在计算loss的时候,最常见的一句话就是tf.nn.softmax_cross_entropy_with_logits,那么它到底是怎么做的呢?
首先明确一点,loss是代价值,也就是我们要最小化的值
tf.nn.softmax_cross_entropy_with_logits(logits, labels, name=None)
除去name参数用以指定该操作的name,与方法有关的一共两个参数:
第一个参数logits:就是神经网络最后一层的输出,如果有batch的话,它的大小就是[batchsize,num_classes],单样本的话,大小就是num_classes
第二个参数labels:实际的标签,大小同上
具体的执行流程大概分为两步:
第一步是先对网络最后一层的输出做一个softmax,这一步通常是求取输出属于某一类的概率,对于单样本而言,输出就是一个num_classes
softmax的公式是:
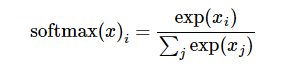
扫描二维码关注公众号,回复:
3353826 查看本文章

至于为什么是用的这个公式?这里不介绍了,涉及到比较多的理论证明
第二步是softmax的输出向量[Y1,Y2,Y3...]和样本的实际标签做一个交叉熵,公式如下:
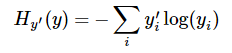
其中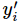
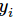
softmax的输出向量[Y1,Y2,Y3...]
显而易见,预测
注意!!!这个函数的返回值并不是一个数,而是一个向量,如果要求交叉熵,我们要再做一步tf.reduce_sum操作,就是对向量里面所有元素求和,最后才得到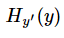
tf.reduce_mean操作,对向量求均值!
理论讲完了,上代码
