一、虚拟机中Linux的安装
hadoop-0.20.2.tar.gz只能在Linux中安装。
Hadoop相当于一个服务器,类似于Apache服务器的角色。我们可以在Linux上运行hadoop0.20.2。
二、Java的安装
Hadoop是基于Java开发的,,在Linux配置好Java环境。
https://blog.csdn.net/weixin_38883338/article/details/82079194
三、SSH的安装、配置
在Linux中安装SSH免登录认证,用于避免使用Hadoop时的权限问题。
SSH的安装命令:
sudo apt-get install ssh

为ssh生成一个密匙:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
密匙生成完毕,如下图所示:

为密匙授权:
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
这一步成功之后是没有任何提示信息的。
查看ssh是否安装成功:
ssh localhost
ssh成功安装会显示如下的信息:

至此,Hadoop的前置环境安装完毕。
四、Hadoop0.20.2的安装
1、将下载的hadoop-0.20.2.tar.gz解压。
sudo tar -C /home/huyn -xzf hadoop-0.20.2.tar.gz
2、先对里面的conf目录的部分文件进行修改:
(1)首先是hadoop-env.sh文件的修改:
在终端利用如下的命令:
$:$JAVA_HOME

sudo vim '/home/huyn/hadoop-0.20.2/conf/hadoop-env.sh'

(2)core-site.xml、hdfs-site.xml、mapred-site.xml
修改的xml文件是如下的样式,在configuration中留下空白填写:

sudo vim '/home/huyn/hadoop-0.20.2/conf/core-site.xml'
首先是core-site.xml,修改成如下的代码:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/pc/hadoop-0.20.2/tmp/hadoop-${user.name}</value>
</property>
</configuration>
上述的代码,文件夹hadoop后接一个当前用户的用户名。用于标识不同用户的临时文件。届时,编译成功之后,tmp目录下就会产生不同的文件夹。如我当前的Linux的用户名是pc,则产生如下的文件夹:

sudo vim '/home/huyn/hadoop-0.20.2/conf/hdfs-site.xml'
之后是hdfs-site.xml,标识单机模式:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
最后mapred-site.xml:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
</configuration>
3、格式化Hadoop
修改vim /etc/profile文件
sudo vim /etc/profile
export HADOOP_HOME=/home/huyn/hadoop-0.20.2
export PATH=$HADOOP_HOME/bin:$PATH
然后source /etc/profile
在终端中,通过命令进入Hadoop下的bin文件夹:
cd /home/huyn/hadoop-0.20.2/bin
以-format参数运行hadoop下的namenode类:
sudo ./hadoop namenode -format
运行成功如下图所示:
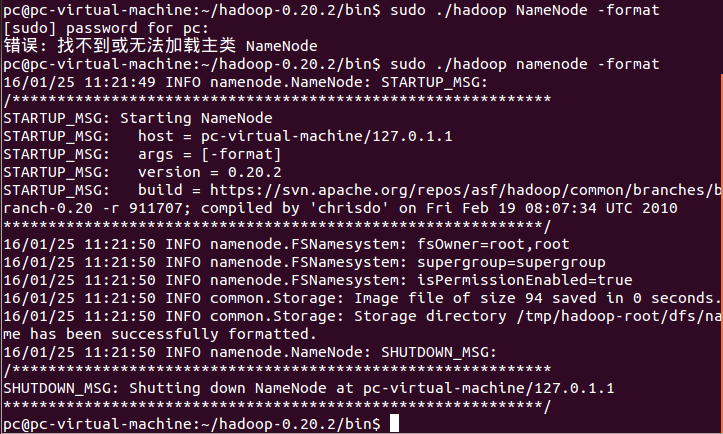
这里,有些资料非常坑爹,如果你在Hadoop0.20.2格式化这一步,出现如上图的“错误:找不到或无法加载主类 NameNode”那么完全就不是什么问题,就是这些资料将这个NameNode的大小写写错了,用vi或者gedit来看Hadoop这个可执行文件,你会发现里面根本没有NameNode,就只有namenode,核心问题是系统区分大小写的,自然找不到这个类了!至少在Hadoop0.20.2中就有namenode这个东东,也正是这个东东。
4、打开Hadoop
这是大功告成的一步了,最后同在这个bin目录下,通过如下的命令打开Hadoop服务器
./start-all.sh
执行成功如下图所示,提示已经成功开始namenode、datanode、secondarynamenode、jobtracker、tasktracker,同时这些文件写入的Hadoop0.20.2的log文件夹中
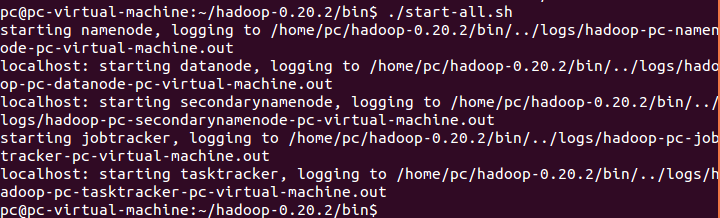
此后,在Hadoop的运行过程中,无论出错与否还是什么的,都不会将内容打印都控制台,而是直接输出的log文件夹各个文件夹中,具体如下图所示:
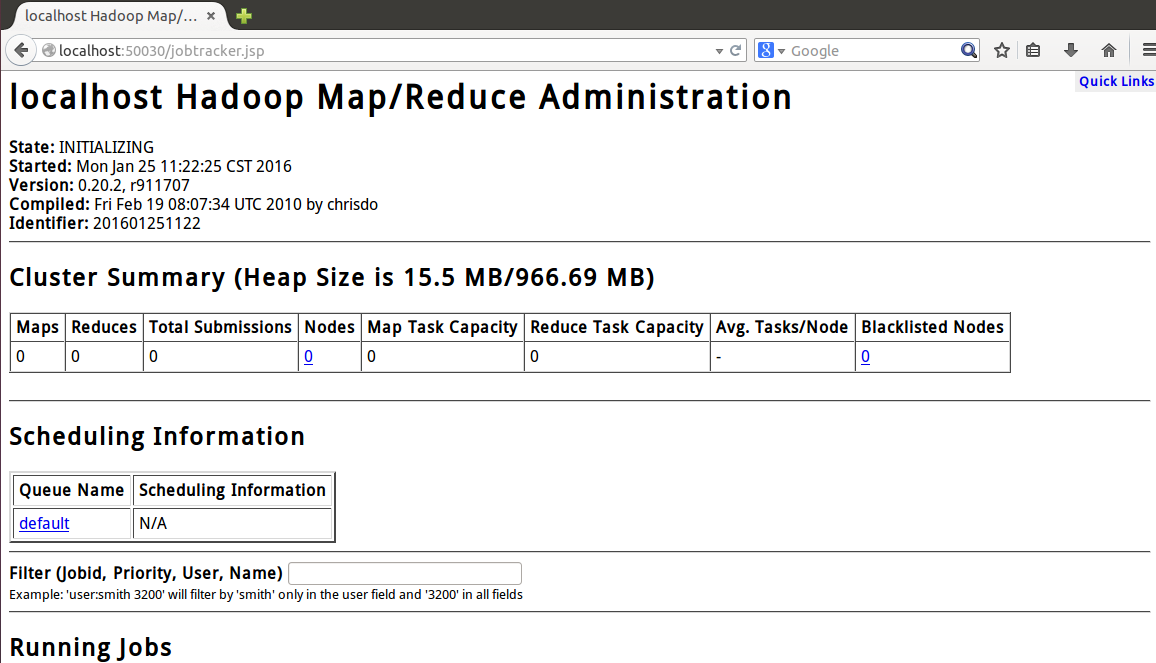
打开Linux自带的野狐禅浏览器访问http://localhost:50030,看是否能看到如下网页,证明Mapreduce组件打开成功了:
再有就是最关键的namenode组件,也就是Hadoop的核心,用浏览器访问:http://loaclhost:50070看是否能够看到如下的网页,证明整个Hadoop运行成功了:

这里补充一句,利用如下命令,也就是在Hadoop0.20.2下的bin节点访问stop-all.sh可以关闭Hadoop服务器。
./stop-all.sh
五、连通Linux虚拟机与Windows主机
类似与《【Linux】用Winscp远程访问无图形界面的Linux系统》(点击打开链接)连同虚拟机与主机。
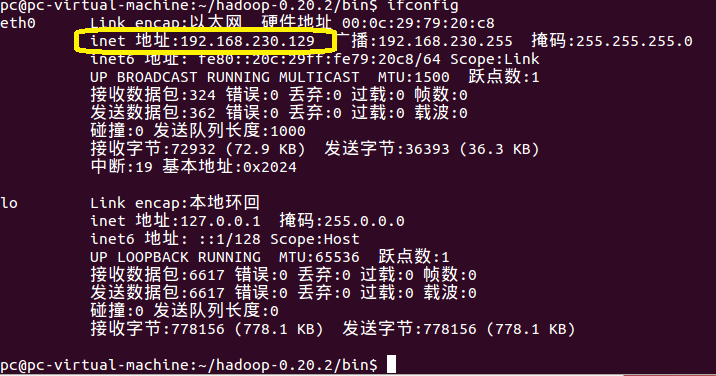
在虚拟机中通过如下的命令,查出当前虚拟机所在的内网IP,
-ifconfig
比如此处,我的Linux所在的内网IP是:192.168.230.129
那么你就在Windows下打开一个IE,输入http://192.168.230.129:50070,如果你可以看到如下的画面,证明可以在Windows下访问虚拟机下的Hadoop了。
