上周那个在DOTA2 TI8赛场上“装逼失败”的OpenAI Five,背后是强化学习的助推。
其实不仅仅是OpenAI Five,下围棋的AlphaGo和AlphaGo Zero、玩雅达利街机游戏的DeepMind DQN(deep Q-network),都离不开强化学习(Reinforcement Learning)。
现在,谷歌发布了一个基于TensorFlow的强化学习开源框架,名叫Dopamine。
另外,还有一组Dopamine的教学colab。
和它的名字Dopamine(多巴胺)一样,新框架听上去就令人激动。
清晰,简洁,易用
新框架在设计时就秉承着清晰简洁的理念,所以代码相对紧凑,大约是15个Python文件,基于Arcade Learning Environment (ALE)基准,整合了DQN、C51、 Rainbow agent精简版和ICML 2018上的Implicit Quantile Networks。
可再现
新框架中代码被完整的测试覆盖,可作为补充文档的形式,也可以用ALE来评估。
基准测试
为了让研究人员能快速比较自己的想法和已有的方法,该框架提供了DQN、C51、 Rainbow agent精简版和Implicit Quantile Networks的玩ALE基准下的那60个雅达利游戏的完整训练数据,以Python pickle文件和JSON数据文件的格式存储,并且放到了一个可视化网页中。
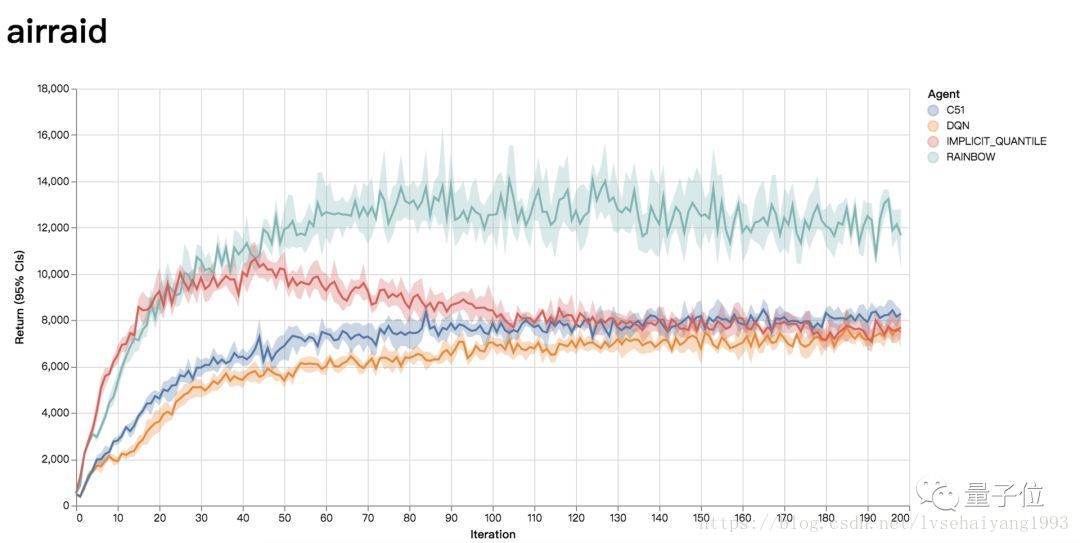
另外,新框架中还有训练好的深度网络、原始统计日志,以及TensorBoard标注好的TensorFlow事件文件。
传送门 开源框架资源
Dopamine谷歌博客:
https://ai.googleblog.com/2018/08/introducing-new-framework-for-flexible.html
Dopamine github下载:
https://github.com/google/dopamine/tree/master/docs#downloads
colabs:
https://github.com/google/dopamine/blob/master/dopamine/colab/README.md
游戏训练可视化网页:
https://google.github.io/dopamine/baselines/plots.html
相关资料
ALE基准:
https://arxiv.org/abs/1207.4708
DQN(DeepMind):
https://storage.googleapis.com/deepmind-media/dqn/DQNNaturePaper.pdf
C51(ICML 2017):
https://arxiv.org/abs/1707.06887
Rainbow:
https://arxiv.org/abs/1710.02298
Implicit Quantile Networks(ICML 2018):