压缩算法——lzw算法实现
字典压缩的基本原理
以色列人Lempel与Ziv发现在正文流中词汇和短语很可能会重复出现。当出现一个重复时,重复的序列可以用一个短的编码来代替。
压缩程序重复扫描这样的重复,同时生成编码来代替重复序列。随着时间过去,编码可以用来捕获新的序列。算法必须设计成压缩程序能够在编码和原始数据序列推导出当前的映射。
说实话直接用文字来描述其实听起来很迷,直接看图:
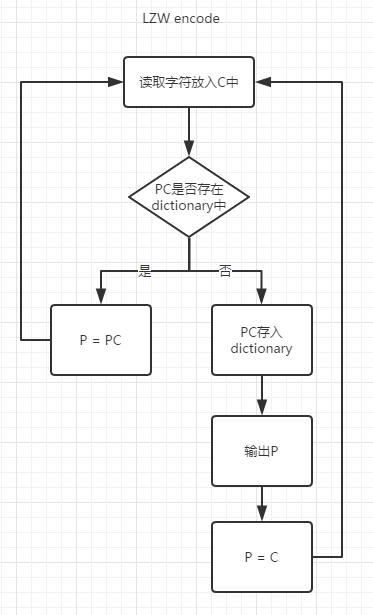
然后我们以字符串abcbcabcabcd为例,来模拟这个过程
首先我们先建立初始码表a= 1,b=2,c=3,d=4
| step | P | C | is PC in dic | output P | dictionary | description |
|---|---|---|---|---|---|---|
| 1 | NULL | a | 初始化,不处理 | |||
| 2 | a | b | no | 1 | ab:5 | ab不存在dictionary中,扩充 |
| 3 | b | c | no | 2 | bc:6 | |
| 4 | c | b | no | 3 | cb:7 | |
| 5 | b | c | yes | bc在dictionary中,P = PC | ||
| 6 | bc | a | no | 6 | bca:8 | |
| 7 | a | b | yes | |||
| 8 | ab | c | no | 5 | abc:9 | |
| 9 | c | a | no | 3 | ca:10 | |
| 10 | a | b | yes | |||
| 11 | ab | c | yes | |||
| 12 | abc | d | no | 9 | ||
| 13 | d | NULL | 4 | 结束 |
其实就是每次读入一个字符,如果发现和前缀加起来在字典中不存在,那么就建立码表,并输出前缀的值,如果存在就将前缀和后缀一起赋给前缀,继续读取下一个字符给后缀,如此往复。直到读取完整个字符串
直接贴上代码供参考:
public List<Integer> encode(String data) {
List<Integer> result = new ArrayList<Integer>();
// 初始化Dictionary
int idleCode = 256;
HashMap<String, Integer> dic = new HashMap<String, Integer>();
for (int i = 0; i < 256; i++) {
dic.put((char) i + "", i);
}
String prefix = "";// 词组前缀
String suffix = "";// 词组后缀
for (char c : data.toCharArray()) {
suffix = prefix + c;
if (dic.containsKey(suffix)) {
prefix = suffix;
} else {
dic.put(suffix, idleCode++);
result.add(dic.get(prefix));
// System.out.println(dic.get(prefix));
prefix = "" + c;
}
}
// 最后一次输出
if (!prefix.equals("")) {
result.add(dic.get(prefix));
// System.out.println(dic.get(prefix));
}
return result;
}上面我们完成了对字符串的压缩,下面我们对结果进行解压
扫描二维码关注公众号,回复:
3320719 查看本文章

解压的基本思路也是知道一个基本的码表,然后一边读取一边解码,然后扩充码表
直接解释很费力,直接上图:
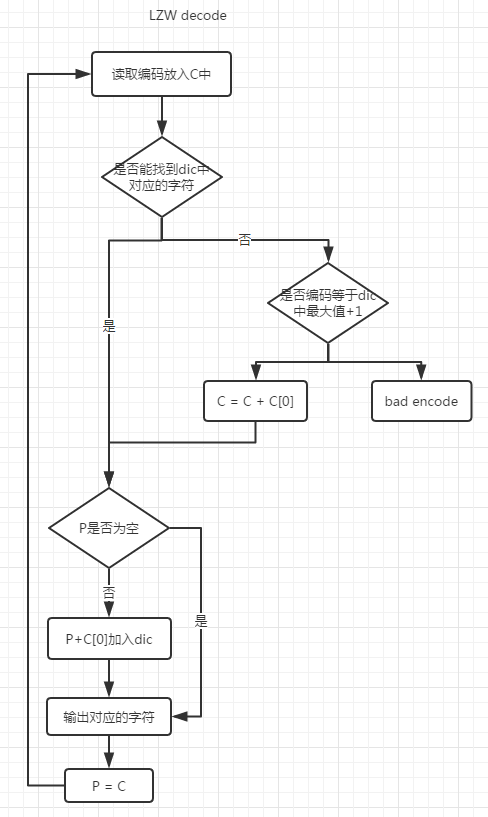
这里就不进行分析了,直接贴上代码供参考
public String decode(List<Integer> array) {
StringBuilder result = new StringBuilder();
int deCode = 256;
HashMap<Integer, String> dic = new HashMap<Integer, String>();
for (int i = 0; i < 256; i++) {
dic.put(i, (char) i + "");
}
String p = "";
String c = "";
for (int code : array) {
if (dic.containsKey(code)) {
c = dic.get(code);
} else if (code == deCode) {
c = c + c.charAt(0);
System.out.println("code == deCode");
} else {
System.out.println("bad Code!");
}
if (!p.equals("")) {
dic.put(deCode++, p + c.charAt(0));
}
result.append(c);
this.write("lzw解压.txt", c);
p = c;
}
System.out.println("++++");
// System.out.println(result);
return result.toString();
}上面我们只是实现了对字符串的压缩和解压,如果想利用这个原理实现对文件的压缩,还需要加入对得到的数组队列的存储以及读写的方法
建议使用DataOutputStream.writeInt同时使用readInt方法对压缩文件进行读取