写在前面的话
其实也没有什么可以写的,或者说完全没有价值。因为你只要动一动手指就可以在Google上找到我要写的这些东西。只是我还不习惯好久没有碰我的blog,但是我又不想写没有价值的东西。或许有价值,只是在我一年两不编程的情况下,我会忘记那些我以前很熟悉的操作是怎么完成的,或许混到那个地步我的人生就开始悲剧了吧。总之,成长成我想要的样子我还是需要很长的路要走。
这一篇是会持续更新的,至少为了保证它看起来不那么水,也要让它持续更新
python中的进制转换
1.其他进制转换为10进制
所有的进制转换为10进制都可以归结为下面这条语句:
int(‘需要转换的数字’,原先的进制)
e.g.
#2进制转换为10进制
>>> int('1001',2)
9
>>> int('1010',2)
10
#8进制转换为10进制
>>> int("12",8)
10
#16进制转换为10进制
>>> int("fa",16)
250
>>> int("0xab",16)
171
2. 10进制转换为其他的进制
#10进制转换为2进制
>>> bin(10)
'0b1010'
#10进制转换为8进制
>>> oct(8)
'010'
#10进制转换为16进制
>>> hex(255)
'0xff'
3. 其他进制之间的转换
#2进制到16进制之间的转换
>>> hex(0b1001)
'0x9'
reference:
Python中的目录操作
1.获取当目录
使用os.getcwd()
>>> import os
>>> path=os.getcwd()
>>> path
'D:\\Python27'2.修改当前的路径
使用os.chdir('需要跳转的路径')
import os
os.chdir('F:/')
os.getcwd()
'F:\\'3.创建子目录
os.makedirs("path")
比如说在你的F:盘下面有一个python的文件夹,你在里面穿件一个test的文件夹可以如下编写:
>>> os.makedirs("test")
>>> os.chdir("test")
>>> os.getcwd()
'F:\\python\\test'
>>> os.listdir(".")
[]首先用makedirs()命令来创建一个test目录这个时候用chdir("path")跳转进去可以用getcwd()来查看我们已经执行成功了
4.获取目录中的文件以及子目录的列表
os.listdir("F:/")
['$RECYCLE.BIN', '360Downloads', '7\xd4\xc2\xbf\xce\xb3\xcc', 'Android', 'Androidtool', 'baidu download', 'baidu player', 'Cygwin64', 'Downloads', 'eclipse', 'eclipse-java-juno-SR2-win32-x86_64.zip', 'FFOutput', 'GouWoGames', 'kankan', 'KuGouCache', 'KwDownload', 'LatexWS', 'Media', 'ProgramData', 'python', 'QQMusicCache', 'readelf', 'root', 'System Volume Information', 'VSPath', 'WekaData', 'WOJ', 'workspace', 'YY', '\xbc\xd3\xb9\xcc\xd3\xa6\xd3\xc32', '\xd5\xd5\xc6\xac', '\xc8\xed\xbc\xfe\xb0\xb2\xd7\xb0\xb0\xfc', '\xd1\xb8\xc0\xd7\xcf\xc2\xd4\xd8', '\xcf\xe3\xb8\xdb\xc9\xea\xc7\xeb']如果你的python文件是放在你所需要的目录里或者说是当前文件夹下,我们要获取器列表可以这么做:
>>> os.getcwd()
'F:\\python'
>>> os.listdir(".")
['.metadata', '.project', '.pydevproject', '123', '123.py', 'addfields.py', 'addfileds.py', 'addtest.py', 'databasekeywordsabstract', 'digits', 'digits.zip', 'ex1.py', 'ex2.py', 'ex3.py', 'ex4.py', 'ex5.py', 'ex6.py', 'ex7.py', 'ex7.pyc', 'ex8.py', 'ex9.py', 'ez_setup.py', 'getPath', 'getPath.py', 'keywords.py', 'KNN.py', 'KNN.pyc', 'kNNtest.py', 'new 1.py', 'new.py', 'privacyKeys.py', 'privacyKeys1.py', 'privacyPolicyKeywords1.py', 'PrivacyPolicyTest.py', 'text.txt']代码获取了路径为python下的所有文件文件及其子目录的列表
5.创建一个新文件
#创建前
>>> os.getcwd()
'F:\\python\\test'
>>> os.listdir(".")
[]
#创建后
>>> file1=open("test1.txt",'w+')
>>> os.listdir(".")
['test1.txt']>>> file1.write("abcdd")
>>> file1.write("hello,world")
>>> file1.close()打开文件你就可以看见相应的内容
判断路径是否存在:
os.path.exists("YOU_PATH")6.分解路径为目录名和文件名
>>> a,b=os.path.split("F:\\python\\test\\test1.txt")
>>> a
'F:\\python\\test'
>>> b
'test1.txt'
>>> 如果你写惯了C语言,你会不会觉得有点奇怪,就是左边的那个赋值,它有两个值,一个付给了a,一个给了b,这个就是python自由的地方,其实这里是个list,其实你也可以这么做
>>> portion=os.path.split("F:\\python\\test\\test1.txt")
>>> portion[0]
'F:\\python\\test'
>>> portion[1]
'test1.txt'不知道你看明白了没有
7.分解文件名和扩展名
>>> portion=os.path.splitext("F:\\python\\test\\test1.txt")
>>> portion[0]
'F:\\python\\test\\test1'
>>> portion[1]
'.txt'这个东西有什么,看起来有点奇怪,或许你未来的某一天会用到,修改文件的后缀名。
import os
files = os.listdir(".")
for filename in files:
portion = os.path.splitext(filename)
if portion[1]==".apk":
newname = portion[0] + ".zip"
os.rename(filename,newname)[email protected]
8. 文件读取的一些技巧
当我们读取文件的时候可能一个文件中存储了一些信息如下图所示:
我们可以使用readlines 读出文件中的所有行。

但是你可能会发现一个问题,打印出来的话是这个样子的:

怎么处理? 这里有一个小的技巧:
for line in f.readlines()
line=line.replace("\n","")这样就可以消除了。
9.获取文件的目录名
使用
os.path.dirname(path)
这个获取得到的是最后一个斜杠前面的值
>>> path
'/home/chicho/softs'
>>> c=os.path.dirname(path)
>>> c
'/home/chicho'
>>> path='/home/chicho/softs/'
>>> c=os.path.dirname(path)
>>> c
'/home/chicho/softs'
>>>
10.获取目录最后的文件名
os.path.basename(path)
返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素。
>>> os.path.basename('c:\\test.csv')
'test.csv'
>>> os.path.basename('c:\\csv')
'csv' (这里csv被当作文件名处理了)
>>> os.path.basename('c:\\csv\\')
''
11.目录的遍历
os.path.walk
函数声明:os.path.walk(top,func,arg)
(1)参数top表示需要遍历的目录路径
(2)参数func表示回调函数,即对遍历路径进行处理的函数。所谓回调函数,是作为某个函数的参数使用,当某个时间触发时,程序将调用定义好的回调函数处理某个任务。注意:walk的回调函数必须提供三个参数:第1个参数为os.path.walk的参数arg,第2个参数表示目录dirname,第3个参数表示文件列表names。注意:os.path.walk的回调函数中的文件列表不和os.walk()那样将子目录和文件分开,而是混为了一摊,需要在回调函数中判断是文件还是子目录。
(3)参数arg是传递给回调函数的元组,为回调函数提供处理参数,arg可以为空。回调函数的第1个参数就是用来接收这个传入的元组的。
过程:以top 为根的目录树中的每一个目录 (包含 top 自身,如果它是一个目录),以参数 (arg, dirname, names)调用回调函数 funct。参数 dirname 指定访问的目录,参数 names 列出在目录中的文件(从 os.listdir(dirname)中得到)。回调函数可以修改 names 改变 dirname 下面访问的目录的设置,例如,避免访问树的某一部分。(由 names 关连的对象必须在合适的位置被修改,使用 del 或 slice 指派。) 注意:符号连接到目录不被作为一个子目录处理,并且因此 walk()将不访问它们。访问连接的目录你必须以os.path.islink(file) 和 os.path.isdir(file)标识它们,并且必须调用walk() 。
#! /usr/bin/env python
#coding=utf-8
import os
#回调函数
def func(arg,dirname,files):
for file in files:
file_path=os.path.join(dirname,file)
if os.path.isfile(file_path):
print "find file:%s" %file_path
#调用
os.path.walk("path",func,())
实际上os.path.walk()遍历就是像人遍历一个文件夹(目录)那样一层层点开的过程。
os.walk()
函数声明:os.walk(top,topdown=True,onerror=None)
(1)参数top表示需要遍历的顶级目录的路径。
(2)参数topdown的默认值是“True”表示首先返回顶级目录下的文件,然后再遍历子目录中的文件。当topdown的值为"False"时,表示先遍历子目录中的文件,然后再返回顶级目录下的文件。
(3)参数onerror默认值为"None",表示忽略文件遍历时的错误。如果不为空,则提供一个自定义函数提示错误信息后继续遍历或抛出异常中止遍历。
返回值:函数返回一个元组,含有三个元素。这三个元素分别是:每次遍历的路径名、路径下子目录列表、目录下文件列表。
---------------------
update@2016-10-7
os.path.walk 和 os.walk的区别
- os.path.walk 在使用回调函数的时候的第三个参数 names 时其实使用的是os.listdir() 这个函数,返回的是这个文件夹下的东西(你能看见的点开这个目录的东西)包括文件和目录
- os.walk 做了os.isdir() 和os.isfile() 的判断 ,返回的参数列表也不同,os.walk() 返回的参数列表是: 每次遍历的路径名、路径下子目录列表、目录下文件列表
@update@2017-5-17
现在为了直观的感受一下我们的os.walk怎么工作,我们来写一点代码看一看。
现在我觉得需要着重理解的就是os.walk() 返回的参数列表是: 每次遍历的路径名、路径下子目录列表、目录下文件列表 这句话。
因为它是一个递归的过程,在处理的时候脑袋里面一定要有这个概念,我们才能愉快的玩耍。
我们先看一下我们的一个目录。
以及目录下的情况

我们来遍历一下这个文件看一看,用我们的os.walk()这个函数。
#!/usr/bin/env python
# coding=utf-8
# Author : Chicho
# Function : see the os.walk() how to work
import os
Path = "/home/chicho/test/test/"
for root,dirs,files in os.walk(Path):
for dir in dirs:
print os.path.join(root,dir)
for file in files:
print os.path.join(root,file)
print "****************"
for a in os.walk(Path):
print(a[0])
print(a[1])
print(a[2])
print "*********"好的,现在我们来看一下这个实验的结果:


reference:
http://my.oschina.net/duhaizhang/blog/68202
http://blog.csdn.net/emaste_r/article/details/12442675http://wangwei007.blog.51cto.com/68019/1104940
python中大小写的转换
字符串中字符大小写的变换:
- * S.lower()
小写
- * S.upper()
大写
- * S.swapcase()
大小写互换
- * S.capitalize()
首字母大写
- * String.capwords(S)
这是模块中的方法。它把S用split()函数分开,然后用capitalize()把首字母变成大写,最后用join()合并到一起
- * S.title()
reference
http://developer.51cto.com/art/201003/189153.htm
一写就是2个半小时,或许我真的该写点有价值的东西,时间该用来做更有价值的事情吧~我又不会睡觉了
update @ 2016-10-7 3.48 p.m.
Pyhton中的与或非
pyhton 中有三种逻辑操作 与,或,非, 分别对应着符号 and, or,not
看下面的代码:
#coding:utf-8
test1 = 12
test2 = 0
print (test1 > test2) and (test1 > 14) #result = False
print (test1 < test2) or (test1 > -1) #result = True
print (not test1) #result = False
print (not test2) #result = TruePython 中的文件操作总结
1.判断文件和目录的存在
import os
os.path.isfile('test.txt') #如果不存在就返回False
os.path.exists(directory) #如果目录不存在就返回Falseupdate @ 2016-10-25
Python 中的join 和split 运用
python join 和 split方法的使用,join用来连接字符串,split恰好相反,拆分字符串的。
1.join用法示例
>>>li = ['my','name','is','bob']
>>>' '.join(li)
'my name is bob'
>>>'_'.join(li)
'my_name_is_bob'
>>> s = ['my','name','is','bob']
>>> ' '.join(s)
'my name is bob'
>>> '..'.join(s)
'my..name..is..bob'
2.split用法示例
>>> b = 'my..name..is..bob'
>>> b.split()
['my..name..is..bob']
>>> b.split("..")
['my', 'name', 'is', 'bob']
>>> b.split("..",0)
['my..name..is..bob']
>>> b.split("..",1)
['my', 'name..is..bob']
>>> b.split("..",2)
['my', 'name', 'is..bob']
>>> b.split("..",-1)
['my', 'name', 'is', 'bob']
可以看出 b.split("..",-1)等价于b.split("..") 
update@2016-10-12
Python中常用到的一些小技巧
1.Python中根据List中的元素获取该元素的下标
In [2]: mylist=["Selina","Hebe","Ella"]
In [3]: index=mylist.index("Hebe")
In [4]: index
Out[4]: 1
In [5]: in1=mylist.index("Selina")
In [6]: in1
Out[6]: 0
In [7]: in1=mylist.index("Ella")
In [8]: in1
Out[8]: 2
In [9]:
另外一种执行循环的遍历方式是通过索引,如下实例:
fruits = ['banana', 'apple', 'mango']
for index in range(len(fruits)):
print '当前水果 :', fruits[index]
print "Good bye!"Reference
http://www.runoob.com/python/python-for-loop.html
2.python中List的一些操作
1. append() 追加单个元素到List的尾部,只接受一个参数,参数可以是任何数据类型,被追加的元素在List中保持着原结构类型。
此元素如果是一个list,那么这个list将作为一个整体进行追加,注意append()和extend()的区别。

2. extend() 将一个列表中每个元素分别添加到另一个列表中,只接受一个参数;extend()相当于是将list B 连接到list A上

3. insert() 将一个元素插入到列表中,但其参数有两个(如insert(1,”g”)),第一个参数是索引点,即插入的位置,第二个参数是插入的元素。
>>> list1
['a', 'b', 'c', 'd']
>>> list1.insert(1,'x')
>>> list1
['a', 'x', 'b', 'c', 'd']4. + 加号,将两个list相加,会返回到一个新的list对象,注意与前三种的区别。前面三种方法(append, extend, insert)可对列表增加元素的操作,他们没有返回值,是直接修改了原数据对象。 注意:将两个list相加,需要创建新的list对象,从而需要消耗额外的内存,特别是当list较大时,尽量不要使用“+”来添加list,而应该尽可能使用List的append()方法。
>>> list1
['a', 'x', 'b', 'c', 'd']
>>> list2=['y','z']
>>> list3=list1+list2
>>> list3
['a', 'x', 'b', 'c', 'd', 'y', 'z']3. 删除List中的元素
li = [1,2,3,4,5,6]
# 1.使用del删除对应下标的元素
del li[2]
# li = [1,2,4,5,6]
# 2.使用.pop()删除最后一个元素
li.pop()
# li = [1,2,4,5]
# 3.删除指定值的元素
li.remove(4)
# li = [1,2,5]
# 4.使用切片来删除
li = li[:-1]
# li = [1,2]
# !!!切忌使用这个方法,如果li被作为参数传入函数,
# 那么在函数内使用这种删除方法,将不会改变原list
li = [1,2,3,4,5,6]
def delete(li, index):
li = li[:index] + li[index+1:]
delete(li, 3)
print li
# 会输出[1,2,3,4,5,6]Reference
https://www.douban.com/note/277146395/
4.Python中比较两个list 相等与否
如果要比较两个list 是不是相等我们用 == 或者是!= (注意,不是表情符号啊)

从上面我们可以看出,由于list 是和set 集合不同的。List是需要考虑元素的排序问题,就算元素相同位置不同那么这两个list 也是不同的。
a 和b 是有相同的元素,但是排序不同所以他们两个是不同的链表。
如果要判断这两个list是不是同一个 对象我们采用的是is

我们的b 和c和前面的例子是一样的。
5. Python 中打乱List中元素的方法
方法:
import random
random.shuffle(你的列表)
举个例子:
L1 = [1, 3, 5, 7]
random.shuffle(L1)
print Le
>>> [1, 7, 5, 3]
这样就打乱了列表内元素排序我们使用random.shuffle(List)这个函数
注意: 使用这个函数的时候我们是亲自对List这个列表中的元素进行打乱,但是不会返回一个新的List,如过需要以前的数据,我们需要备份一下。

Python中退出程序的操作
import sys
sys.exit()update @ 2016-10-27
Python中对字符串的操作总结
1. 是否包含特定的子串操作
假设我们要判断某个子串是不是在某个字符串中我们用的就是 in 这个操作
my_string = "abcdef"
if "abc" in my_string:
has_abc = True
if has_abc == True:
print "String contains string."我们看一下下面这个例子

Reference
http://www.sharejs.com/codes/python/2367
2. 是否包含特定的字符串的方法二
在这里我们使用find方法来判断这个字符串是不是有相应的字符子串。
如果没有含有这个字符子串,则我们的find会返回-1, 如果发现了这个字符串中含有这个子串,那么我们使用find之后将会返回这个子串在我们原先的字符串中出现的次数。如下图所示:

In [1]: s="Hebe is a member of popular singer group named SHE"
In [4]: if s.find("he")==-1:
...: print "No"
...: else:
...: print "Yes"
...:
No
用法如上代码所示
注意在Python中是区分大小写的。
Python中字典的操作
字典是另一种可变容器模型,且可存储任意类型对象。
字典的每个键值(key=>value)对用冒号(:)分割,每个对之间用逗号(,)分割,整个字典包括在花括号({})中 ,格式如下所示:
d = {key1 : value1, key2 : value2 }update@2016-10-13
1.修改字典
向字典中增加元素
在字典里增加元素就是增加新的键值对,键值是不能重复的,值是可以重复的
#!/usr/bin/python dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}; dict['Age'] = 8; # update existing entry dict['School'] = "DPS School"; # Add new entry
我们在这个字典中增加了新的元素,年龄和学校
我们查看一下我们更新后的字典:

可以发现,这两个值已经在我们的字典中了
注意: 字典的插入是无序的,但是链表的插入是有序的
删除字典中的元素:
#!/usr/bin/python # -*- coding: UTF-8 -*- dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}; del dict['Name']; # 删除键是'Name'的条目 dict.clear(); # 清空词典所有条目 del dict ; # 删除词典
2.循环遍历字典中的元素
2.1根据字典中的键来遍历我们的字典
In [1]: d = {'x':1, 'y':2, 'z':3}
In [2]: for key in d:
...: print key, d[key]2.2 根据键值对来遍历
person={'name':'lizhong','age':'26','city':'BeiJing','blog':'www.qttc.net'}
for x in person.items():
print x所得到的结果如下所示:

Python运行 Shell 脚本
如果我们有个脚本比如说叫 script.sh
我们要写一个Python来运行这个脚本,这个时候我们先给这个shell脚本赋运行的权利 chmod a+x script.sh
如果我们的脚本和我们的python 代码在同一个路径下面那么我们可以使用下面这样的代码来运行我们的shell 脚本
cmd="./script.sh {0} {1}".format(arg1,arg2)
os.system(cmd)在我们的shell 脚本后面跟着的是这个脚本需要传入的参数{0} {1},真正的值是在format 这个里面的东西。你的脚本不需要任何参数那么
cmd="./script.sh“ ; os.system(cmd)这样就可以用我们的Python来调用我们的shell脚本
Python的格式化输出
1.格式符
格式符为真实值预留位置,并控制显示的格式。格式符可以包含有一个类型码,用以控制显示的类型,如下:
%s 字符串 (采用str()的显示)
%r 字符串 (采用repr()的显示)
%c 单个字符
%b 二进制整数
%d 十进制整数
%i 十进制整数
%o 八进制整数
%x 十六进制整数
%e 指数 (基底写为e)
%E 指数 (基底写为E)
%f 浮点数
%F 浮点数,与上相同
%g 指数(e)或浮点数 (根据显示长度)
%G 指数(E)或浮点数 (根据显示长度)
%% 字符"%"
来个例子

这个和C语言中的运用差不多的。
Reference
http://www.cnblogs.com/vamei/tag/Python/
Pyhton中的多维数组
1.创建一个二维数组
现在我们要创建一个二维数组我们使用到的基本语法如下所示:

我们打印出来看看效果如何:
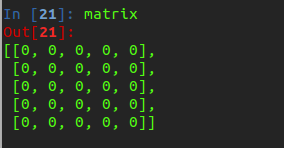
这样我们就得到一个5*5的矩阵
在上面的语法是我们创建了一个长度为5的list,这个时候我们循环构造了5个一样的列表
我们可以为上面的每一个值单独赋值
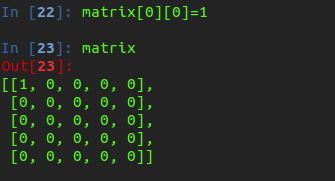
但是我们要创建一个二维数组的时候,不能用下面这个方法构建
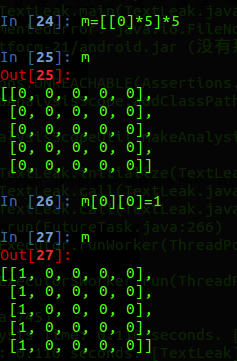
这样我们构建的数组是深度复制得到的,所有List中任何一个改变都会直接影响到其他的
Python的正则表达式
1.search 和match的区别
2. findall
re.findall(pattern,string,flags=0)
找到RE匹配的所有子串,并把它们作为一个列表有序的返回,如果没有匹配,那么返回的是空列表。如果是匹配的那么从左到右有序的返回。
注意在re.match()中如果有匹配的,那么只要找到一个就会返回。它返回的是一个对象,如果没有找到匹配的那么就会返回的是空。
>>> re.findall("a","bcdef")
[]
>>> re.findall(r"\d+","12a32bc43jf3")
['12', '32', '43', '3']


Python中去除字符串的空格
Python中去除一个字符串中的空格我们可以用replace
In [17]: strStr=" shdja sdaj sdja j k k o "
In [18]: strStr.replace(" ","")
Out[18]: 'shdjasdajsdjajkko'
