sed的一些小例子
下面是演示了怎么在每一行开头和结尾同时加某些符号。

下面是演示如何在每一行开头加一个行号,用的是for循环,注意一定是双引号,因为双引号里面$a才能解析输出。

下面做的是这么一件事,把文本中以空格隔开的数字排序,并输出最大和最小值,其中用到了一个sort -nr,-n是按照数值大小排序,r是降序,也就是从大到小,这些我们以前都用过。

复习一下vim
为什么突然说要复习一下vim,下面慢慢看就知道了,主要是vim里有和sed很像的地方。参考了http://www.runoob.com/linux/linux-vim.html
下面这张图还是很实用的。

命令模式转换,底线命令模式我们以前叫做扩展命令模式。当然下面少了一个可视模式,可是模式可以在命令模式下输v,V或者ctrl+v进入不同的可视模式,因为可视模式分为可视,可视行和可视块,vim的内容可以到https://www.bilibili.com/read/cv635562和
https://www.bilibili.com/read/cv642732
去考古。这里只是做一下复习和总结。

按键说明:






:set nu不会影响cat的结果,它只是一次性的添加行号,再次进入vim也会消失。vim里面替换的命令有点像sed,不过需要在扩展模式,那个%是所有行的意思,如果不加只会替换光标所在行,后面的g和sed的差很多,vim里的这个g是global的意思,不加的话只会替换行首。
grep详解
虽然grep我们已经用过很多次了,但是其实我们对它还不是很熟悉,今天就来更深入的了解grep。


下面是演示几个比较常用的。



递归查找还是很有用的。反向查找就是-v而已。

不过上面没有用到正则表达式,下面简单举了几个例子,和sed一样-e可以不要,但是如果是文件的话,-f不能少。

*的问题,*在正则里面和作为通配符的含义是不一样的,那么到底是如何解释的呢?


从上面两张图里可以看到无论有没有-E这个选项,*都不被解释为通配符,因为没有红色,红色才代表匹配到,而.本身作为正则里面的通配符,.是可以匹配单个任意字符,就可以全部匹配到,如果不加-E,|这个应该没有被解释为或,加了-E就可以明显感觉到|被解释为或,当然a|c我们用正则[ac]也可以实现,不过如果字符串的长度不是1呢?像匹配bc或者a呢?这时候正则的(bc)?(a)?也可以实现,不过看下图,还是需要加-E。egrep就相当于grep -E。
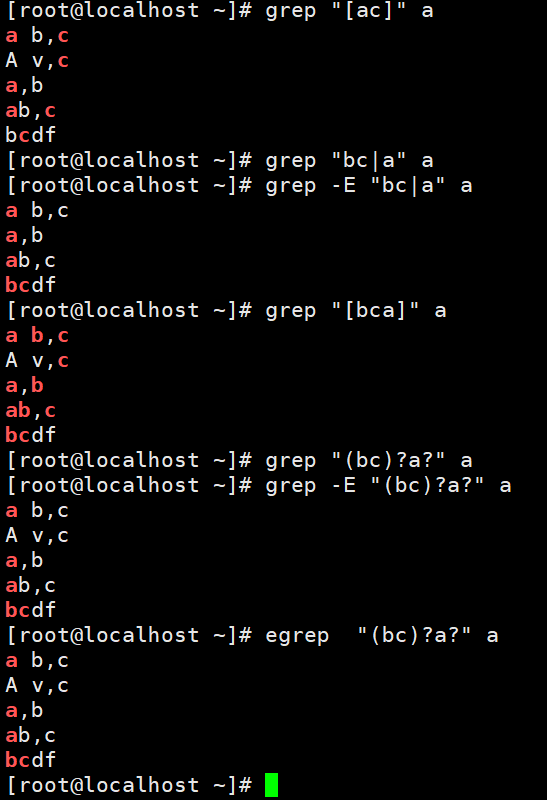
当然其实(bc)?a?也是有问题的,明显可以看出来比-E bc|a多一行,这一行还没有红色,为什么?因为?代表0次或1次,这个是可以有0次的,所以会打印出来没有红色的那一行,那么看来正则搞定-E bc|a还是有点麻烦的。这个-E是扩展的正则表达式,简称为ERE,那么看来还是最好加上这个-E或者直接用egrep。


那么看到确实*在这里面是0次或多次重复的一个作用。"*"一般来说是要报错的。在python里面也确实是如此。

但是我换了一个想法,这个*在bash里可以匹配多个任意字符怎么理解呢,其实可以用正则表达式来理解,既然你在*前面没有指定要重复的字符,那么我就认为是有一个.,换句话说*被解释为.*,也就实现了匹配人任意多个任意字符,那么?也可以这么理解,前面什么都没有,那么就是.?,这就把bash里面的通配符*,?也可以用正则表达式来解释了。
awk
参考了http://www.runoob.com/linux/linux-comm-awk.html


awk我们就直接通过例子来学习。如果不用-F指定分隔符,那么空格或者tab是默认的分隔符投入使用,$n是指的第n列或者称之为第n个字段,n从1开始。以空格开头的,$1不是空的,应该是空格后面的字符串。


结合上面图,awk后面命令必须用大括号括起来,而且外面必须有引号,如果{}里面没有$,可以用双引号,如果有的话,还是用单引号吧,这是因为awk命令里面单引号可以解析$,但是双引号不可以,这和bash正好相反。至于为什么打印了四行1,这是因为源文件有4行,awk应该也是一行一行来处理的。

如果想格式化输出,可以用printf,还是要用大括号和单引号。

试了一下echo,awk是没有识别的,echo不能作为awk后面的脚本命令,有的时候虽然没有报错,但是输出的结果是不对的,或者说根本就没有输出。


结合上下图,FS是一个awk内建变量,它就是来定义分隔符的, awk 'BEGIN{FS=","} {print $1,$2}' a中的BEGIN是不能少的,不然的话,FS这个分隔符没有改变成功,还是会用空格或者tab作为分隔符,而且BGEIN应该是只能跟在内建变量的赋值前面,跟在print前面反而没有输出了,而且赋值和print不能在一对大括号里面。后面会有BEGIN的原理讲解。

不过我这里对文中的 awk -F '[ ,]' '{print $1,$2,$5}' log.txt是先对空格分隔再对,分隔感觉不太对,我感觉应该是空格和,同时作为分隔符分隔,这不就是[]的用法嘛。首先先来看为什么awk '{print}' a|awk -F, '{print $1,$2,$5}' a的结果和 awk -F '[ ,]' '{print $1,$2,$5}' a不一样,因为前一条命令是有两个awk,而前一个用空格分隔再输出,然后再用,分隔,最后字段排序的时候,只会计算,分开的字段,拿上面的a来说

最后第一行的$1就是a b,$2就是c,$5没有,第二行$1是A v,$2是c,$5没有,第三行的$1是a,$2是b,$5没有,第四行的$1是bcdf,$2,$5都没有。而awk -F '[ ,]' '{print $1,$2,$5}' a就是空格和,都作为分隔符,那么第一行的$1就是a,$2就是b,$3是c;第二行的话,$1是A,$2是v,$3是c;第三行的话,$1是a,$2是b,$3没有;第四行的话$1是bcdf,后面的$n都没有。

下图可以看到这个在外面定义的变量在awk里面不起作用的,我们-va=1以后看到打印的两列里面,第二列都是第一列的数字加1,如果第一列不是数字,但是还要相加怎么办,就按照0处理。我们还看到了如果没有-va=1的话,默认都是0,外面的a=2是没用的,并且这种-v的赋值是一次性的。

如果我想打印第1+a列呢?我们需要用小括号括起来。

用BRGIN赋值的效果和-v是一样的,也都是一次性的。

最后只有划红线的两行命令才是成功的,-f一定要在其它选项的后面。


我们观察下图,为什么T大于1呢,因为T的ascii码是84d(d是十进制的意思),而1的ascii码是49d,并且10也是大于2的,说明这个比较是数值的比较。为什么$1==2在和不在大括号里的结果不一样呢,这是因为$1==2不在括号里的时候,awk一行一行执行的时候只有$1==2为真的时候后面大括号里面的命令才会执行,而当$1==2在括号里面,用分号结束时我们看到的结果是打印所有行的$1,$3,这还是因为;没有逻辑判断功能,我想用&&,不过在大括号里面用不了,本来想在双中括号里面用,也不行。

下面一段是参考https://www.cnblogs.com/ginvip/p/6352157.html。


print可以在BEGIN后紧跟的大括号里面,但是不能有$。本来以为()里面用&&可以拯救一下print,但是这种格式是不行的,这个&&和bash里面的不一样,这个里面应该是只能前面都跟逻辑判断式,而bash里面是可以跟命令的,因为命令有返回值,按照0为true,非0为false这样的负逻辑来判断。如: > < 可以作为字符串比较,也可以用作数值比较,关键看操作数如果是字符串就会转换为字符串比较。两个都为数字 才转为数值比较。字符串比较:按照ascii码顺序比较。这一句也就是上面T>2,10>2的解释了,当然我上面已经解释过一遍了。看到正则还是要用//包起来。
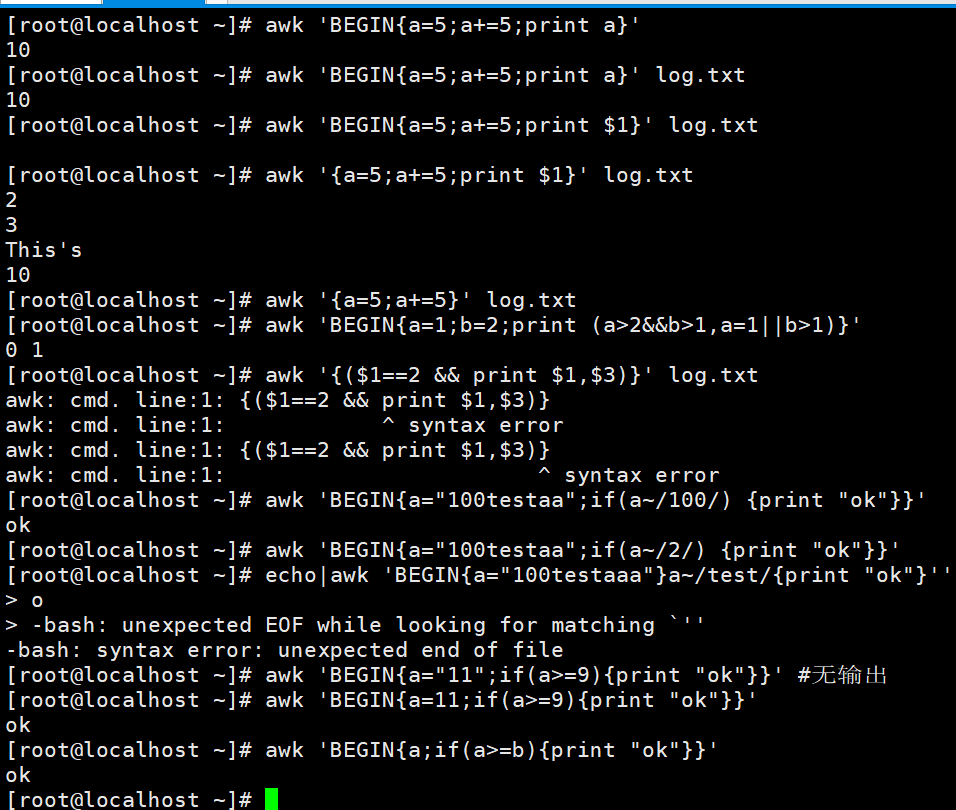
由于例子里a++和++a都没有和赋值号搭配,这里没什么区别,如果和赋值号搭配,还是很有区别的,这个应该是c语言很基础的知识了。看到在执行一些算术运算的时候,直取最前面的数字,遇到非数字就切断了,所以输出是20 22,200 202。
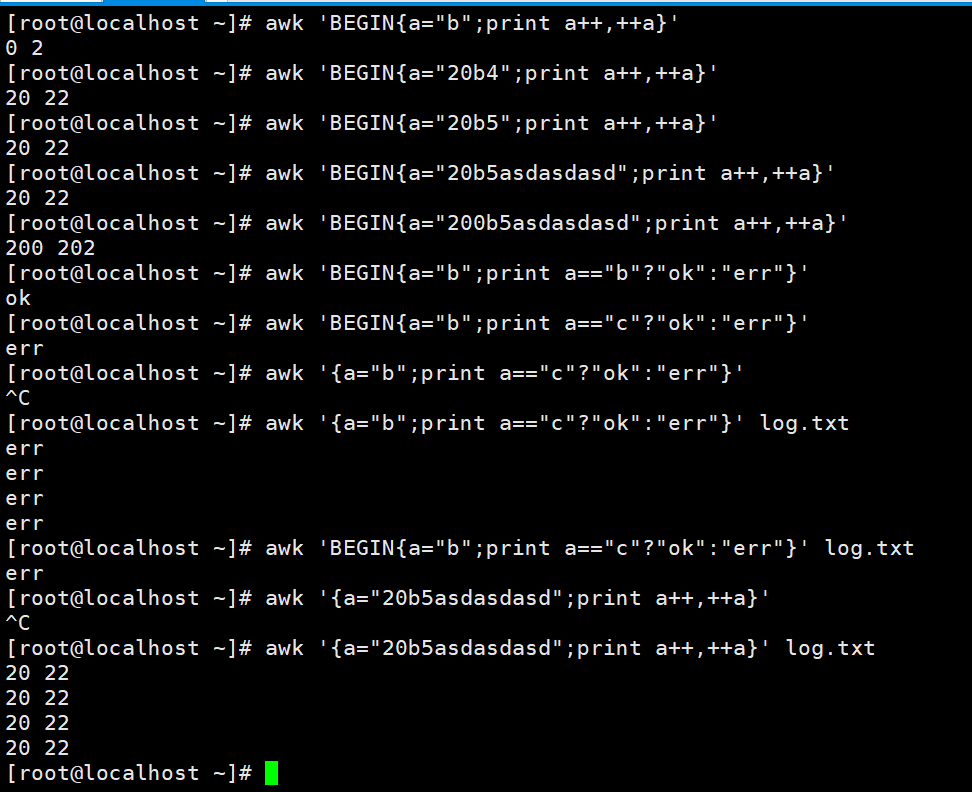
并且我好像有点知道BEGIN的作用了,BEGIN的作用就是可以不要输入,当然如果有输入也没关系,但是如果没有BEGIN,后面必须要跟文件,跟文件的话有几行就执行几次命令;如果不加文件回车,那么输入就是键盘了,你输一行回车一下awk后面的命令执行一次,ctrl+d终止输入。那么当然如果有$1这样的,如果既没有文件输入,又没有键盘输入,是肯定打印不出东西的,**和python里面是一样的意思,都是乘方的意思。

print后面要用双引号,因为大括号外面用的是单引号,如果print后面用了单引号,就打印不出来了,虽然没有报错。



下图发现了BEGIN我的理解不到位,于是去查了一下,参考https://blog.csdn.net/cominglately/article/details/77835917。
awk 对文本的扫描是依行为单位, 这样就产生了一个问题怎么在扫描的开始以及结束之后的执行一些操作? awk BEGIN{} 是在文件开始扫描前进行的操作 END {} 是扫描结束后 进行的操作 ;一般的操作都是需要在BEGIN 设置一个初始的量。那么我们就可以理解为什么当只有BEGIN后面紧跟着的一个大括号的时候,可以不要输入了,因为这个大括号的命令是在awk开始逐行读取之前就执行命令的。那么我们就可以理解为什么下面去掉了BEGIN之后"FILENAME","ARGC","FNR","FS","NF","NR","OFS","ORS","RS";printf "---------------------------------------------\n"打印了这么多次,而没有去掉的时候只在最开始打印一次了。用大括号把语句括起来应该也是遵循了c语言的书写格式。上面关于BEGIN的解释都可以忘掉,知道这个最本质的解释就可以了。



关于OFS,上面那种图片里的解释是错的,下面是对的。


我们还是把OFS="$"写在大括号里面吧,并且要写在print之前,照awk '{print $1,$2,$5}' OFS=" $ " log.txt这种写法不知道什么时候会翻车,之所以要写在print之前是因为要赶在awk对第一行操作之前就要把OFS换了。当然这种写法也是完全没问题的,可以认为是-v ORS=" $ "省略了-v了,把内建变量的赋值用空格和'{}'隔开就好。ORS默认是换行符,现在我们换成了 $ 。




如果不加$n,那么也就是这一行可以匹配到就可以了,忽略大小写就是一开始设置一个IGNORECAE参数不等于0就行了。

模式取反也就是加一个!。




这个脚本文件还是挺简单的。


这个ls -l显示的,应该是第5列是文件大小而不是第六列。第六列是最后修改时间的月份,都是字符串,加起来结果就应该是0。下图参考了https://blog.csdn.net/zhuoya_/article/details/77418413

来分析一下九九乘法表是如何打出来的。


这么一个东西配合后面的awk RS''输出一个九九乘法表呢?那么就必须要理解一下RS了。

怎么来理解这个事情呢?理解为我们重新定义了行(地址记录)和列(字段),我们现在如果不遇到空行,那么行号(记录数)不加1。下面是一个例子,那么按照上面的理解,第一行(第一条记录)就是a1\nb 2\nc 3,第二条记录就是d 4\ne 5\nf 6,又因为我们定义了分隔符是换行符,那么第一行的$1就是a 1,$2就是b 2,$3就是c 3,注意,使用括号引起来的,所以直接打印出来了。第二行我就不分析了,也是一样的道理。

那么如果我把FS="\n"去掉了,也就是文件分隔符是默认的空格。那么虽然每一行都没有变,但是分隔出来的字段变了,第一行$1是a,$2是1,$3为什么是b呢?只能认为系统会把\n也作为默认的分隔符,和空格同时把记录分割为字段,那么第二行(还是说第二条记录好理解一些)也不解释了。

那么如果文件中每一行都只有一个字符的话,FS="\n"就可以加可以不加,因为只有一个字符嘛。

那么再结合下面的图,就可以理解了。






我就拿最后一条记录也就是第九行来说,主要理解这个循环就可以了,{for(i=1;i<=NF;i++)printf("%dx%d=%d%s", i, NR, i*NR, i==NR?"\n":"\t")}'
第九条记录的NF=9,NR是已经读出的记录数,也是9,,那么就是先打印1×9=9,然后判断是否已经打印了NR个,i==NR?"\n":"\t"是个三元运算,如果i==NR,那么前面的%s那里就是/n也就是换下一行了,如果不等于,那么打印一个tab,1显然是不等于9的,于是就接着打印一个制表符,然后打印2×9=18...一直到打印到9×9=81,后面打印一个\n换行,同时awk读取下一行(下一条记录)。

这种用大括号的方式确实和c语言是一样的。这个$0上面其实有见过,就是awk读取的当前行(记录)的意思。看到print里面只有参数用逗号(不能带引号)分开时,才会以默认的空格输出字段分隔符把参数隔开并输出。






感觉这个数组很像python里面的字典,for i in a是对字典里面的键值迭代,awk的数组(叫字典更好)和bash里面用小括号括起来的是不一样的,不能混用。





awk 'BEGIN{info="this is a test2010test!";print index(info,/d/)}'也打印16是因为/d在正则中是匹配数字的意思。
find的正则部分
以前我们是学过find的,但是没有应用到正则表达式里面去,其实只需要一个-regex选项即可,后面跟正则表达式的模式即可,但是帮助里面提示了,这匹配的是全路径而不是搜索什么意思呢?有一个例子,比如要匹配一个文件是./fubar3,你可以使用.*bar或者.*b.*3但是不能使用f.*r3这是因为最后一个给出的不是全路径,默认的都是Emacs Regular Expressions,简称ERE这种规范,但是我们可以用-regextype来改。

-iregex和-regex相比就是不区分大小写了而已。其它还有posix-awk,posix-basic等正则表达式的规范,我们一般还是用ERE,回想上面的grep我们最后还是得加一个-E或者用egrep,它们用的都是ERE。


这一讲先到这里了。