协调过滤推荐概述
协同过滤(Collaborative Filtering)作为推荐算法中最经典的类型,包括在线的协同和离线的过滤两部分。所谓在线协同,就是通过在线数据找到用户可能喜欢的物品,而离线过滤,则是过滤掉一些不值得推荐的数据,比比如推荐值评分低的数据,或者虽然推荐值高但是用户已经购买的数据。
协同过滤的模型一般为m个物品,m个用户的数据,只有部分用户和部分数据之间是有评分数据的,其它部分评分是空白,此时我们要用已有的部分稀疏数据来预测那些空白的物品和数据之间的评分关系,找到最高评分的物品推荐给用户。
三种协同过滤推荐
一般来说,协同过滤推荐分为三种类型。第一种是基于用户(user-based)的协同过滤,第二种是基于项目(item-based)的协同过滤,第三种是基于模型(model based)的协同过滤。
协同过滤的优缺点:直通车
基于用户(user-based)的协同过滤主要考虑的是用户和用户之间的相似度,只要找出相似用户喜欢的物品,并预测目标用户对对应物品的评分,就可以找到评分最高的若干个物品推荐给用户。而基于项目(item-based)的协同过滤和基于用户的协同过滤类似,只不过这时我们转向找到物品和物品之间的相似度,只有找到了目标用户对某些物品的评分,那么我们就可以对相似度高的类似物品进行预测,将评分最高的若干个相似物品推荐给用户。比如你在网上买了一本机器学习相关的书,网站马上会推荐一堆机器学习,大数据相关的书给你,这里就明显用到了基于项目的协同过滤思想。
我们可以简单比较下基于用户的协同过滤和基于项目的协同过滤:基于用户的协同过滤需要在线找用户和用户之间的相似度关系,计算复杂度肯定会比基于基于项目的协同过滤高。但是可以帮助用户找到新类别的有惊喜的物品。而基于项目的协同过滤,由于考虑的物品的相似性一段时间不会改变,因此可以很容易的离线计算,准确度一般也可以接受,但是推荐的多样性来说,就很难带给用户惊喜了。一般对于小型的推荐系统来说,基于项目的协同过滤肯定是主流。但是如果是大型的推荐系统来说,则可以考虑基于用户的协同过滤,当然更加可以考虑我们的第三种类型,基于模型的协同过滤。
基于模型(model based)的协同过滤是目前最主流的协同过滤类型了,我们的一大堆机器学习算法也可以在这里找到用武之地。下面我们就重点介绍基于模型的协同过滤。
我们将使用MovieLens数据集,它是在实现和测试推荐引擎时所使用的最常见的数据集之一。它包含来自于943个用户以及精选的1682部电影的100K个电影打分。数据下载连接,相关数据说明直通车
步骤
读取原始数据构建矩阵
从原始数据中读取,并建立dataframe:
#u.data文件中包含了完整数据集。
u_data_path="C:\\Users\\lenovo\\Desktop\\ml-100k\\"
header = ['user_id', 'item_id', 'rating', 'timestamp']
df = pd.read_csv(u_data_path+'ml-100k/u.data', sep='\t', names=header)
print(df.head(5))
print(len(df))
#观察数据前5行。接下来,让我们统计其中的用户和电影总数。
n_users = df.user_id.unique().shape[0] #unique()为去重.shape[0]行个数
n_items = df.item_id.unique().shape[0]
print ('Number of users = ' + str(n_users) + ' | Number of movies = ' + str(n_items))
#切割训练集与测试级
from sklearn import model_selection as cv
train_data, test_data = cv.train_test_split(df, test_size=0.25)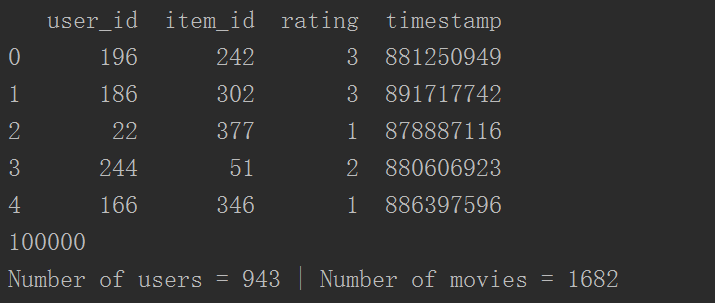
基于内容协同过滤法可以被主要分为两部分:用户-项目过滤(user-item filtering)和项目-项目过滤( item-item filtering)。 user-item filtering选取一个特定用户,基于评价相似性找到与该用户相似的其他用户,并推荐那些相似用户所喜欢的项目。相比之下, item-item filtering 先选取一个项目,然后找出也喜欢这个项目的其他用户,并找出这些用户或相似用户也喜欢的其他项目,推荐过程需要项目并输出其他项目。
Item-Item Collaborative Filtering: “Users who liked this item also liked …”
User-Item Collaborative Filtering: “Users who are similar to you also liked …”
在这两种情况中,你根据整个数据集创建了一个用户-项目的矩阵。因为已经把数据分成了测试和训练两部分所以你需要创建两个[943 x 1682]矩阵。训练矩阵包含75%的评价,测试矩阵包含25%的矩阵。
用户-项目矩阵例子: 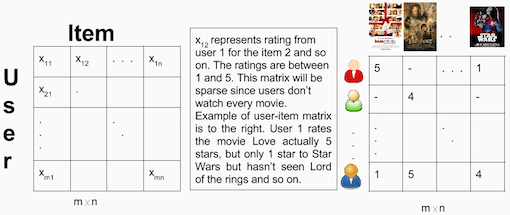
创建了用户-项目矩阵之后,计算相似性并创建一个相似度矩阵。
在产品-产品协同过滤中的产品之间的相似性值是通过观察所有对两个产品之间的打分的用户来度量的。
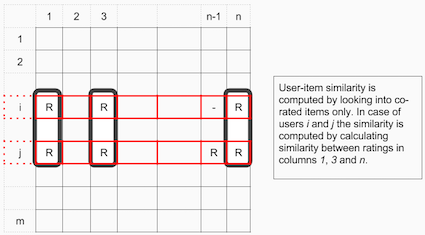
对于用户-产品协同过滤,用户之间的相似性值是通过观察所有同时被两个用户打分的产品来度量的。
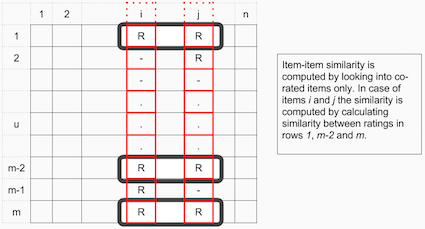
Item-Item Collaborative Filtering算法中项目之间的相似度依靠观测所有的已对相同项目评价的用户来测算。
对于User-Item Collaborative Filtering算法,用户之间的相似性依靠观测相同用户已评价的所有项目。
推荐系统中通常使用余弦相似性作为距离度量,在n维孔空间中评价被视为向量,基于这些向量之间的夹角来计算相似性。
用户a和m可以用下面的公式计算余弦相似性,其中你可以使用用户向量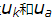
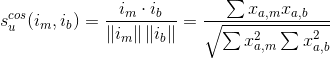
要计算产品m和b之间的相似性,使用公式:
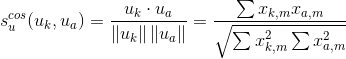
创建两个矩阵为测试和训练数据集。

#Create two user-item matrices, one for training and another for testing
#差别在于train_data与test_data
train_data_matrix = np.zeros((n_users, n_items))
print(train_data_matrix.shape)
for line in train_data.itertuples():
# print(line)
# print("line={}\nlen(line)={}\n,line[1]={}\n,line[1]-1={}\n,line[2]={}\n,line[2]-1={}\n".format(line,len(line),line[1],line[1]-1,line[2],line[2]-1))
train_data_matrix[line[1]-1, line[2]-1] = line[3]
test_data_matrix = np.zeros((n_users, n_items))
for line in test_data.itertuples():
test_data_matrix[line[1]-1, line[2]-1] = line[3]计算相似度
# 你可以使用 sklearn 的pairwise_distances函数来计算余弦相似性。注意,因为评价都为正值输出取值应为0到1.
from sklearn.metrics.pairwise import pairwise_distances
user_similarity = pairwise_distances(train_data_matrix, metric='cosine')
#矩阵的转置实现主题的相似度
item_similarity = pairwise_distances(train_data_matrix.T, metric='cosine')预测
下一步是作出预测。既然构造了相似度矩阵user_similarity和item_similarity,因此你可以运用下面的公式为user-based CF做一个预测: 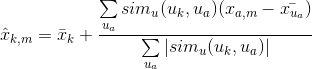
用户k和用户a之间的相似度根据一个相似用户a的一系列评价的乘积(修正为该用户的平均评价)的权重。你将需要标准化相似度这样可以使评价维持在1到5之间,最后一步,统计你想预测用户平均评价的总和。
这里考虑到的问题是一些用户评价所有电影时可能要么给最高分,要么给最低分。这些用户给出评价的相对不同比绝对值更重要。例如:设想,用户k对他最喜欢的电影评价4颗星,其他的好电影则评价3颗星。假设现在另一个用户t对他/她喜欢的一部电影评价为5颗星,看了想睡觉的一部电影评价为3颗星。这两位用户电影口味可能很相似但使用评价体系的方法不同。
当为item-based CF做一个推荐时候,你不要纠正用户的平均评价,因为用户本身用查询来做预测。
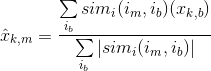
def predict(ratings, similarity, type='user'):
if type == 'user':
mean_user_rating = ratings.mean(axis=1)
#You use np.newaxis so that mean_user_rating has same format as ratings
ratings_diff = (ratings - mean_user_rating[:, np.newaxis])
pred = mean_user_rating[:, np.newaxis] + similarity.dot(ratings_diff) / np.array([np.abs(similarity).sum(axis=1)]).T
elif type == 'item':
pred = ratings.dot(similarity) / np.array([np.abs(similarity).sum(axis=1)])
return pred两种方法预测
item_prediction = predict(train_data_matrix, item_similarity, type='item')
user_prediction = predict(train_data_matrix, user_similarity, type='user')评估
有许多的评价指标,但是用于评估预测精度最流行的指标之一是Root Mean Squared Error (RMSE)。 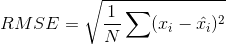
你可以用sklearn中的 mean_square_error (MSE)函数,RMSE只是MSE其中的一个平方根。想阅读更多关于不同评估指标你可以 查看这篇文章。
因为你仅仅想考虑在这个测试数据集中的预测评价,你可以用prediction[ground_truth.
nonzero()]过滤测试矩阵中所有其他的元素。
#有许多的评价指标,但是用于评估预测精度最流行的指标之一是Root Mean Squared Error (RMSE)。
from sklearn.metrics import mean_squared_error
from math import sqrt
def rmse(prediction, ground_truth):
prediction = prediction[ground_truth.nonzero()].flatten()#nonzero(a)返回数组a中值不为零的元素的下标,相当于对稀疏矩阵进行提取
ground_truth = ground_truth[ground_truth.nonzero()].flatten()
return sqrt(mean_squared_error(prediction, ground_truth))
print ('User-based CF RMSE: ' + str(rmse(user_prediction, test_data_matrix)))
print ('Item-based CF RMSE: ' + str(rmse(item_prediction, test_data_matrix))) 
Memory-based算法容易实施并产生合理的预测质量。memory-based CF的缺点是它不能扩展到现实世界的场景和没有处理众所周知的冷启动问题(面对新用户或者新项目进去系统时)。Model-based CF方法可伸缩并且能处理 比memory-based方法更高等级的稀疏度,面对新用户或者没有任何评价的新项目进入系统时也会变差。
参考文献:Ethan Rosenthal关于Memory-Based Collaborative Filtering的博客直通车
画一个图来诠释以下,基于usr的,画的不好多多见谅!!!

完整代码:
#!usr/bin/env python
#_*_ coding:utf-8 _*_
"""
title:python 实现协同过滤算法基于用户与基于内容
"""
import numpy as np
import pandas as pd
#u.data文件中包含了完整数据集。
u_data_path="C:\\Users\\lenovo\\Desktop\\ml-100k\\"
header = ['user_id', 'item_id', 'rating', 'timestamp']
df = pd.read_csv(u_data_path+'ml-100k/u.data', sep='\t', names=header)
print(df.head(5))
print(len(df))
#观察数据前两行。接下来,让我们统计其中的用户和电影总数。
n_users = df.user_id.unique().shape[0] #unique()为去重.shape[0]行个数
n_items = df.item_id.unique().shape[0]
print ('Number of users = ' + str(n_users) + ' | Number of movies = ' + str(n_items))
from sklearn import model_selection as cv
train_data, test_data = cv.train_test_split(df, test_size=0.25)
#Create two user-item matrices, one for training and another for testing
#差别在于train_data与test_data
train_data_matrix = np.zeros((n_users, n_items))
print(train_data_matrix.shape)
for line in train_data.itertuples():
train_data_matrix[line[1]-1, line[2]-1] = line[3
test_data_matrix = np.zeros((n_users, n_items))
for line in test_data.itertuples():
test_data_matrix[line[1]-1, line[2]-1] = line[3]
# 你可以使用 sklearn 的pairwise_distances函数来计算余弦相似性。注意,因为评价都为正值输出取值应为0到1.
from sklearn.metrics.pairwise import pairwise_distances
user_similarity = pairwise_distances(train_data_matrix, metric='cosine')
#矩阵的转置实现主题的相似度
item_similarity = pairwise_distances(train_data_matrix.T, metric='cosine')
def predict(ratings, similarity, type='user'):
if type == 'user':
mean_user_rating = ratings.mean(axis=1)
#You use np.newaxis so that mean_user_rating has same format as ratings
ratings_diff = (ratings - mean_user_rating[:, np.newaxis])
pred = mean_user_rating[:, np.newaxis] + similarity.dot(ratings_diff) / np.array([np.abs(similarity).sum(axis=1)]).T
elif type == 'item':
pred = ratings.dot(similarity) / np.array([np.abs(similarity).sum(axis=1)])
return pred
item_prediction = predict(train_data_matrix, item_similarity, type='item')
user_prediction = predict(train_data_matrix, user_similarity, type='user')
#有许多的评价指标,但是用于评估预测精度最流行的指标之一是Root Mean Squared Error (RMSE)。
from sklearn.metrics import mean_squared_error
from math import sqrt
def rmse(prediction, ground_truth):
prediction = prediction[ground_truth.nonzero()].flatten()#nonzero(a)返回数组a中值不为零的元素的下标,相当于对稀疏矩阵进行提取
ground_truth = ground_truth[ground_truth.nonzero()].flatten()
return sqrt(mean_squared_error(prediction, ground_truth))
print ('User-based CF RMSE: ' + str(rmse(user_prediction, test_data_matrix)))
print ('Item-based CF RMSE: ' + str(rmse(item_prediction, test_data_matrix)))