8.1外部存储上的数据
- 磁盘是最重要的外存设备。它允许以固定的代价来检索每一页。但是如果我们按照页面存储的物理顺序来访问磁盘,要比随机访问快的多。
- 文件中的每一个记录都有一个唯一的标识符,称为记录id,简称rid,一个rid有一个属性,可以用它来识别包含该记录的页在磁盘上的地址。
8.2文件组织与索引
- 最简单的无序文件是无序文件,或称堆文件。一个堆文件中的数据在文件页中以任意的顺序排列。
- 数据项:存储在索引文件中的记录。键值为K,的数据项记为K*。
- 把那些信息作为索引的数据项存储呢?
- 数据项K*是一个正真的数据记录。
- 数据项是一个
<k,rid>对,其中rid是搜索键值为K的数据记录的记录id。 - 数据项是一个
<k,rid-list>对,其中rid-list是搜索键值为K,的数据记录的记录id列表。
8.2.1聚簇索引
- 数据记录的顺序与某一索引的数据项顺序相同或类似,我们就称这类索引是聚簇索引。否则就是非聚簇索引。
- 上述第一种方式的索引,是聚簇的。第二和第三种,只有当数据记录按照搜索码排序时才是聚簇的。
- 聚簇索引的查询代价较低。
8.2.2主索引和次索引
- 建立在包含主码的字段上的索引称为主索引,其他的索引称为次索引。
- 如果两个数据项有相同的索引搜索码,那么他们就称为重复。一般来说主索引不含有重复。
8.3索引数据结构
- 组织数据项的方法之一是按照搜索码对数据项进行哈希。
8.3.1基于哈希的索引
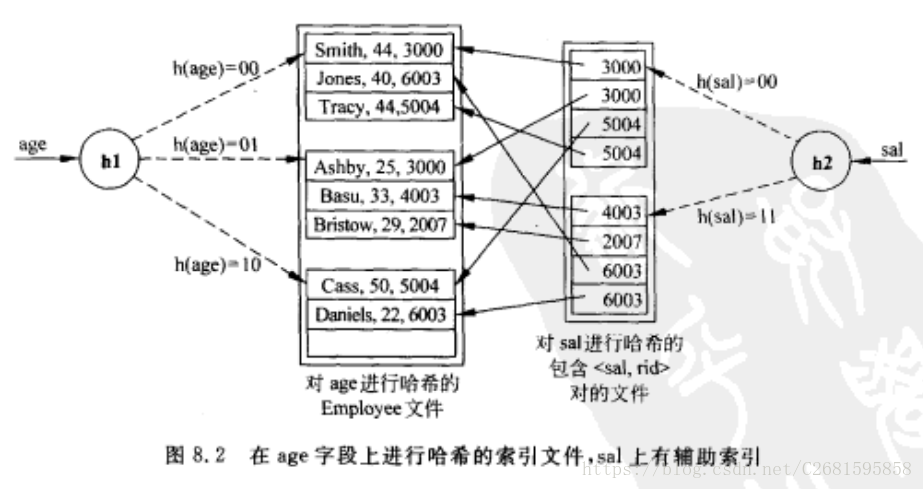
这个索引分别使用了8.2节介绍的第一种和第二种索引方式。
第二种方法的数据项为
8.3.2基于树的索引
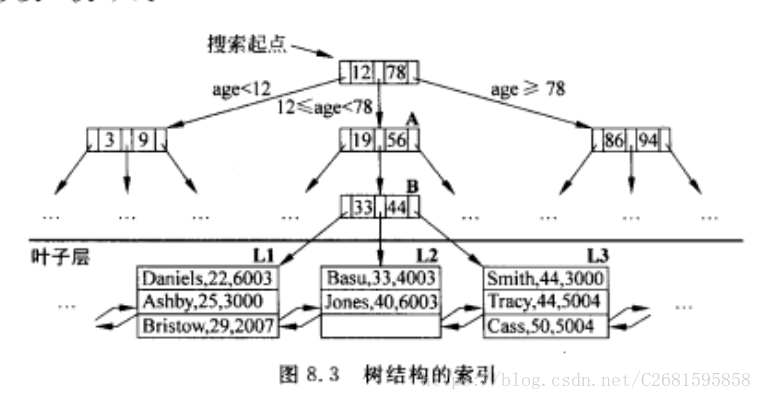
数据项按照搜索码值进行排列,并且维护一个层次化的搜索数据结构,以便将搜索定向到数据项所属的页面。上图中的每一个节点是一个物理页,每检索一个节点就涉及一次I/O。
- 树的最下层也就是叶子层包含数据项,且所有的叶子页被维护在一个双向链表中。
- 在搜索中出现的磁盘I/O数等于,从根节点到叶节点的路径加上满足条件的叶子页的个数。
- 上图中树的高度为3,而访问一个叶子页的I/O次数为4(其实一般根节点在缓冲池中,所以I/O次数为3)。
- 非叶子节点的平均孩子数称为称为树的扇出。如果每一个非叶节点有n个孩子,那么高度为h的树有 个叶子页。
8.4不同文件组织的比较
8.4.1代价模型
用B来表示当页中无浪费空间时数据页的数量,用R来表示每一页的记录数。读或写一个磁盘页的平均时间是D,处理一个记录的平均时间是C。将哈希函数应用于一个记录所需要的时间是H。对于树索引用F表示扇出。
I/O通常是数据库操作代价的主要部分。
用读出或写入磁盘的页数来衡量I/O。
8.4.2堆文件
- 扫描:其代价为B(D+RC)。总共需要检索B页,每页需要花费D时间来读取,而且每页的R个记录需要花费C时间来处理。
- 等值选择型的搜索:
- 如果选择条件指定在候选码上。一般来说,如果该记录存在,并且搜索字段的值均匀分布,必须扫描文件的一半来找到这个记录。对于每一个检索的页,必须查看他的每一项,一查看他是否为需要的记录。因此代价为0.5B(D+RC)。但是如果不存在所搜索的记录,就必须扫描整个文件来证实其不存在。
- 如果选择条件不是指定在候选码上的,那么需要扫描整个文件,因为所要搜索的记录可能分布在文件中的任何位置。
- 范围选择型搜索:整个文件都需要扫描。因为是无序的,就不能确定他们在什么地方。所以其代价是B(D+RC)。
- 插入:假设记录总是插入在文件的末尾,必须取出文件的最后一页,加入记录,然后将该页写回。其代价为2D+C。
- 删除:首先必须找到这个记录,在从页中删除这个记录,然后再将页写回。
8.4.3排序文件
- 扫描:其代价为B(D+RC)。
等值选择型搜索:假定等值选择和排列顺序
<age, sal>相匹配。或者说选择条件指定在至少是复合码的字段上。否则文件的排序对我们没有什么帮助,其访问代价和堆文件相同。- 如果存在满足条件的记录 ,用二分法查找,可以在 步之内找出包含所要数据的第一页。每一步都需要一次磁盘I/O和两次比较。一旦找到所要的页, 第一个满足条件的记录也可以用二分法找到,代价为 ,所以总代价为 .
范围选择型搜索:假定范围搜索和复合码相匹配,那么范围搜索就是多个等值搜索。第一步和等值搜索一样,定位所在的页,然后在页内找出所有满足范围选择条件的数据记录。其代价为搜索代价加上检索满足搜索条件的记录集的代价。
- 插入:如同数组的插入,在找到插入的槽,插入数据后,所有之后的数据都要向后移动一个槽的位置。 .
- 删除:首先必须找到这个记录,然后将将记录删除,并将修改后的页写回。和插入一样还需要修改被删除位置之后的页。所以其代价和插入相同。
8.4.4聚簇文件
大量文件显示,在聚簇文件中其页的占满率通常为67%,因此物理数据页大致为1.5B。
- 扫描:其代价为1.5B(D+RC)。
- 等值选择型搜索:假设等值选择与搜索码
<age, sal>相匹配。如果存在满足条件的记录的话可以在 步内找到包含所要记录的页,即从根节点到恰到的叶节点的检索。一旦找到了那一页就可以用二分法查找满足条件的记录。所以其代价为 ,这与排序文件相比,在性能上有所提高。 - 范围选择型搜索:这类似于很多条件的等值选择。
- 插入:要插入一个数据记录,首先找到叶子页,然后在页内找到插入位置,直接插入。然后将型的页面写回。所以总代价为 。
- 删除:与插入的代价相同。
8.4.5具有非聚簇树索引的堆文件
索引中叶子页的个数依赖于数据项的大小。假设索引中的每一个项的大小是一个雇员数据记录大小的1/10。叶子页的空间占用率为67%。那么索引中叶子页的个数为0.1(1.5B)。也就是0.15B。
同理一页中数据项的数量为10(0.67R)。
- 扫描:取出所有数据项的代价是0.15B(D+6.7RC)。根据数据项取出所有数据记录的代价是BR(D+C)。
- 等值选择型搜索:假设等值选择与排列序列相匹配,如果存在满足条件的项,就可以在
步之内定位到所要数据项的页,即取出所有从根到叶子的页。一旦找到这个页,那么在页内就可以用二分法的方式找到满足条件的数据项,其代价为
,第一个满足条件的数据记录就可以用一次I/O从雇员文件中取出。其代价为
。
- 范围选择型搜索:类似于多个条件的等值选择型搜索。
- 插入:首先要以2D+C的代价,将记录插入到堆文件中,然后将相应的数据项插入到索引中。找到正确的叶子页,
,添加新的数据项后写回到叶子页加上代价D.
- 删除:找到家写回,总共
。
8.4.6具有非聚簇哈希索引的堆文件
页面占有率为80%, 所以总页数为1.25(0.1B) = 0.125B。每页中的数据项数目为10*0.8R = 8R。
- 扫描:数据项检索代价:0.125B(D+RC)。然而对于每一项都要花费一次I/O来取出数据记录。所以,其代价为BR(D+C)。
- 等值选择型搜索:找到数据项所在页的代价为H。假设这个桶只包含一页那么检索它的代价为D.扫描这个页的代价为0.5(8R)C = 4RC。从雇员文件中取出记录需要花费代价D。所以总的代价为H+2D+4RC。
- 范围选择型搜索:哈希对此没有什么优势,需要进行全文件扫描。
- 插入:首先将数据写到文件中,代价为2D+C。然后将索引加上去,代价为H+2D+C。
- 删除:搜索代价H+2D+4RC,更新数据单元代价2D。
8.4.7I/O代价的比较
就是对上面的一些总结:

8.5索引和性能调整
8.5.1工作负载的影响
树结构的索引相对于排序文件的优势:
(1)可以有效的处理数据项的插入和删除
(2)通过搜索码的值来找叶子页的时候速度比较快。