第二章练习
只做了几道题,先转去句法和语义的学习了,挖的坑不知道什么时候能填上。。。。
使用语料库模块使用语料库模块处理austen-persuasion.txt。这本书中有多少词标识符?多少词类型?
import nltk
emma = nltk.corpus.gutenberg.words('austen-emma.txt')
len(emma) #求取文本中的词标识符
len(set(emma)) #求取文本中的词类型使用布朗语料库阅读器nltk.corpus.brown.words()或网络文本语料库阅读器nltk.corpus.webtext.words()来访问两个不同文体的一些样例文本。
#我这里只尝试了nltk.corpus.brown下免得一个样例文本
import nltk
nltk.corpus.brown.categories() ##查看有多少种类
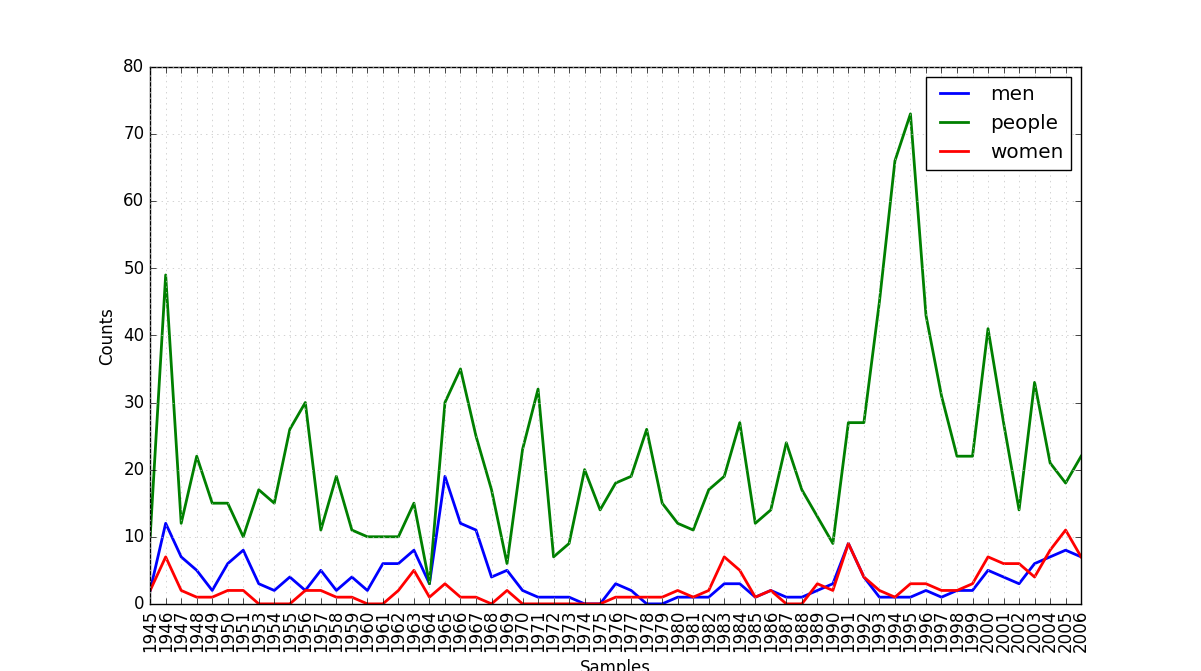
nltk.corpus.brown.words(categories='belles_lettres') ##选取种类为'belles_lettres',注意必须写上'categories='使用state_union 语料库阅读器,访问《国情咨文报告》的文本。计数每个文档中出现的men、women 和people。随时间的推移这些词的用法有什么变化?
import nltk
from nltk.corpus import state_union
cfd = nltk.ConditionalFreqDist(
(target, fileid[:4])
for fileid in state_union.fileids()
for w in state_union.words(fileid)
for target in ['men', 'women', 'people']
if w.lower() == target)
cfd.plot()结果如图所示。
考查一些名词的整体部分关系。请记住,有3 种整体部分关系,所以你需要使用part_meronyms(),substance_meronyms(),member_holonyms(), part_holonyms()以及substance_holonyms()。
import nltk
from nltk.corpus import wordnet as wn
print(wn.synset('tree.n.01').member_holonyms()) #树(tree.n.01)的上位集合--森林
print(wn.synset('tree.n.01').substance_meronyms()) #树的实质子集--芯材和边材
print(wn.synset('tree.n.01').part_meronyms()) #树的结构子集--树干、树冠等
print(wn.synset('mint.n.04').part_holonyms())
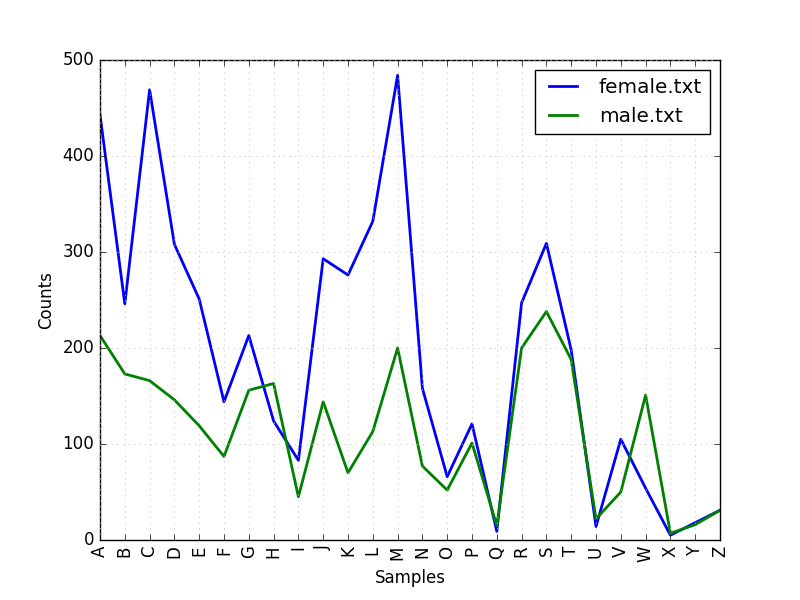
print(wn.synset('mint.n.04').substance_holonyms())在名字语料库上定义一个条件频率分布,显示哪个首字母在男性名字中比在女性名字中更常用.
import nltk
from nltk.corpus import names
cfd = nltk.ConditionalFreqDist(
(fileid, name[0])
for fileid in names.fileids()
for name in names.words(fileid)
)
cfd.plot()结果如图
挑选两个文本,研究它们之间在词汇、词汇丰富性、文体等方面的差异。你能找出几个在这两个文本中词意相当不同的词吗?例如:在《白鲸记》与《理智与情感》中的monstrous。白鲸记Moby Dick情感和理智Sense and Sensibility
import nltk
from nltk.book import *
print(len(text1)) # text1为白鲸记,是text格式,不必写作len(text1.words())
print(len(set(text1))) # 白鲸记中的词汇量
print(len(set(text2))) # 理智与情感中的词汇量
#按照新闻文体统计其中can、could、may、might、must、will出现的频数
from nltk.corpus import brown
next_text = brown.words(categories = 'news')
fdist = nltk.FreqDist([w.lower() for w in next_text])
modals = ['can', 'could', 'may', 'might', 'must', 'will']
for m in modals:
print(m+':', fdist[m])
#查看白鲸记和情感与理智中的monstrous
text1.concordance('monstrous')
text2.concordance('monstrous')
text1.similar('monstrous')
text2.similar('monstrous')调查模式分布表,寻找其他模式。试着用你自己对不同文体的印象理解来解释它们。你能找到其他封闭的词汇归类,展现不同文体的显著差异吗?
import nltk
from nltk.corpus import brown
cfd = nltk.ConditionalFreqDist(
(genre, word)
for genre in brown.categories()
for word in brown.words(categories=genre))
word = ['love', 'like', 'point', 'company']
genres = ['news', 'romance']
cfd.tabulate(conditions=genres, samples=word)CMU 发音词典包含某些词的多个发音。它包含多少种不同的词?具有多个可能的发音的词在这个词典中的比例是多少?

import nltk
from nltk.corpus import cmudict
entries = cmudict.entries()
raw = cmudict.words()
print("the words number is %d, the unique words number is %d" % (len(entries), len(set(raw))))
dictionary = []
for word in entries:
dictionary.append(word[0])
print(len(dictionary))
print(len(set(dictionary)))没有下位词的名词同义词集所占的百分比是多少?你可以使用wn.all_synsets(‘n’)得到所有名词同义词集。
import nltk
from nltk.corpus import wordnet as wn
all_noun_dict = wn.all_synsets('n')
all_noun_num = len(set(all_noun_dict))
noun_have_hypon = filter(lambda ss: len(ss.hyponyms()) <= 0, wn.all_synsets('n'))
noun_have_num = len(list(noun_have_hypon))
print('There are %d nouns, and %d nouns without hyponyms, the percentage is %f' %
(all_noun_num, noun_have_num, noun_have_num/all_noun_num*100))写一个程序,找出所有在布朗语料库中出现至少3 次的词。
import nltk
from nltk.corpus import brown
text = [w.lower() for w in brown.words() if w.isalpha()]
fdist = nltk.FreqDist(text)
freqList = list(fdist.items())
output = []
for m in freqList:
if m[1] >= 3:
output.append(m[0])
print(output)