版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/Register_man/article/details/79075935
前言
一提到Python爬虫,人人都想使用知名框架Beautiful Soup或是Scrapy,新手贸然进入,必是学的云里雾里,即使能够爬到数据,也根本不知其所以然!
想学习爬虫,html5 tag , ajax,get,post是绕不过的,但是并不需要一开始就完全掌握。当你需要使用到时去网上学习即可!
开始
爬虫的第一步,必须要根据一个明确的url从目标服务器,把html页面代码下载下来:
比如说我们想下载百度首页的代码
import requests
url = "https://www.baidu.com/"
respond = requests.get(url)
print(respond.content)解析
现在假设我们的需求是下载百度图标:
那么我们就需要找到该图片的链接:
我们可以从下图中看到,百度图片 url 地址保存在一个叫做 'img' 的标签的'src' 属性上,而'img' 标签在一个'id="lg"' 的'div' 标签内。

使用一种叫做 XPath 的描述方式可以表述为://*[@id="lg"]/img
我们可以使用 XPath路径获取某个标签
import requests
from lxml import html
url = "https://www.baidu.com/"
respond = requests.get(url)
document = html.fromstring(respond.content)
tag_list_img = document.xpath('//*[@id="lg"]/img')
for tag_img in tag_list_img:
img_url = tag_img.get("src")
print(img_url)我们使用 html.fromstring()来解析html,通过 xpath()来查询标签,需要注意的是xpath()永远返回一个 list
可以使用get()和set()来操作标签,可以使用text_content()来获取标签内部文本,或者可以继续对标签调用xpath()方法继续查询。
实战
现在,我们试着获取百度搜索Python关键字的第一页结果标题和网址:
此时如果按照上面的方法直接下载网页,并不能得到正确的文件,我们需要为访问方法加上一个headers参数,并提供
User-Agent,即用户标识,以模拟浏览器环境。
import requests
from lxml import html
url = "https://www.baidu.com/s?wd=Python"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'
}
respond = requests.get(url, headers=headers)
document = html.fromstring(respond.content)
tag_list = document.xpath('//*[@class="result c-container "]/h3/a[1]')
for tag in tag_list:
url = tag.get("href")
title = tag.text_content()
print(title, url)

Cookies
cookies保存了许多键值对,使得服务器能够对当前请求者进行唯一标识,目的是为了完成用户的自动登录。
我们可以在浏览器自带的开发者工具中的Network标签中,找到目标url的请求体中的Headers即可找到cookies
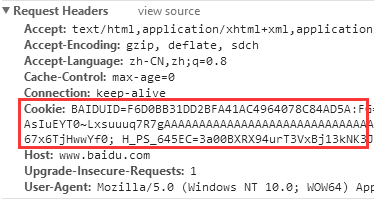
将cookie的值完全拷贝出来后需要进行下一步的处理,将cookies转化为dict:
cookies_str = 'url的cookies'
cookies = {}
for c_str in cookies_str.split(";"):
k, v = c_str.split("=", 1)
cookies[k.strip()] = v.strip()完成之后,只需要在requests的get或post方法中传入该参数即可:
respond = requests.get(url, cookies=cookies, headers=headers)传递参数
访问网页有get和post两种方式,主要的区别是传参方式不同,
get方法,直接在url的?后面传递参数,也只能传递简单的字符串,如:https://www.baidu.com/s?wd=Python
post方法则将参数放在整个请求体中,可以传递的参数大小没有限制。
即使使用get方法,将参数直接写在url中也是不够优雅的,所以我们只需要在请求连接时传递一个dict参数即可
params = {
'callback': 'jQuery183010650035300910066_1514276718854',
'jsondata': '{"type": "updatenodelabel", "isCache": true}'),
'_': '1514276904732'
}
respond = requests.get(url, params=params, headers=headers)