在本章中,您将学习:
•各种内存分配,性能特征及其局限性
•如何在Rust中指定要用于对象的内存分配
•引用和盒子之间的差异
各种分配
要理解Rust语言,还要了解任何其他系统编程语言(如C语言),了解内存分配的各种概念(如静态分配,堆栈分配和堆分配)非常重要。
本章完全致力于此类问题。 特别是,我们将看到四种内存分配:
•在处理器寄存器中
• 静态的
•在堆栈中
•在堆中
在C和C ++语言中,静态分配是全局变量和使用static关键字声明的变量的静态分配; 堆栈分配是用于所有非静态局部变量的,也用于函数参数; 堆分配是通过调用C语言标准库的mallocfunction或C ++语言的new运算符来使用的。
线性寻址
在任何计算机硬件中,都有一个可读写的存储器,也称为RAM,它由一长串字节组成,可通过它们的位置访问。 存储器的第一个字节的位置为零,而最后一个字节的位置等于已安装的存储器的大小减去1。
简化,在我们这个时代有两种计算机:
•一次可以运行单个进程的那些进程,以及此类进程直接使用物理内存地址的那些进程。 这些被称为“真实存储系统”。
•具有多道程序设计操作系统的操作系统,为每个正在运行的进程提供虚拟地址空间。 这些被称为“虚拟内存系统”。
在第一类计算机中,现在仅用作控制器,可能没有操作系统(因此它们也被称为“裸机系统”),或者可能存在驻留在第一部分的操作系统。 记忆。 在最后一种情况下,应用程序可以使用大于某个值的地址。
在第二类计算机中,访问系统存储器任何部分的能力保留给操作系统,操作系统以特权模式(也称为“保护模式”或“内核模式”)运行,并且此类软件分配 各种运行进程的内存部分。
然而,在多道程序设计系统中,这些过程“看到”它们的内存与操作系统“看到”它的方式不同。考虑这一点:一个进程要求操作系统允许使用200多个内存字节,并且操作系统通过保留这样的进程来满足这样的请求,例如,从机器位置300到机器位置499的内存部分。然后,操作系统传达已经分配了200个字节的过程,但它没有与它通信这个部分内存的起始地址是300.实际上每个进程都有一个不同的地址空间,正确地称为“虚拟”,操作系统映射到物理记忆,恰当地称为“真实”。
实际上,当进程向操作系统询问某些内存时,操作系统只保留该进程的一部分地址空间,并且实际上没有为该进程保留实际内存。结果,即使对于非常大的存储器部分,这种分配也非常快。
只要进程尝试访问此类内存,即使只将其初始化为零,操作系统也会意识到进程正在访问尚未映射到实际内存的虚拟内存部分,并且它会立即执行所访问虚拟内容的映射 存储器部分到相应的实存储器部分。
因此,进程不直接在实际内存上运行,而是在操作系统可用的虚拟内存上运行,并映射到实际内存。
实际上,通常单个进程的虚拟内存甚至比计算机的整个实际内存都要大。 例如,您可以拥有一台具有1千兆字节物理(实际)内存的计算机,以及在此类计算机上运行的四个进程,每个进程的虚拟内存空间为3千兆字节。 如果所有虚拟内存都映射到实际内存,则要处理这种情况需要12 GB的内存。 相反,虚拟内存的大多数字节都没有映射到实际内存; 只有进程实际使用的字节才会映射到实际内存。 只要进程开始使用其地址空间的部分尚未映射到实际存储器,操作系统就将虚拟存储器的这些部分映射到实际存储器的相应部分。
因此,每当进程访问,读取或写入地址时,如果这样的地址属于保留并映射到实际存储器的相应部分的虚拟存储器部分(称为“页面”),则该进程立即访问这样的实际存储器。; 相反,如果页面被保留但目前没有被映射,操作系统在允许这样的访问之前,在称为“页面错误”的机制中启动,通过该机制,它分配一个真实的内存页面并将其映射到虚拟内存页面 包含访问的地址; 相反,如果访问的地址不属于操作系统保留的页面作为进程的地址空间的一部分,则发生寻址错误(通常称为“分段错误”)。 通常,寻址错误会导致过程立即终止。
当然,如果程序过于宽松地使用内存,操作系统可能会花费大量时间来进行这种映射,从而导致进程大幅减速,甚至终止内存不足。
因此,在现代计算机中,无论是单程序还是多程序计算机,每个进程都“看到”它的存储器就像一个字节数组。 在一种情况下它是真实存储器,而在另一种情况下它是虚拟存储器,但无论如何它是一个连续的地址空间,或者,正如通常所说的那样,使用“线性寻址”。 这与使用“分段”地址空间的旧计算机系统不同,应用程序员使用它们更加麻烦。
据说所有这些都说明,在虚拟内存系统中,操作系统管理一种内存分配,即从虚拟内存到实内存的映射。 虽然,从现在开始,我们将永远不再讨论这种内存分配,并且我们将内存分配定义为保留进程“看到”的一部分内存并将这样的内存部分与对象相关联的操作。
静态分配
但是,有各种分配政策。
最简单的分配策略是“静态”分配。 根据这样的策略,编译器确定程序的每个对象需要多少个字节,并且连续地从地址空间获取相应的字节序列。 因此,每个变量的地址在编译时确定。 这是Rust的一个例子:
static _A: u32 = 3;
static _B: i32 = -1_000_000;
static _C: f64 = 5.7e10;
static _D: u8 = 200;
static关键字类似于let关键字。 两者都用于声明变量并可选地初始化它。
静态和let之间的区别是:
•static使用静态分配,而let使用堆栈分配。
•static需要明确指定变量的类型,使用let是可选的。
•正常代码不能更改静态变量的值,即使它具有mut规范。 因此,出于安全原因,在Rust中,静态变量通常是不可变的。
•样式指南要求静态变量的名称仅包含大写字母,单词用下划线分隔。 如果违反此规则,编译器将报告警告。
在这四个方面中,这里我们只看到第一个关于分配类型的方面。
_A和_B变量各占4个字节,_C占用8个字节,而_D仅占1个字节。 如果进程的地址从零开始(通常为假),则编译器会将_A分配给地址0,将_B分配给地址4,将_C分配给地址8,将_D分配给地址16,总共为 编译时分配17个字节。
程序启动时,该过程要求操作系统使用17个字节的内存。 然后,在执行期间,不再执行存储器请求。 当进程终止时,所有进程内存将自动释放到操作系统。
静态分配的缺点是不可能创建递归函数,递归函数是直接或间接调用自身的函数。 实际上,如果函数的参数和局部变量是静态分配的,那么它们只有一个副本,当函数调用自身时,它不能拥有其参数和局部变量的另一个副本。
静态分配的另一个缺点是所有子程序的所有变量都是在程序开始时分配的,如果程序包含许多变量,但每个特定的执行仅使用它们中的一小部分,则许多变量被无用地分配, 程序内存饥渴。
另外,静态变量的修改是不安全的。
因此,在Rust中,它们并没有被大量使用。
但是,静态分配广泛用于另外两种数据:所有可执行的二进制代码(实际上并非真正的“数据”),以及所有字符串文字。
堆栈分配
由于静态分配的缺点,每次使用let关键字声明变量时,每次将参数传递给函数调用时,Rust都会在“堆栈”中分配一个对象。 所谓的“堆栈”是每个进程的地址空间的一部分。
实际上,每个线程都有一个堆栈,而不是每个进程都有一个堆栈。 如果操作系统支持线程,那么,每次启动程序时,即每次创建进程时,都会在此进程内创建并启动一个线程。 然后,在同一进程内,可以创建并启动其他线程。 每次创建一个线程(包括进程的主线程)时,都要求操作系统分配一部分地址空间,即该线程的堆栈。 在实内存系统中,在程序执行开始时只创建一个堆栈。
每个线程保持存储其堆栈末尾的地址。 通常,具有较高值的末端被认为是堆栈的基础,具有较低值的末端被认为是堆栈的顶部。 让我们考虑以下代码,类似于前一个代码,但使用堆栈分配而不是静态分配:
let _a: u32 = 3;
let _b: i32 = -1_000_000;
let _c: f64 = 5.7e10;
let _d: u8 = 200;
这个程序只有一个线程。 现在假设,这个线程只有100个字节的堆栈,地址从500包括到600排除,这是非常不现实的。 运行此程序时,将从基地址(即600)分配四个变量。
因此,如图11-1所示,_a变量将占用4个字节,地址从596到599,_b变量将占用4个字节,地址从592到595,_c变量将占用8个字节的地址 从584到591,_d变量将只占用地址为583的字节。
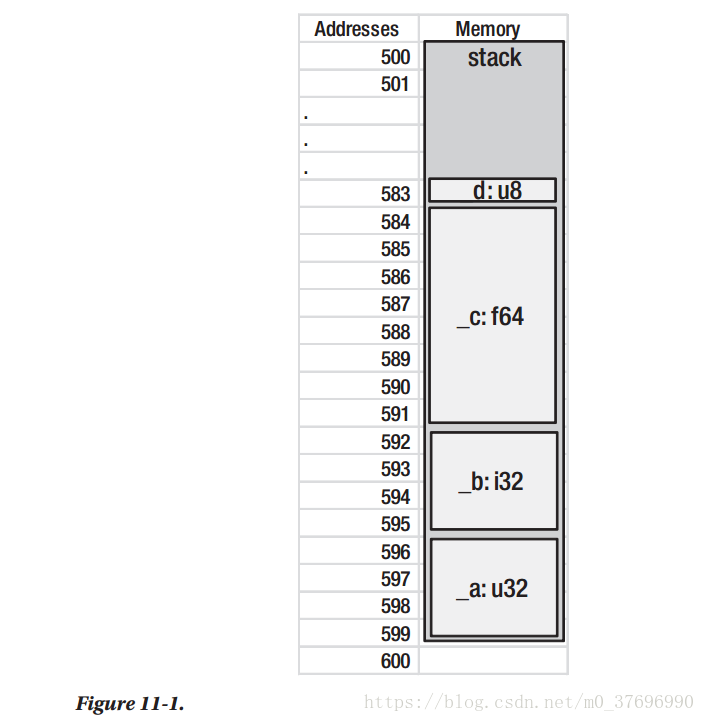
但是,当您需要指示对象的地址时,必须始终指定较低的地址。 因此,我们说_a位于地址596,_b位于地址592,_c位于地址584,_d位于地址583。
“堆叠”这个词指的是如果我们得到一堆中国菜,我们不应该在堆叠中间插入一个盘子,也不要从堆叠中间取出盘子。 我们只允许在堆栈顶部添加一个盘子,如果它还没有到达天花板,或者如果堆栈不是空的话,从盘子的顶部移除一个盘子。
类似地,堆栈分配的特征是您只能在堆栈顶部添加项目,并且只能从堆栈顶部删除。
堆栈分配和释放非常快,因为它们分别包括递减或递增最后插入和尚未移除的项目的地址,这是堆栈“顶部”的地址。 这样的地址被命名为“堆栈指针”,并且它一直保持在处理器寄存器中,直到有上下文切换,并且控制传递给另一个线程。
仅作用于顶部的堆栈限制仅适用于分配和解除分配,而不适用于其他类型的访问。 实际上,一旦将对象添加到堆栈中,即使添加了其他对象,也可以读取和写入该对象,只要这样的写入不会增加或减小该对象的大小。
调用函数时,将为其所有参数及其所有局部变量分配足够的堆栈空间。 通过将堆栈指针递减所有这些对象的大小的总和来执行这种分配。 并且当这种函数的执行终止时,通过将堆栈指针递增相同的值来释放这样的堆栈空间。 因此,在函数返回后,堆栈指针将恢复为函数调用之前的值。
但是,可以从程序中的几个点调用函数,并且在这些点中,堆栈可以具有不同大小的内容。 因此,根据调用此类函数的位置,任何函数的参数和局部变量都分配在不同的位置。 这是一个例子:
fn f1(x1: i32) {
let y1 = 2 + x1;
}
fn f2(x2: i32) {
f1(x2 + 7);
}
let k = 20;
f1(k + 4);
f2(30);
让我们按照这个程序的执行。 该表在每次操作之后显示堆栈的前四个位置的内容。

main的调用将其局部变量k的值20添加到堆栈
x1→20 24 f1的调用将其参数x1的值24加到堆栈中
y1→20 24 26执行f1的开始将其局部变量y1的值26添加到堆栈
←y1 20 24 f1的终止从堆栈中删除其局部变量y1的值26
←x1 20 f1的终止从堆栈中删除其参数x1的值24
x2→20 30 f2的调用将其参数x2的值30添加到堆栈
x1→20 30 37 f1的调用将其参数x1的值37添加到堆栈
y1→20 30 37 39执行f1的开始将局部变量y1的值39添加到堆栈
←y1 20 30 37 f1的终止从堆栈中移除其局部变量y1的值39
←x1 20 30 f1的终止从堆栈中删除其参数x1的值37
←x2 20 f2的终止从堆栈中删除其参数x2的值30
←k终止主要从堆栈中删除其局部变量k的值20
实际上,每当调用一个函数时,都会向堆栈中添加更多数据,每当该函数终止时,这些数据就会从堆栈中删除,但在这里我们可以忽略这些附加数据。正如您在上表中看到的,f1函数被调用两次。第一次,它的参数x1由放在堆栈第二位的对象表示,值为24,其局部变量y1由放在堆栈第三位的对象表示,值为26.相反,第二次调用f1时,其参数x1由放在堆栈第三位的对象表示,值为37,其局部变量y1由放在堆栈第四位的对象表示,值为39 。
因此,为函数f1生成的机器代码不能使用绝对地址来引用其参数及其局部变量。相反,它使用相对于“堆栈指针”的地址。最初,堆栈指针包含堆栈的基址。在机器代码中,堆栈分配的变量的地址都相对于堆栈指针。让我们再看一遍上面的例子。
该表在每次操作之后显示堆栈的前四个位置的内容,堆栈指针的值以及与变量x1和y1相关联的对象的绝对地址,其中SP表示“堆栈指针”。
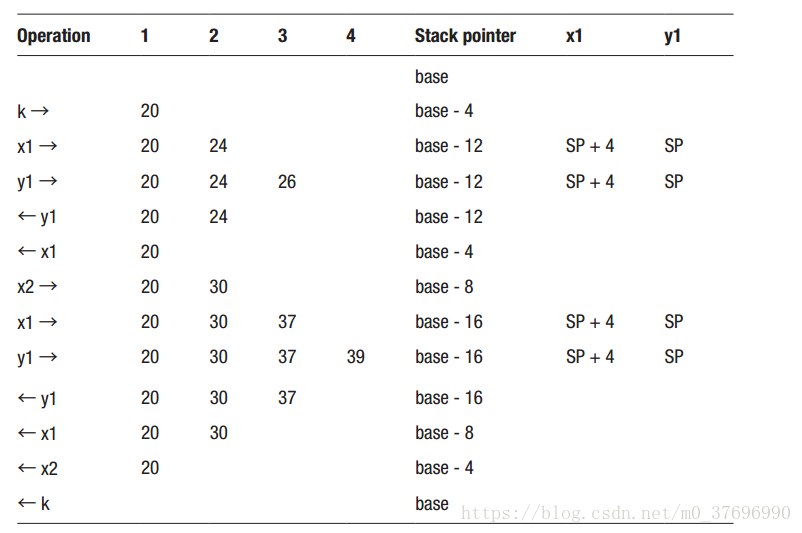
在程序开始时,堆栈指针值是堆栈基址,堆栈的内容是未定义的,并且尚未定义变量x1和y1。
当系统调用main函数时,堆栈指针变为base-4,因为main函数没有参数,只有一个局部变量k,占用4个字节。
当第一次调用f1函数时,堆栈指针变为base-12,因为f1函数有一个参数x1和一个局部变量y1,每个变量占用4个字节。
y1的创建和销毁不会更改堆栈指针,因为它已在函数调用中设置了适当的值。
当函数f1终止时,堆栈指针将恢复为函数调用之前的值,即base-4。
当调用函数f2时,堆栈指针的参数大小增加x2,将其设置为base - 8的值。
当第二次调用f1函数时,堆栈指针变为base-16,因为它的减少量与第一次调用的量相同,即8字节
当f1,f2和main函数中的每一个终止时,堆栈指针递增,首先是base-8,然后是base-4,然后是base。
正如在表的最后两列中所示,在f1函数中,参数x1的地址始终是堆栈指针的值减去4; 并且局部变量y1的地址始终是堆栈指针本身的值。