秋招快要过去…我还没拿到心意公司的offer……sad!今天还被虐了, 不过面试失败没关系,重点学到了知识。
现在就把不会的面试题总结一下。^ ^
一、有两台服务器,一台在美国,一台在中国。中国是原数据,美国的是数据备份。现在美国的数据文件中,有一处损坏了。问:如何快速定位这个错误位置。
前提:1)宽带的代价很大。 2)数据文件很大。
【我的内心:Excuse me???一来就抛一个这么难的题给我吗?真的没拿错面试题吗?T T】
我的回答思路从数据分片,分块传输,携带数据标记(记录数据字节开始和结束的标记,好跟原数据对比检查);此外还提及到采用一些搜索算法,如二分搜索法来提高效率。
【面试官:一脸嫌弃。】
【面试官:有听过摘要算法吗?】
参考答案:采用摘要算法,如MD5。对数据文件分片(如果想定位准确,分片粒度小一点)进行摘要得到一串字符串,再把字符串传输进行校验。这样既能减少宽带,又能快速有效的定位错误。
科普:常见的摘要算法,主要有 CRC32、MD5、SHA1、SHA256、SHA384、SHA512。用途有数据校验、非对称加密等。
二、手写程序:简单的二分法
/**非递归**/
/**
* 假设数据有序,才能二分搜索。
* @param a
* @param key
* @return
*/
public static int search (int a[], int key){
int start = 0;
int end = a.length-1;
while(start <= end){
int mid = (start+end)/2;
//如果key比中间值小,则end变成mid-1
if(key < a[mid]){
end = mid - 1;
//如果key比中间值大,则start变成mid+1
}else if(key > a[mid]){
start = mid + 1;
}else{
return mid;
}
}
return -1;
}/**递归**/
/**
* 假设数据有序,才能二分搜索。
* @param a
* @param key
* @return
*/
public static int search (int a[], int key){
int mid = (left+right)/2;
//假设有以下情况返回-1
if(key > a[right] || key < a[left] || a[left] > a[right]){
return -1;
}else if(key < a[mid]){
return search2(a, left, mid-1, key);
}else if(key > a[mid]){
return search2(a, mid + 1, right, key);
}else{
return mid;
}
}三、Nginx 是什么?一般用来做什么?
参考资料:Nginx是什么?Nginx介绍及Nginx的优点
对于我做的项目用途:反向代理和负载均衡。
对于正向代理和反向代理,知乎上有一个图很好的解释了,如下:
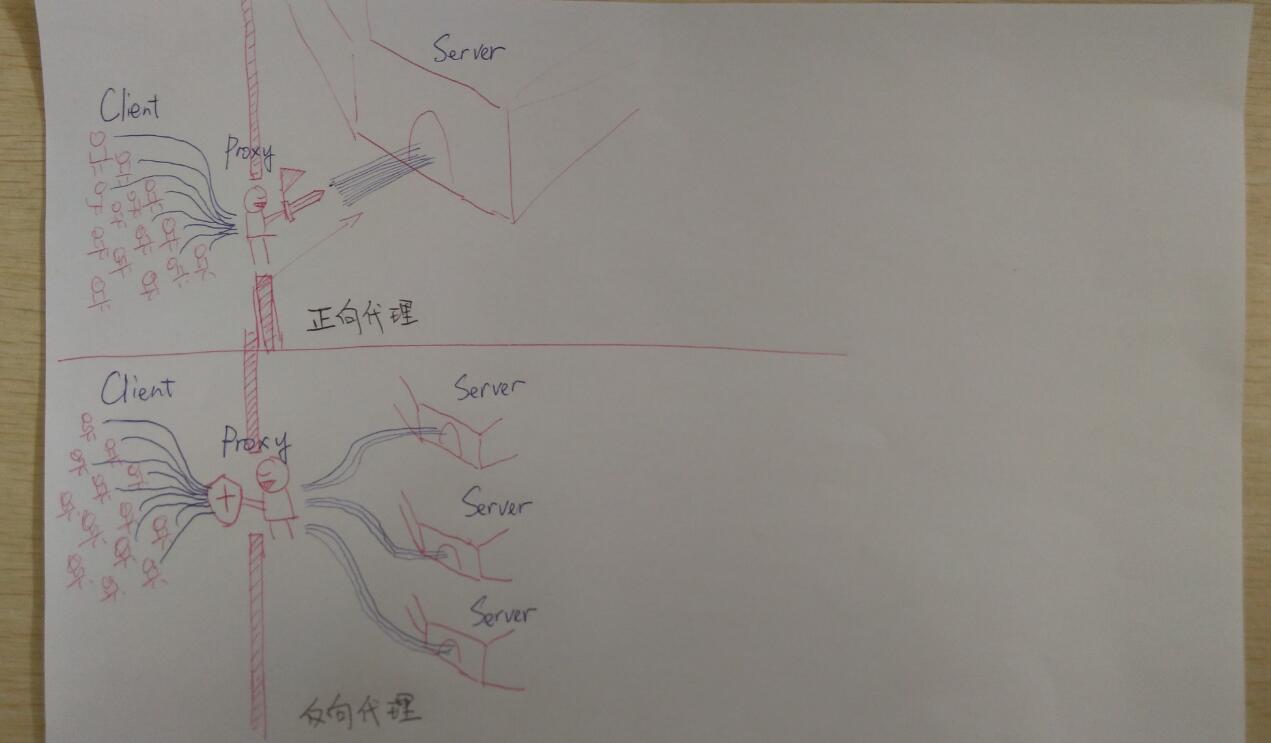
四、在mysql如何定位查找慢的sql语句,并优化。
参考答案:
在mysql有一个日志叫慢查询日志,意思就是把查询慢的sql以日志的形式记录下来。
这里要设置几个参数:
long_query_time :参数设置时间,执行时间大于该参数设置时间的sql都会被记录下来,支持小于1秒的设置,不过一般设置为1秒,主要原因时小于1秒的sql太多了,而且执行计划在大数据量情况下小于1秒的一般是没全表扫描的,而小数据量小于1秒的,即便全表扫描也问题不大,除非是执行频率非常高。
slow_query_log :参数设置是否打开慢查询日志的开关。
slow_query_log_file : 参数设置慢查询日志文件。
具体的参数设置参考mysql的SQL性能监控 。
五、有关JVM原理和优化。
答:对JVM内存的系统级的调优主要的目的是减少GC的频率和Full GC的次数,过多的GC和Full GC是会占用很多的系统资源(主要是CPU),影响系统的吞吐量。特别要关注Full GC,因为它会对整个堆进行整理,导致Full GC一般由于以下几种情况:
旧生代空间不足
调优时尽量让对象在新生代GC时被回收、让对象在新生代多存活一段时间和不要创建过大的对象及数组避免直接在旧生代创建对象Pemanet Generation空间不足
增大Perm Gen空间,避免太多静态对象统计得到的GC后晋升到旧生代的平均大小大于旧生代剩余空间
控制好新生代和旧生代的比例System.gc()被显示调用
垃圾回收不要手动触发,尽量依靠JVM自身的机制
调优手段主要是通过控制堆内存的各个部分的比例和GC策略来实现,下面来看看各部分比例不良设置会导致什么后果
1)新生代设置过小
一是新生代GC次数非常频繁,增大系统消耗;二是导致大对象直接进入旧生代,占据了旧生代剩余空间,诱发Full GC
2)新生代设置过大
一是新生代设置过大会导致旧生代过小(堆总量一定),从而诱发Full GC;二是新生代GC耗时大幅度增加
一般说来新生代占整个堆1/3比较合适
3)Survivor设置过小
导致对象从eden直接到达旧生代,降低了在新生代的存活时间
4)Survivor设置过大
导致eden过小,增加了GC频率
另外,通过-XX:MaxTenuringThreshold=n来控制新生代存活时间,尽量让对象在新生代被回收
由内存管理和垃圾回收可知新生代和旧生代都有多种GC策略和组合搭配,选择这些策略对于我们这些开发人员是个难题,JVM提供两种较为简单的GC策略的设置方式
1)吞吐量优先
JVM以吞吐量为指标,自行选择相应的GC策略及控制新生代与旧生代的大小比例,来达到吞吐量指标。这个值可由-XX:GCTimeRatio=n来设置
2)暂停时间优先
JVM以暂停时间为指标,自行选择相应的GC策略及控制新生代与旧生代的大小比例,尽量保证每次GC造成的应用停止时间都在指定的数值范围内完成。这个值可由-XX:MaxGCPauseRatio=n来设置
最后!!!祝我顺利找到心仪的工作!!!!