版权声明:转载请注明博客地址谢谢。 https://blog.csdn.net/buppt/article/details/82227030
本文是对bilstm+crf模型中的crf进行讲解,并不是完整的条件随机场的讲解。
如果对命名实体识别还不清楚的同学,可以先看这篇文章。代码在这里。
模型如下图所示。
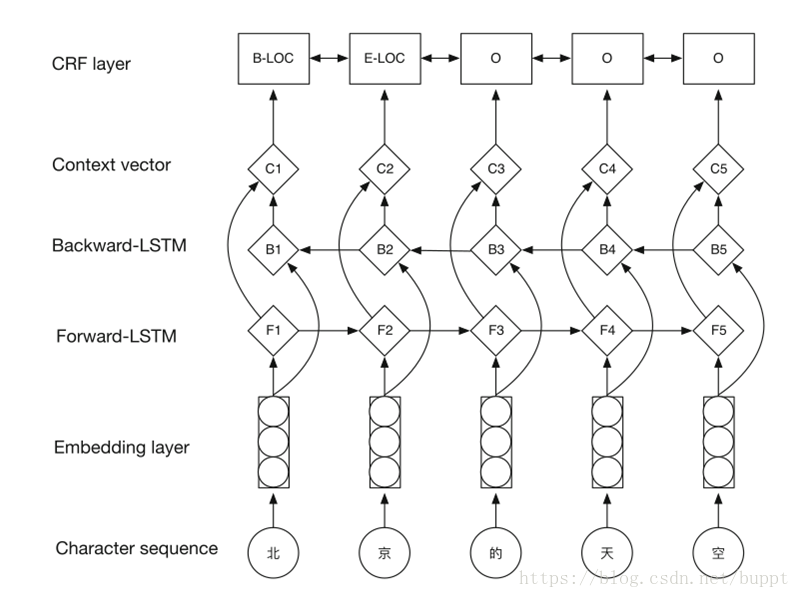
我们已知lstm的输出就是每个字标注的概率。假设lstm输出概率如下所示。这里为了方便,只写了 BMEO 4种标注结果。更多的话也是相同的。
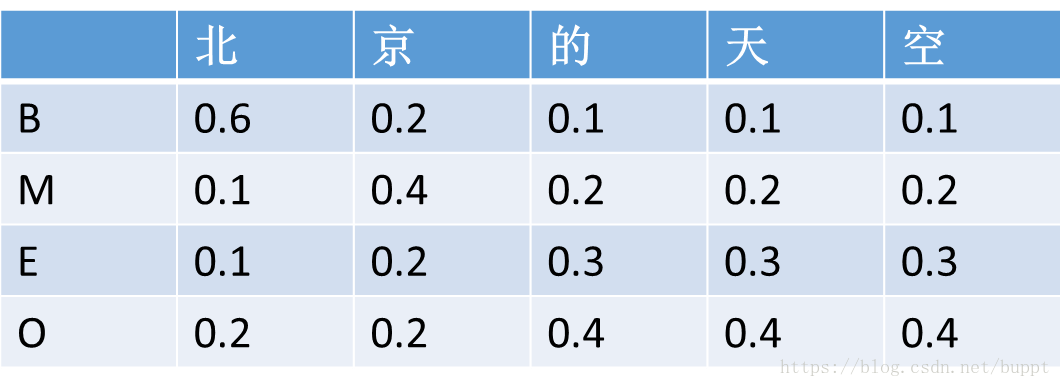
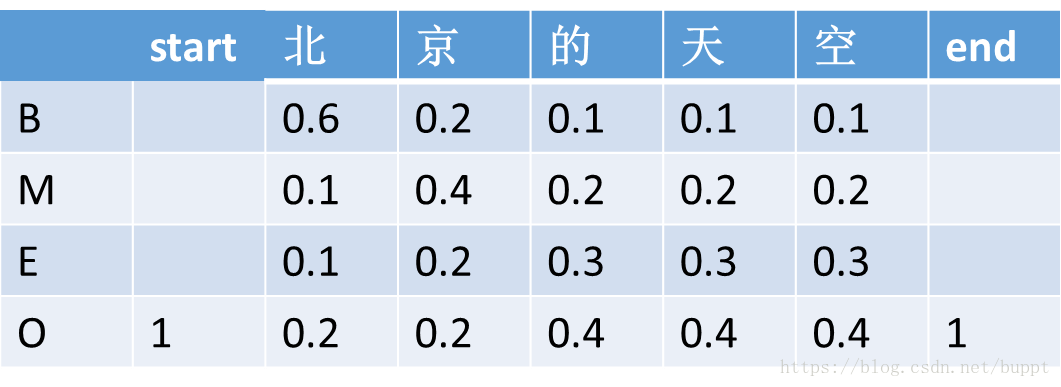
而crf首先在每句话的前面增加一个<start>字,在每句话的结尾增加一个<end>字。
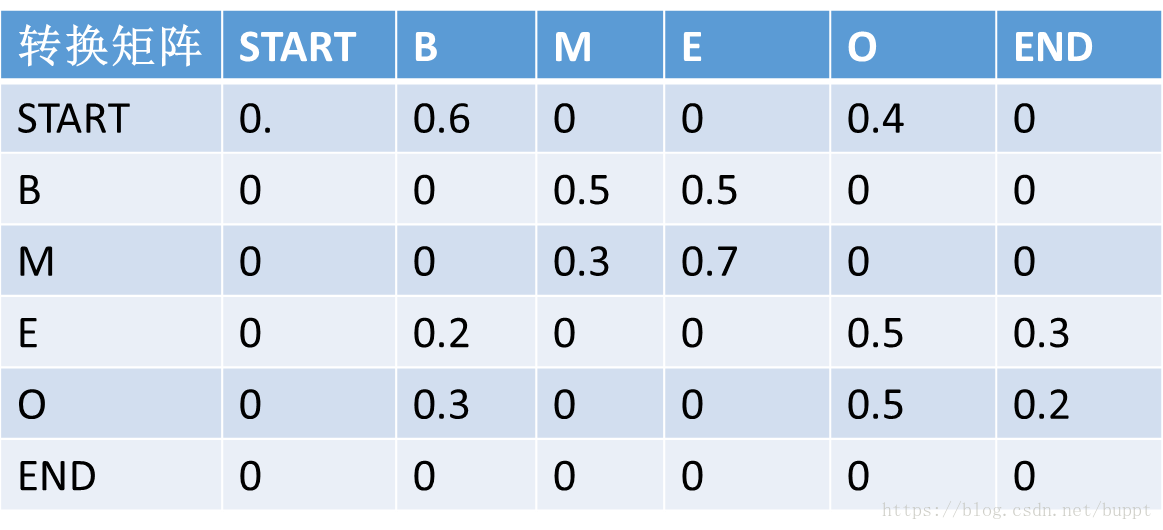
然后定义了一个转移矩阵,转移矩阵中的数值代表前面一个字标注结果到下一个字的标注结果的概率。比如下面矩阵中的第一行,代表的含义就是前一个字标注为start,下一个字标注为B 的概率是0.6,标注为O的概率就是0.4。这个矩阵是随机初始化的,里面的数值也是通过梯度下降自动更新的。
然后又定义了“路径”这个概念,一句话的每一种标注结果就代表一个路径。下图就代表两条路径。

每条路径的分数 P=e^s
s = 初试分数 + 转换分数
初试分数 = 路径上lstm输出分数和
转换分数 = 路径上转换矩阵分数和
我们要找的就是分数最大的那一条路径,就可以得到这句话每个字的标注结果,然后就可以通过BME规则把实体抽取出来了。我们定义crf的损失函数如下。
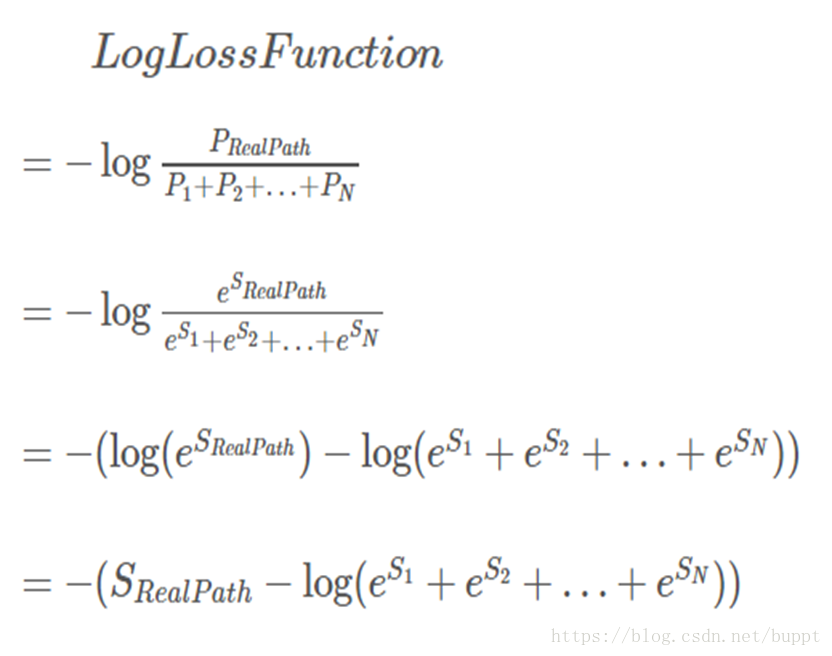
然后就可以通过pytorch提供的
loss.backward()
optimizer.step()进行训练了。
这里有一个写代码时候的算法优化,因为要计算所有路径的分数,一个一个算时间复杂度太高了,计算时候一个字一个字的计算,计算下一个字的时候,只用前一个字的分数就行了。
