1.彻底理解cookie,session,token
参考:https://www.cnblogs.com/moyand/p/9047978.html
2.反爬虫技巧
http://python.jobbole.com/89196/(未完全明白)
3.python(字符编码)
https://www.cnblogs.com/zihe/p/6993891.html
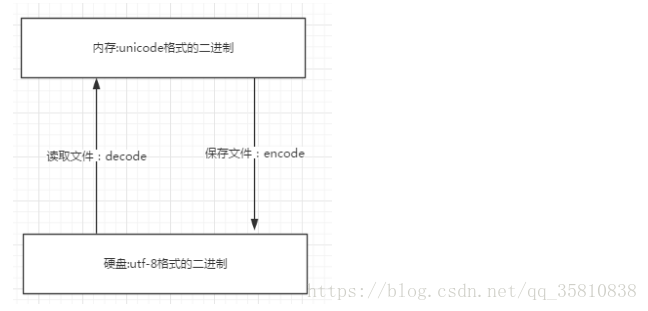
文件以什么编码保存的,就以什么编码方式打开。而文件编码保存时候使用的编码方式是右下角的编码方式,而解码的时候是使用文档开头申明的编码方式,两种编码不同的时候很容易出现乱码的情况
编码:将字符串转为字节码 encode 适合计算机看
解码:将字节码转换为字符串 decode 适合我们看
-----------------------------------------------------------------------------------------------------
字符串存到文件中(硬盘上),字符的unicode是不能直接存储的,必须以一种编码方式(utf8)转为连续的字节(bytes)
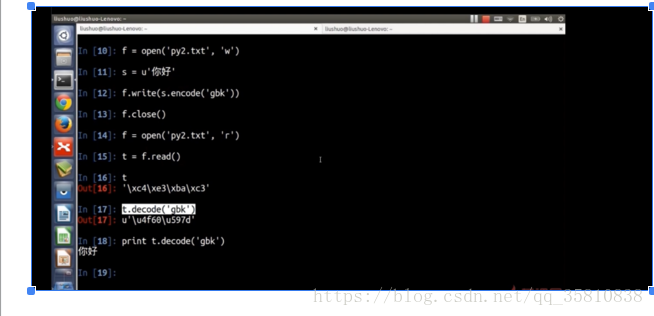
在python2中,字符有两种类型(str (已经编码后的字节序列) unicode(编码前的文本字符))
python2中文本文件的读写
python3中的两种字符类型(str(编码过得unicode文本字符,双引号,单引号) bytes(编码前的字节序列))
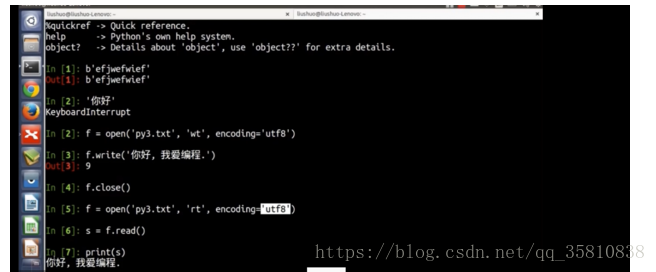
可以认为字符串有两种状态,即文本状态和字节(二进制)状态。Python2 和 Python3 中的两种字符类型都分别对应这两种状态,然后相互之间进行编解码转化。
python2在文件读写时用encode,decode解决。python3用encoding解决
查看Python默认编码方式
print(sys.getdefaultencoding()) #python3 print sys.getdefaultencoding() #python2
Python2 中,str 和 unicode 都有 encode 和 decode 方法。但是不建议对 str 使用 encode,对 unicode 使用 decode, 这是 Python2 设计上的缺陷。
Python3 则进行了优化,str 只有一个 encode 方法将字符串转化为一个字节码,而且 bytes 也只有一个 decode 方法将字节码转化为一个文本字符串。
Python2 的 str 和 unicode 都是 basestring 的子类,所以两者可以直接进行拼接操作。而 Python3 中的 bytes 和 str 是两个独立的类型,两者不能进行拼接。
Python2 中,普通的,用引号括起来的字符,就是 str;此时字符串的编码类型,对应着你的 Python 文件本身保存为何种编码有关,最常见的 Windows 平台中,默认用的是 GBK。Python3 中,被单引号或双引号括起来的字符串,就已经是 Unicode 类型的 str 了。
ython3默认是'utf-8'编码,字符串str为unicode,当存储到文件时需要转换为bytes,读取是要转换为str(unicode)的形式,文件的读写是,encoding这个参数会帮我们自动完成,这就是python3的优势。