CRNN是《An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition》中提出的模型,解决图像中文字识别问题。
论文地址:https://arxiv.org/abs/1507.05717
github地址:https://github.com/bgshih/crnn
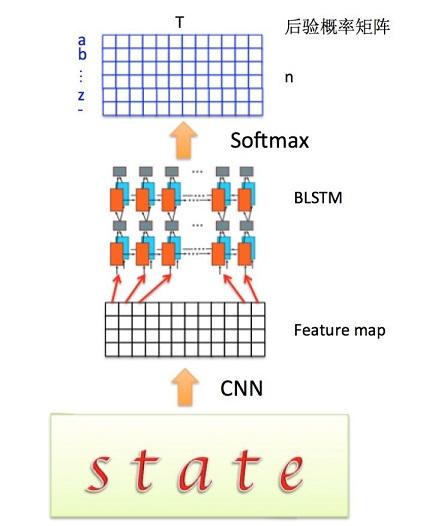
1:结构图
主要包括:卷积层(CNN),循环层(RNN),转录层(CTC)

2:整个网络模型的特点
- 可以直接从序列标签学习,不用给每个字符打标签,只需要给一个图片打一个序列标签,例如:图片中是“abc123”,标签即是“abc123”,不用给每个字符单独打标签。
- 利用CNN提取的图片特征
- 利用RNN训练的输入的特征序列,输出的是一个序列标签
- 对要训练的图片没有长度限制,但是要将图片的高度归一化。
- 参数少
- 虽然结合了CNN和RNN,但最后用一个loss函数(CTC LOSS),实现了端到端的训练。
3:CRNN中的重点,也就是CTC(connectionist temporal classification)原文出自《Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks》
首先,CRNN第一步是将训练的图片送入到CNNji进行卷积提取特征,得到feature map
然后,将feature map的每一列(这里先简化处理,认为一列就是一个LSTM时间序列,CRNN网络结构后面分析)或者每几列作为一个时间序列输入特征,送入RNN(双向LSTM)
先看一下流程图:
- CNN feature map
假设CNN得到的feature map 大小为 ,下文得到的时间序列
都从
开始,即
。
则输入到RNN中的时间序列定义为 :,
其中每一列为:
- RNN(双向LSTM)
LSTM的每个时间片后接一个softmax,输出的是一个后验概率矩阵,大小为n*T,T代表时间序列总共T列,n代表有词典中有n个标签,定义为:
其中每一列为:
由于是得到的是概率,所以每列的所有字符标签的概率之和为1,即 ,那取每列的最大值,就能得到每一列输出字符的类别,即对每列进行
操作。
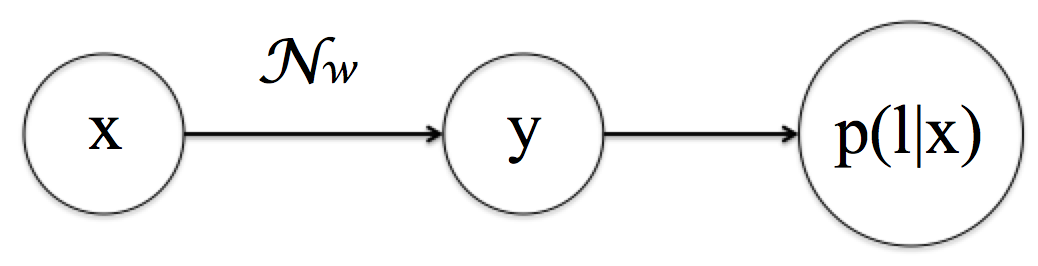
将该LSTM网络看成一个映射 , 其中w为LSTM的参数。m*T 的CNN得到的feature map,输入经LSTM后输出为 n*T, 所以
是做了如下变换:
假设原始的字符标签为L = {a,b,c,......,x,y,z}的26和字母,由于要加一个默认的空格字符blank(作用类似于目标检测中的默认的背景标签),此时的新的字符标签为L‘。
定义B变换:
,表示简单的压缩
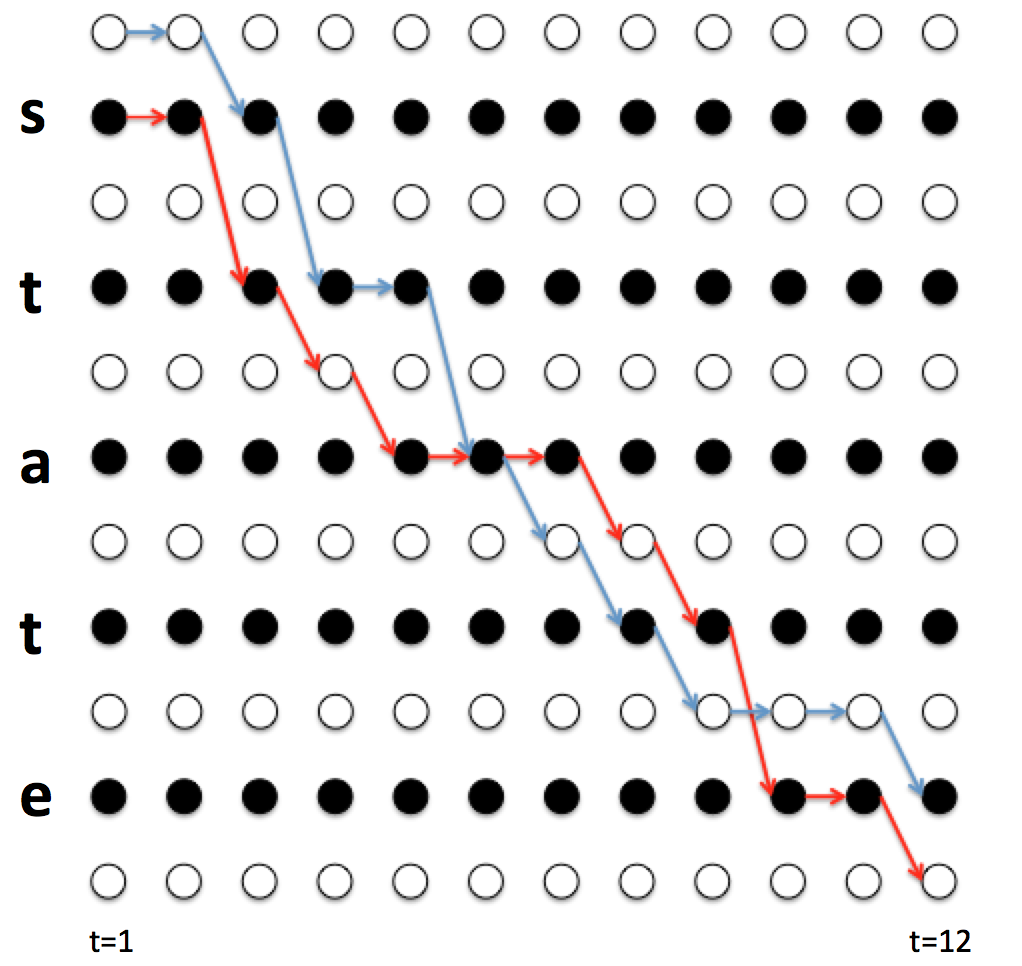
说明:假设T = 12,也就是说有12列,路径为,路径的长度就是T。
如上所示5条路径,看出规律有:若两个字符之间有空格blank 时,则不合并,若没有空格时,相同字符合并为一个。
当获得LSTM经过softmax(注意是softmax不是softmax loss,因为这里用的是CTC loss)得到字符概率得分矩阵后,经argmax()操作后得到的输出y,经过B变换后,即可获得输出结果,显然B变换不是一 一映射的关系。现在我们能通过feature map用每列当做x输入到RNN中,得到概率矩阵,并argmax()操作得到输出,然后用这一步的输出经过B变换规则得到最终的字符预测输出。但是这样的输出和当时的输入的列数不一样(明显不一样,也就是发生了不对齐的现象。),训练需要反向传播来更新参数,所以,怎样利用得到的预测输出来计算loss呢。
如果输出是用的softmax得到的概率矩阵,每列对应的是输出都对应标签中的一个字符。那么训练时候每张样本图片都需要标记出每个字符在图片中的位置,再通过CNN感受野对齐到Feature map的每一列,如图3,才能进行训练。
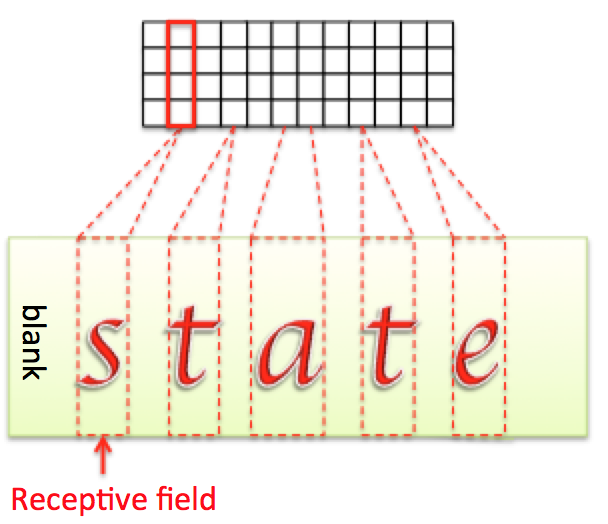
在实际应用中,标记这样的对齐样本非常困难,工作量非常大,所以CTC提出了一种不需要对齐的Loss计算方法,用于训练网络。
先来计算一下,路径的数目:假设T = 30,最后的输出为“state”,五个字符,共有条路径可以被压缩成【state】。路径数目的计算公式为
。
CTC的做法:
对于LSTM给定输入 的情况下,输出为
的概率为:
上边的式子说明:输入的情况下,输出为
的概率为:条件为输入为
,进过B变换后输出为
的所有路径的概率之和。
那么每一条路径的概率怎么算呢:
上边的式子说明:每一条路径的概率为该条路径的每一个时刻的输出的连乘。
我们的目标函数就相当于是
但是路径数目庞大,是无法直接计算的,所以CTC方法中借用了HMM中向前向后算法(forward-backward algorithm)来计算。
CTC的训练过程,本质上是通过梯度 调整LSTM的参数
,使得对于输入样本为
时有
取得最大。
定义所有经 变换后结果是
且在
时刻结果为
(记为
)的路径集合为
。
求导:
注意上式中第二项与 无关,所以:
首先来理解一下上边的式子:是
时刻 输出字符为
的概率。上边的求导公式中的
理解为:由于总归的路线数目巨大,我这里求导只需要计算经过
时刻 输出字符为
的所有路径。示意图如下:
假设是t=6时刻,k = a字符。那么依据上图经过这个点的路径有两条(没画出来的还有好几条),假设总共有四条路径经过该点,分别为
,所有类似于
经过
变换后结果是
且在
的路径集合表示为
。
观察 。记
蓝色为
,
红色路径为
。那么
可以表示:
可以是
经过交叉点后互换下半段路径:
计算:
为了观察规律,单独计算 。
令:
那么可以表示为:
推广一下,所有经过 变换为
且
的路径(即
)可以写成如下形式:
进一步推广,所有经过 变换为
且
的路径(即
)也都可以写作:
所以,定义forward :
对于一个长度为 的路径
,其中
代表该路径前
个字符,
代表后
个字符。
其中 表示前
个字符
经过
变换为的
的前半段子路径。
观察图7会发现对于 有如下递推关系:
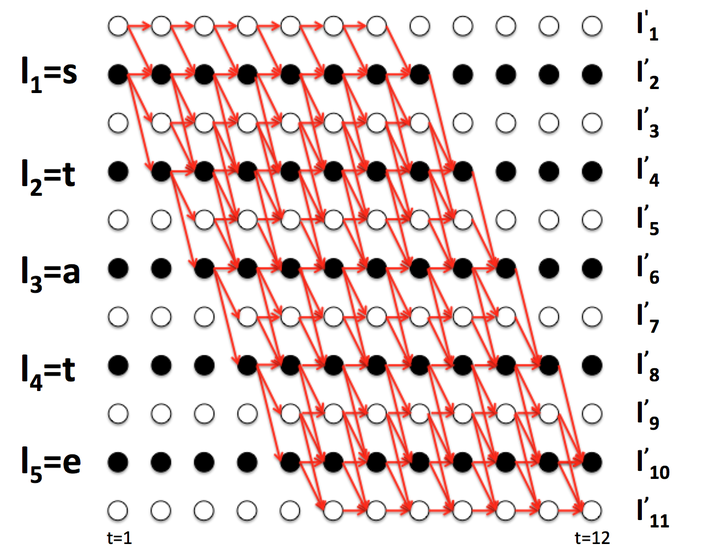
图6
那么更一般的:
上边的怎么理解呢:

蓝色矩形标记的时刻字符点,它的forward受到它前一个时刻的三个方向(黄色箭头)的预测。所以有:
同样,定义backword :
根据

同理对于 有如下递推关系:
那么forward和backward相乘有:
或:
注意, 可以通过图6的关系对应,如
,
。
对比 :
可以得到:
或:
训练CTC
对于LSTM,有训练集合 ,其中
是图片经过CNN计算获得的Feature map,
是图片对应的ocr字符label(label里面没有blank字符)。
现在我们要做的事情就是:通过梯度调整LSTM的参数
,使得对于输入样本为
时有
取得最大。所以如何计算梯度才是核心。
单独来看LSTM输出 矩阵中的某一个值
(注意
与
含义相同,都是在
时
的概率):
获得梯度 后就好办了,其中的
可以通过递推快速计算,那么梯度下降算法你懂的。
CTC总结
CTC是一种Loss计算方法,用CTC代替Softmax Loss,训练样本无需对齐。
CTC特点:
- 同时引入blank字符,解决有些位置没有字符的问题
- 通过递推,快速计算梯度