目录
preparedStatement和statement的区别
union和union all有什么不同?union和union all有什么不同?
什么是视图?以及视图的使用场景有哪些?
| 视图是一种虚拟的表,具有和物理表相同的功能。可以对视图进行增,改,查,操作,视图通常是有一个表或者多个表的行或列的子集。对视图的修改不影响基本表。它使得我们获取数据更容易,相比多表查询。 1.只暴露部分字段给访问者,所以就建一个虚表,就是视图。 2.查询的数据来源于不同的表,而查询者希望以统一的方式查询,这样也可以建立一个视图,把多个表查询结果联合起来,查询者只需要直接从视图中获取数据,不必考虑数据来源于不同表所带来的差异 |
使用JDBC连接数据库
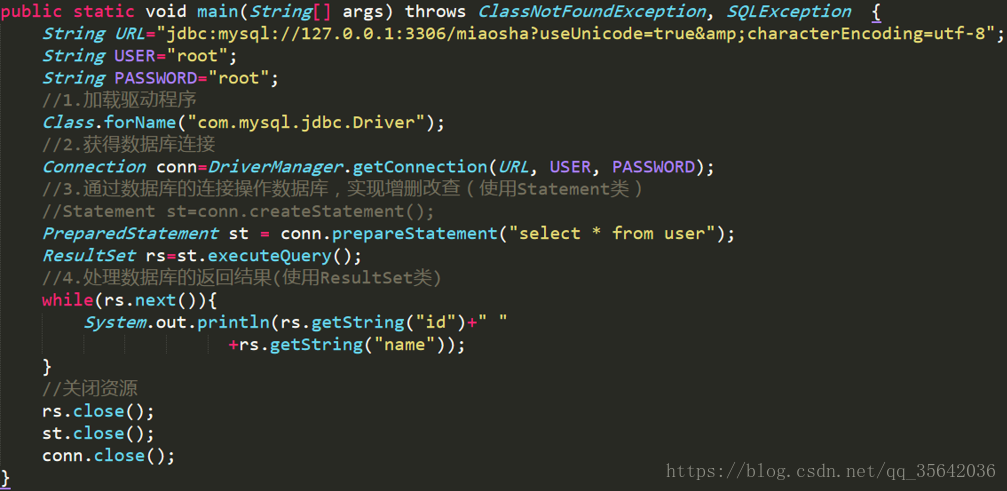
preparedStatement和statement的区别
| 说一下preparedStatement和statement的区别与联系:在JDBC应用中,如果你已经是稍有水平开发者,你就应该始终以PreparedStatement代替Statement.也就是说,在任何时候都不要使用Statement。PreparedStatement 接口继承 Statement ,PreparedStatement 实例包含已编译的 SQL 语句, 所以其执行速度要快于 Statement 对象。 Statement为一条Sql语句生成执行计划, 如果要执行两条sql语句 select colume from table where colume=1;select colume from table where colume=2; 会生成两个执行计划 一千个查询就生成一千个执行计划! PreparedStatement用于使用绑定变量重用执行计划 select colume from table where colume=:x; 通过set不同数据只需要生成一次执行计划,可以重用。 并且PreparedStatement可以防止SQL攻击 |
在数据库中查询语句速度很慢,如何优化?
| 1.建索引 2.减少表之间的关联 3.优化sql,尽量让sql很快定位数据,不要让sql做全表查询,应该走索引,把数据量大的表排在前面 4.简化查询字段,没用的字段不要,以及对返回结果的控制,尽量返回少量数据 5.尽量用PreparedStatement来查询,不要用Statement |
union和union all有什么不同?union和union all有什么不同?
| UNION在进行表链接后会筛选掉重复的记录,所以在表链接后会对所产生的结果集进行排序运算,删除重复的记录再返回结果。实际大部分应用中是不会产生重复的记录,最常见的是过程表与历史表UNION。 UNION ALL只是简单的将两个结果合并后就返回。这样,如果返回的两个结果集中有重复的数据,那么返回的结果集就会包含重复的数据了。 从效率上说,UNION ALL 要比UNION快很多,所以,如果可以确认合并的两个结果集中不包含重复的数据的话,那么就使用UNION ALL。 |
Limit的优化
| 在Limit的偏移量offset上,比如limit 100000,10虽然最后只返回10条数据,但是偏移量却高达100000,数据库的操作其实是拿到100010数据,然后返回最后10条。
那么解决思路就是,我能不能跳过100000条数据然后读取10条,而不是读取100010条数据然后返回10条数据。(案例中出发于无法直接推算出第100000条数据的id) 原SQL语句:select * from mytbl order by id limit 100000,10; 改进后的SQL语句如下: select * from mytbl where id >= (select id from mytbl order by id limit 10000,1) limit 10; 注:假设id是主键索引,那么里层走的是索引,外层也是走的索引,所以性能大大提高 |
如何设计一个论坛表
| 存在三个关系,分别是: 用户--主题帖:一个用户可以发0个或多个帖子,一个帖子对应一个用户(一对多关系), 主题帖—评论帖:一个主题有0个或多个评论帖子,一个评论帖子对应一个主题(一对多关系); 用户—评论贴:一个用户可以评0个或多个帖,一个帖子对应一个用户(一对多关系)。
对三个关系不应该分别建表,而是把用户的id作为主题表和评论表的外键,把主题贴id作为回帖表的外键。
用户表
帖子表:检索userID=某个用户id时的帖子信息
评论表:检索mainId=某个帖子ID时的评论信息。查询子评论:检索parentID=id
参考链接:http://blog.sina.com.cn/s/blog_542a862901000cbq.html
|