))
dataList.append(fltLine)
return dataList
def randCent(dataSet, k):
'''
随机生成k个初始的质心
'''
n = np.shape(dataSet)[1] # n表示数据集的维度
centroids = np.mat(np.zeros((k,n)))
for j in range(n):
minJ = min(dataSet[:,j])
rangeJ = float(max(dataSet[:,j]) - minJ)
centroids[:,j] = np.mat(minJ + rangeJ * np.random.rand(k,1))
return centroids
def kMeans(dataSet, k):
'''
KMeans算法,返回最终的质心坐标和每个点所在的簇
'''
m = np.shape(dataSet)[0] # m表示数据集的长度(个数)
clusterAssment = np.mat(np.zeros((m,2)))
centroids = randCent(dataSet, k) # 保存k个初始质心的坐标
clusterChanged = True
iterIndex=1 # 迭代次数
while clusterChanged:
clusterChanged = False
for i in range(m):
minDist = np.inf; minIndex = -1
for j in range(k):
distJI = np.linalg.norm(np.array(centroids[j,:])-np.array(dataSet[i,:]))
if distJI < minDist:
minDist = distJI; minIndex = j
if clusterAssment[i,0] != minIndex: clusterChanged = True
clusterAssment[i,:] = minIndex,minDist**2
print("第%d次迭代后%d个质心的坐标:\n%s"%(iterIndex,k,centroids)) # 第一次迭代的质心坐标就是初始的质心坐标
iterIndex+=1
for cent in range(k):
ptsInClust = dataSet[np.nonzero(clusterAssment[:,0].A==cent)[0]]#get all the point in this cluster
centroids[cent,:] = np.mean(ptsInClust, axis=0)
return centroids, clusterAssment
def showCluster(dataSet, k, centroids, clusterAssment):
'''
数据可视化,只能画二维的图(若是三维的坐标图则直接返回1)
'''
numSamples, dim = dataSet.shape
if dim != 2:
return 1
mark = ['or', 'ob', 'og', 'ok','oy','om','oc', '^r', '+r', 'sr', 'dr', '<r', 'pr']
# draw all samples
for i in range(numSamples):
markIndex = int(clusterAssment[i, 0])
plt.plot(dataSet[i, 0], dataSet[i, 1], mark[markIndex])
mark = ['Pr', 'Pb', 'Pg', 'Pk','Py','Pm','Pc','^b', '+b', 'sb', 'db', '<b', 'pb']
# draw the centroids
for i in range(k):
plt.plot(centroids[i, 0], centroids[i, 1], mark[i], markersize = 12)
plt.show()
if __name__ == '__main__':
dataMat = np.mat(loadDataSet('./testSet')) #mat是numpy中的函数,将列表转化成矩阵
k = 4 # 选定k值,也就是簇的个数(可以指定为其他数)
cent, clust = kMeans(dataMat, k)
showCluster(dataMat, k, cent, clust)测试数据集获取地址为testSet