楼主面试的是广州网易有道移动端的岗位。网易有道一共有4轮面试。第一轮和第二轮都是技术视频面试,第三轮是总监面,要去现场面试。最后一轮是Hr面。
网易一面(45Min):
1. Android的网络框架:Volly、Okhttp、Retrofit等等
2. 详解DNS域名解析
当一个用户在地址栏输入www.taobao.com时,DNS解析大致有如下途径,具体如下:
1、浏览器缓存:浏览器会按照一定的频率缓存DNS记录。
2、操作系统缓存:如果浏览器缓存中找不到需要的DNS记录,那就去操作系统中找(Hosts文件)。
3、路由缓存:路由器也有DNS缓存。
4、ISP的DNS服务器:ISP是互联网服务提供商(Internet Service Provider)的简称,ISP有专门的DNS服务器应对DNS查询请求。
5、根服务器:ISP的DNS服务器还找不到的话,它就会向根服务器发出请求,进行递归查询(DNS服务器先问根域名服务器.com域名服务器的IP地址,然后再问.com域名服务器,依次类推)。
3. 解释一下你所理解的MVP架构
4. 操作系统中的进程调度算法
- 先来先服务调度算法
- 短进程优先调度算法
- 高相应比优先调度算法
- 最高优先权调度算法
- 时间片轮转调度算法
- 多级队列调度算法:不同队列采用不同的调度算法(前台就绪队列采用RR调度算法,后台就绪队列采用FCFS算法)
- 多级反馈队列调度算法:设置多个就绪队列,并从高到低赋予不同的优先级,每个队列采用RR算法,时间片长度从高优先级到低优先级依次增加(一般加倍)(S1<S2<…<Sn
5. Koltin中lateinit和by lazy{}的区别
- lazy{} 只能用在val类型, lateinit 只能用在var类型
- lateinit不能用在可空的属性上和java的基本类型上
- lateinit可以在任何位置初始化并且可以初始化多次。而lazy在第一次被调用时就被初始化,想要被改变只能重新定义
- lateinit 有支持(反向)域(Backing Fields)
6. 讲解一下Rxjava
7. 数据库的主键和外键
1、主键:
若某一个属性组(注意是组)能唯一标识一条记录,该属性组就是一个主键。主键不能重复,且只能有一个,也不允许为空。定义主键主要是为了维护关系数据库的完整性。
2、外键:
外键用于与另一张表的关联,是能确定另一张表记录的字段。外键是另一个表的主键,可以重复,可以有多个,也可以是空值。定义外键主要是为了保持数据的一致性。
8. 数据库的索引
数据库索引是用于提高数据库表的数据访问速度的,索引是对表中一个或多个列的值进行排序的结构。
1) 应该创建索引的列的特点:
① 在经常需要搜索的列上创建索引,可以加快搜索的速度;
② 在作为主键的列上创建索引,强制该列的唯一性;
③ 在经常用在连接的列上创建索引,主要是一些外键,可以加快连接的速度;
④ 在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的;在经常需要排序的列上创建索引,因为索引已经排序,可以利用索引的排序加快查询;
⑤ 在经常使用在WHERE子句中的列上创建索引,加快条件的判断速度。
2) 不应该创建索引的列的特点:
① 在查询中很少使用的列上不应该创建索引,因为这些列很少使用到,因此有索引或无索引,并不能提高查询速度,相反由于增加了索引,反而降低了系统维护速度,增大了空间需求;
② 在只有很少数据值的列上不应该创建索引,很少数据值的列如性别等,在查询的结果中,结果集的数据行占了表中数据行的很大比例,即需要在表中搜索的数据行的比例很大,增加索引,并不能明显加快检索速度;
③ 当修改性能远远大于检索性能时,不应该创建索引,因为改性能和检索性能是互相矛盾的,当增加索引时,会提高检索性能,但会降低修改性能,当减少索引时,会提高修改性能,但会降低检索性能。因此,当修改性能远大于检索性能时,不应该创建索引。

9. Android中的事务处理
事务是数据库更新操作的基本单位,事务回滚是指将该事务已经完成的对数据库的更新操作撤销。
所谓事务是用户定义的一个数据库操作序列,这些操作要么全做要么全不做,是一个不可分割的工作单位。例如,在关系数据库中,一个事务可以是一条SQL语句、一组SQL语句或整个程序。 简单举个例子就是你要同时修改数据库中两个不同表的时候,如果它们不是一个事务的话,当第一个表修改完,可能第二个表修改过程中出现了异常而没能修改的情况下,就只有第二个表回到未修改之前的状态,而第一个表已经被修改完毕。而当你把它们设定为一个事务的时候,当第一个表修改完,可是第二表改修出现了异常而没能修改的情况下,第一个表和第二个表都要回到未修改的状态!这就是所谓的事务回滚。
数据库事务是由一组 SQL 语句组成的一个逻辑工作单元。您可以把事务看作是一组不可分的 SQL 语句,这些语句作为一个整体永久记录在数据库中或一并撤销。比如在银行帐户之间转移资金:一条 UPDATE语句将从一个帐户的资金总数中减去一部分,另一条 UPDATE语句将把资金加到另一个帐户中。减操作和加操作必须永久记录在数据库中,或者必须一并撤销 ? 否则将损失资金。这个简单的示例仅使用了两条 UPDATE 语句,但一个更实际的事务可能包含许多 INSERT、UPDATE和 DELETE 语句。
使用SQLiteDatabase的beginTransaction()方法可以开启一个事务,程序执行到endTransaction() 方法时会检查事务的标志是否为成功,如果程序执行到endTransaction()之前调用了setTransactionSuccessful() 方法设置事务的标志为成功,则所有从beginTransaction()开始的操作都会被提交,如果没有调用setTransactionSuccessful() 方法则回滚事务。
10. Java面向对象的特点
- 多态。同一个行为有不同的表现
- 封装。对象数据和操作该对象的指令都是对象自身的一部分,能够实现尽可能对外部隐藏数据。
- 继承。
11. Java中的多态
- 继承
- 重写
- 父类引用指向子类对象
12. ViewModel的作用
- Activity、Fragment存活期间的数据存储
- 独立或与LiveData配合实现代码解耦
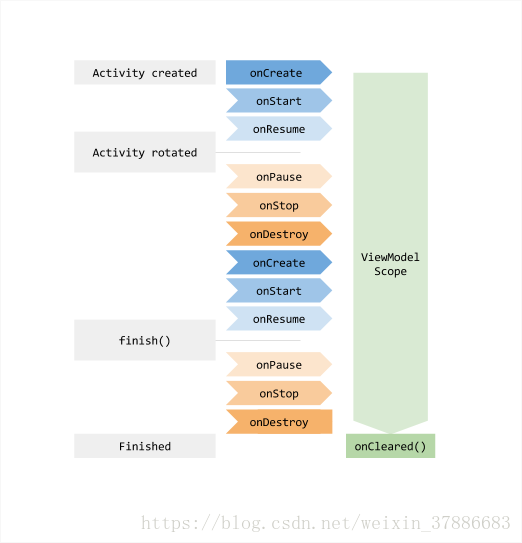
ViewModel的生命周期与Lifecycle同步,当Activity /Fragment超出Lifecycle范围(并不是onDestroy()回调),ViewModel连同其包含的数据一起被销毁了。 Activity退栈后(Fragment则是与Activity解除关系后),ViewModel就解除引用关系,准备被系统回收了。下面这张图片更直观的展示了ViewModel的生命周期:
13. Http1.0和Http1.1的区别
HTTP 1.1支持长连接(PersistentConnection)和请求的流水线(Pipelining)处理
HTTP 1.0规定浏览器与服务器只保持短暂的连接,浏览器的每次请求都需要与服务器建立一个TCP连接,服务器完成请求处理后立即断开TCP连接,服务器不跟踪每个客户也不记录过去的请求。
HTTP 1.1则支持持久连接Persistent Connection, 并且默认使用persistent connection. 在同一个tcp的连接中可以传送多个HTTP请求和响应. 多个请求和响应可以重叠,多个请求和响应可以同时进行. 更加多的请求头和响应头(比如HTTP1.0没有host的字段).
在1.0时的会话方式:
1. 建立连接
2. 发出请求信息
3. 回送响应信息
4. 关掉连接
HTTP 1.1的持续连接,也需要增加新的请求头来帮助实现,例如,Connection请求头的值为Keep-Alive时,客户端通知服务器返回本次请求结果后保持连接;Connection请求头的值为close时,客户端通知服务器返回本次请求结果后关闭连接。HTTP 1.1还提供了与身份认证、状态管理和Cache缓存等机制相关的请求头和响应头。
请求的流水线(Pipelining)处理,在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟。例如:一个包含有许多图像的网页文件的多个请求和应答可以在一个连接中传输,但每个单独的网页文件的请求和应答仍然需要使用各自的连接。 HTTP 1.1还允许客户端不用等待上一次请求结果返回,就可以发出下一次请求,但服务器端必须按照接收到客户端请求的先后顺序依次回送响应结果,以保证客户端能够区分出每次请求的响应内容。
2.HTTP 1.1增加host字段
在HTTP1.0中认为每台服务器都绑定一个唯一的IP地址,因此,请求消息中的URL并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。
HTTP1.1的请求消息和响应消息都应支持Host头域,且请求消息中如果没有Host头域会报告一个错误(400 Bad Request)。此外,服务器应该接受以绝对路径标记的资源请求。
3、100(Continue) Status(节约带宽)
HTTP/1.1加入了一个新的状态码100(Continue)。客户端事先发送一个只带头域的请求,如果服务器因为权限拒绝了请求,就回送响应码401(Unauthorized);如果服务器接收此请求就回送响应码100,客户端就可以继续发送带实体的完整请求了。100 (Continue) 状态代码的使用,允许客户端在发request消息body之前先用request header试探一下server,看server要不要接收request body,再决定要不要发request body。
4、HTTP/1.1中引入了Chunked transfer-coding来解决上面这个问题,发送方将消息分割成若干个任意大小的数据块,每个数据块在发送时都会附上块的长度,最后用一个零长度的块作为消息结束的标志。这种方法允许发送方只缓冲消息的一个片段,避免缓冲整个消息带来的过载。
5、HTTP/1.1在1.0的基础上加入了一些cache的新特性,当缓存对象的Age超过Expire时变为stale对象,cache不需要直接抛弃stale对象,而是与源服务器进行重新激活(revalidation)
14. Okhttp如何发送Cookie
15. CodeShare写代码,判断单链表是否为对称链表
当场写的代码,不知对错,觉得思路大概是正确的
/**
* 思路:先遍历一次链表,获得链表的长度,然后从链表中心开始翻转后半部分链表
* 然后比较前半部分链表和后半部分链表
* (需要注意链表长度为奇数或者偶数的情况)
*/
public boolean isCentralSymmery(ListNode head){
if(head == null){
return false;
}
int len = 0;
ListNode tmp = head;
while(tmp != null){
len++;
tmp = tmp.next;
}
ListNode front = head;
ListNode behind = head;
for(int i = 0; i < len >> 1; i++){
behind = behind.next;
}
if(len & 0x1 == 1){
behind = behind.next;
}
ListNode pHead = behind;
ListNode pre = null;
ListNode next= null;
while(pHead != null){
next = pHead.next;
pHead.next = pre;
pre = PHead;
PHead.next = next;
}
behind = pre;
for(int i = 0; i < len >> 1; i++){
if(front.val != behind.val){
return false;
}
}
return true;
}网易二面(40Min):
1. Andorid的优化,内存优化,布局优化,性能优化
2. Android中Emun的实现原理
3. 问项目,Android桌面小插件
4. Binder和AIDL
5. CodeShare写代码,判断二维矩阵中是否包含某字符串
public boolean isContainsWord(char[][] matrix, int rows, int cols, char[] target) {
if (matrix == null || rows < 1 || cols < 1 || target == null) {
return false;
}
boolean[][] visited = new boolean[rows][cols];
int pathLength = 0;
for (int row = 0; row < rows; row++) {
for (int col = 0; col < cols; col++) {
if (contains(matrix, row, col, rows, cols, target, visited, pathLength)) {
return true;
}
}
}
return false;
}
public boolean contains(char[][] matrix, int row, int col, int rows, int cols, char[] target, boolean[][] visited,
int pathLength) {
if (pathLength == target.length) {
return true;
}
boolean containWord = false;
if (row >= 0 && row < row && col >= 0 && col < cols && matrix[row][col] == target[pathLength]
&& !visited[row][col]) {
++pathLength;
containWord = contains(matrix, row + 1, col, rows, cols, target, visited, pathLength)
|| contains(matrix, row - 1, col, rows, cols, target, visited, pathLength)
|| contains(matrix, row, col + 1, rows, cols, target, visited, pathLength)
|| contains(matrix, row, col - 1, rows, cols, target, visited, pathLength);
if (!containWord) {
--pathLength;
visited[row][col] = false;
}
}
return containWord;
}网易三面(1.5h):
请设计一下微博的系统架构,主要实现如下两个功能
1:发微博
2:汇总关注人的消息流
要求: 高并发、高吞吐、服务器压力低
需要考虑如下的极端情况:
1. 1个用户有数千万的粉丝
2. 1个用户关注了非常多的博主
3. 数据量非常庞大时如何存储?
4. 如何进行快速的检索工作?
5. 遇到突发的情况,如某人爆红,应该怎么处理?
6.......
Hr面(45Min):
和Hr全程三八了很久,反正全程一直被怼,不想回忆了......