上一讲介绍了一个简单的示例程序, 并且我们提到了汇编写代码的一个优点: 你可以在硬件这上的, 任何软件抽象层次去实现功能. 上一节我们输出CPU厂商信息, 使用
sys_write系统调用输出内容, 这一节, 我们简单的介绍一一上, 在上一讲的基础上, 如何调用libc中的printf函数来输出内容.
1. 系统调用
我这样的咸鱼程序员(非科班出身, 基础不扎实, 自学成材的半路出家的咸鱼), 由于缺乏对计算机科学很多基础知识的学习与认知, 所以有很长一段时间, 我很难深刻理解库, 函数, 系统调用, 软硬中断等基础概念. 甚至在自觉成材的过程中, 编译链接这两个基础过程, 都困扰了我很长时间. 我相信有不少同学至今还和我一样, 对一些基础知识的掌握很不到位.
系统调用其实也是函数, 可以简单的理解为C函数, 但是这种函数的调用有点特殊:
- 你不能通过简单的引用头文件, 链接库的方式调用这些特殊的函数, 而是需要像上一节示例程序展示的那样, 调用一个特殊的指令, 进行一次软中断, 在Linux中, 这个中断号即是
$0x80 - 这些函数, 也就是系统调用, 涉及的功能方面一般有: 设备管理, 文件管理, 进程控制, 进程通信, 内存管理等. 可以看出, 对于一个运行中的"系统"来说, 这些操作都是高度敏感的. 所以操作系统将这些操作的具体实现, 封装成了系统调用. 而使用系统的用户(在这个场景下, 所谓的用户其实就是在操作系统上编程的程序员), 要进行设备操作, 文件操作, 进程操作, 内存操作等, 就不能直接接触硬件驱动程序, 而必须通过操作系统提供的系统调用去实现.
- 或许机智的你想, 系统调用的实现, 具体到cpu上也是指令而已, 那么我能不能写一段相同的指令, 直接去指挥硬件, 操作文件, 操作内存呢? 答案肯定是否定的, 你可以写出相同的指令, 进行编译链接, 搞成可执行文件. 但在具体运行时, cpu会拒绝运行这些指令: 因为你权限不够!! 即, 系统调用是运行在所谓的"核心态"的, 而一般的, 不涉及敏感操作的函数, 是运行在"用户态"的. 核心态中的很多操作, 即CPU指令, 运行时需要切换cpu权限状态. 这就限死了, 普通用户要执行敏感操作, 只能通过系统调用去实现
- 需要谨记的是, 在你操作系统上运行的程序, 是要受操作系统代码监管的. 操作系统的监管, 最简单直接的方面, 分为两部分:
- 操作系统在正常情况下, 将cpu设置为权限较低的权限状态. 这保证了你的程序如果试图执行一些敏感操作, cpu将直接拒绝, 你只能向操作系统写申请, 由操作系统去执行这些敏感操作. 再将执行结果反馈给你. 显然, 也只能操作系统的代码能更改cpu的权限状态.
- 通过执行敏感操作, 比如内存分配, 如果你向操作系统提交的申请很过分, 操作系统会拒绝执行.
- cpu提供的
int指令, 即是软中断指令, 其实是一个信号传递机制. 或者说简单一点, 是一个回调函数机制: 操作系统内核代码事先写一张回调函数表(软中断向量表). 这张表其实就类似于告诉cpu:"听着, 当四号中断发生的时候, 你就跳到这一段写显存的指令中去执行, 执行完了再回到原地". 用户态的普通程序只能用int指令去触发中断, 类似于激发事件. cpu响应软中断, 查表执行对应的内核函数. 在执行时, 显然这些内核函数的第一件事就是: 切换cpu权限状态. 函数执行结束前夕, 会重新将cpu权限状态恢复为较低的状态. - 系统调用的执行过程, 和普通函数调用, 最大的不同是:
- 普通函数的执行, 是在进程空间就地压函数栈(用户态进程栈), 执行结束后退栈. 调用前将现场信息(寄存器值等)压在栈里, 调用结束后再从栈中读取这些信息, 重新恢复现场.
- 而系统调用的执行, 也有一个压栈, 调用结束退栈恢复现场的过程. 但是! 这个栈, 每个进程一般只有4k, 刚好是一页大小. 这就是所谓的"内核栈". 这和用户态函数调用的"进程栈", 不是一个东西.
上面列出的几点中, 有错误, 但不影响你(一个普通程序员)对程序执行流程的理解. 有兴趣深挖的话, 去读Linux内核相关的书, 探究一下.(我天分不够, 读不懂)
所以, 我们执行系统调用时, 是在汇编代码里发出一个int $0x80信号, 而操作系统内核代码受软中断向量表回调唤醒后, 如何在内核栈中保存现场, 系统调用执行结束后如何回传执行结果, 以及如何退内核栈, 返回用户态. 这些我们都可以不用关心.
但是! 如果我们要调用的是一个普通的函数, 调用过程中如何压栈, 保存现场, 调用结束后如果获取执行结果, 退栈恢复现场, 就得我们自己动手了.
那么, 如果我们调用的是printf函数呢? 这里不要乱, 不要觉得, 啊, printf函数内部也肯定调用的是sys_write系统调用, 所以怎么怎么怎么样. 脑子不要乱. 无论printf内部是怎么折腾的, 都和我们调用者无关, 对于我们来说, 这就是一个C函数, 所以我们要做的事情很简单:
- 传递参数, 压栈, 保存现场, 然后跳转至printf中去.
- 当执行流程从
printf返回回来后, 退栈, 恢复cpu现场即可
至于printf内部, 是如何调用sys_write系统调用的, 和我们卵关系都没有
2. 在汇编中调用printf函数
下面是示例代码, 功能和上一讲的cpuid程序完全一样, 不同的是, 这次调用的是printf函数来输出内容, 而不是sys_write系统调用:
.section .data
output:
.asciz "The processor Vendor ID is '%s'\n"
.section .bss
.lcomm buffer 12
.section .text
.globl _start
_start:
# 调用cpuid获取厂商信息
movl $0, %eax
cpuid
# 把厂商信息的12个字符, 放在buffer中
movl $buffer, %edi # 把buffer的首地址放在edi寄存器中
movl %ebx, (%edi) # 把ebx中的内容放入edi寄存器所指向的内存中去, 其实就是buffer
movl %edx, 4(%edi) # 同上, 只不过向后偏移了四字节
movl %ecx, 8(%edi) # 同上, 只不过向后偏移了八字节
# 压栈, 其实就是压 printf(output, buffer) 调用中的两个参数
pushl $buffer
pushl $output
# 调用printf
call printf
# 退栈, 让指令指针+8即是退栈.
addl $8, %esp
# 压栈, 其实就是压 exit(0) 调用中的唯一一个参数
pushl $0
call exit从上面的代码中看, 保存现场与恢复现场中, 有很多细节隐藏在call这条语句中了, 后续会对它进行细节解释, 目前不必要过分纠结细节, 主要是理解了函数调用的过程就好了.
这个代码的编译后的链接需要注意一下, 首先, 它使用了libc中的函数, 因此链接时需要加上-lc选项. 其次, libc的默认链接方式是动态链接, 除了在链接时要指明"动态链接哪个库(也就是libc)"外, 还需要指定"由谁来负责动态链接". 所以需要加上-dynamic-linker /lib/ld-linux.so.2参数. 在Linux操作系统下, 动态链接程序都是由这个动态链接器负责执行动态链接的.
所以, 最终的链接命令可能有一点复杂, 但总之就是多了两个地方:
- 要额外声明, 程序的运行需要动态库
libc. 链接时对于libc库是动态链接, 故加-lc即可 - 要指明动态链接器, 即
-dynamic-linker /lib/ld-linux.so.2
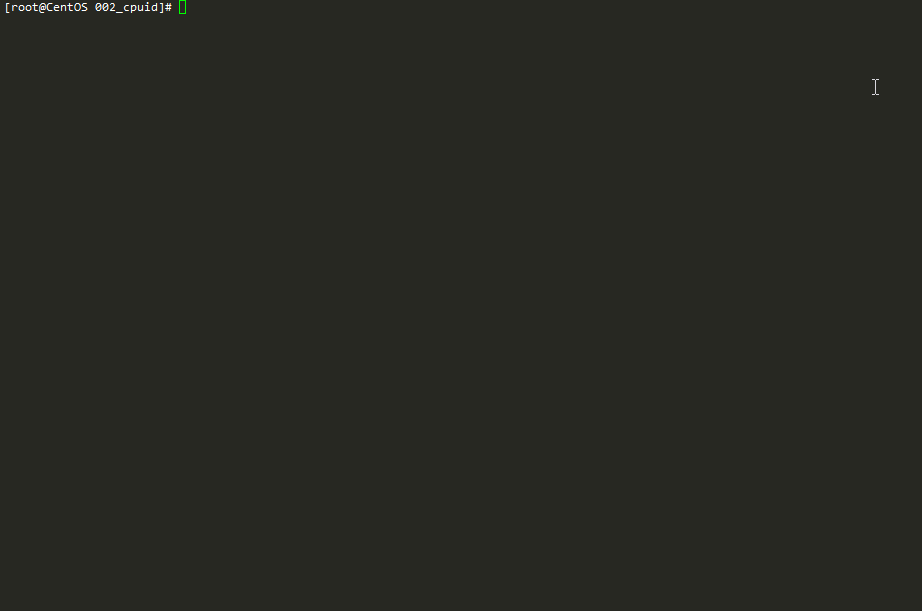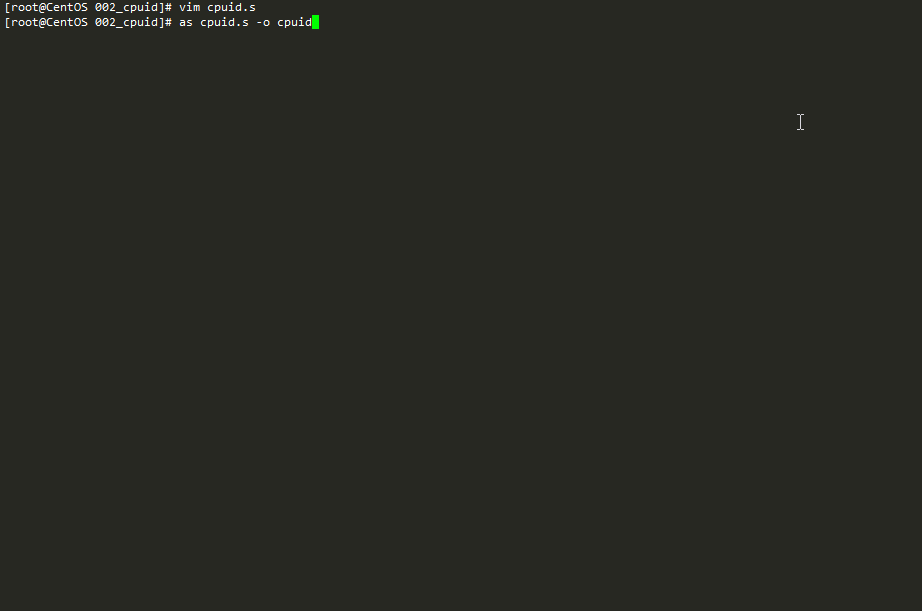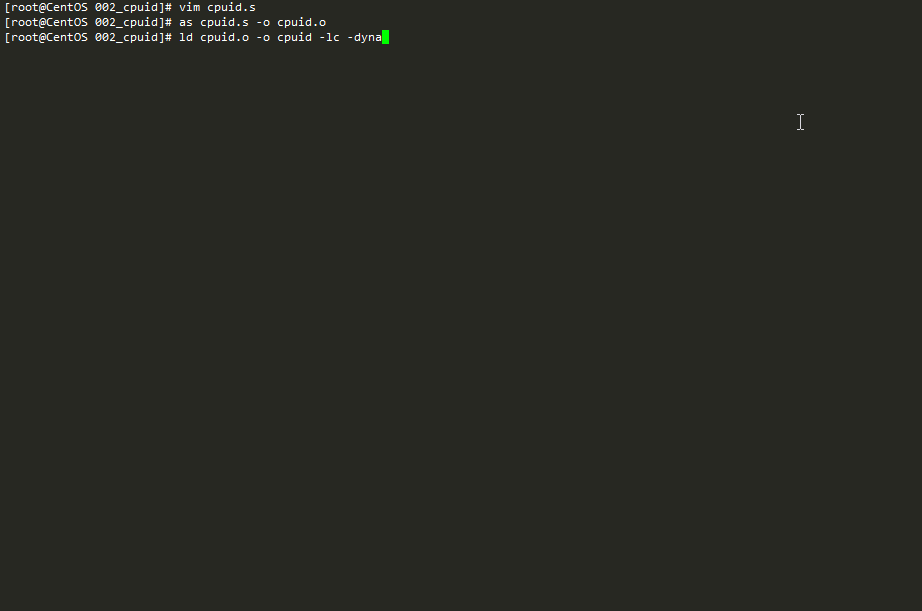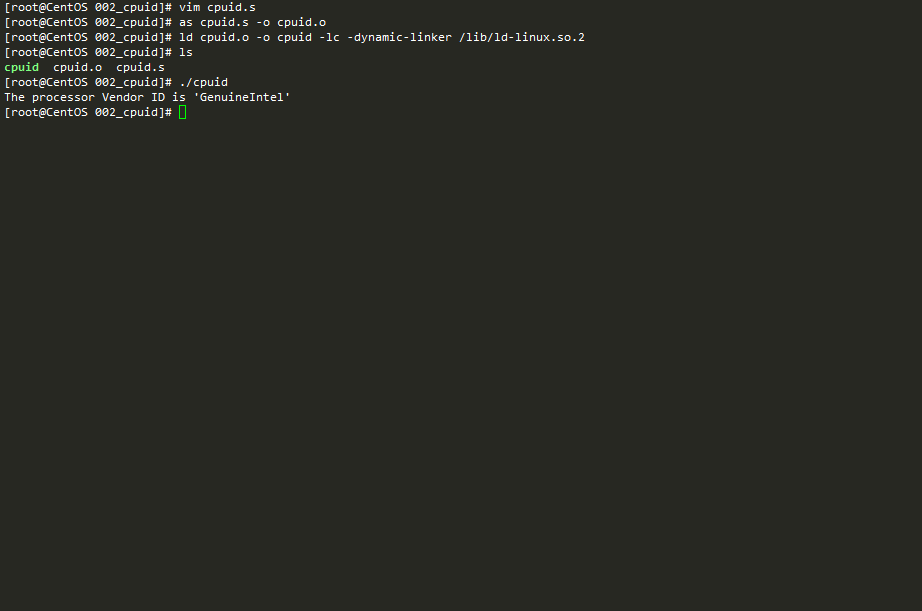
编译, 链接, 运行如下gif图所示: