本篇讨论同时使用多个ES Cluster进行搜索的时候,如何保证数据的一致性。
• 名词解释
Cluster:集群,一个集群包含多个Node,且会有一个Master Node。
Node:节点,一般来说一个机器部署一个Node。
Shard:分片,指的是一个Index分成多少份,这些Shards会分散到各个Node上面。
• 为什么要使用多个ES Cluster?
高可用方面:
ElastcSearch拥有许多高可用的特性,例如Replica,例如Data Node挂掉后的数据迁移,例如Master Node挂掉后的自动重选,但这不代表万无一失了。常见的坑是,某个Node表现糟糕但是偏偏又没挂(挂了反而更好),此时整个Cluster的性能就会被一个坑爹Node拖累,这往往就是雪崩的开始。因此,从高可用方面来考虑,应当部署多个ES Cluster(部分作为灾备)。
性能方面:
单个Cluster的搜索能力是有瓶颈的。Cluster越大,Node越多,自然Shard就越多。而Shard不是越多越好,Shard增多会导致通讯成本的增加、查询收束时Re-ranking环节的负担增加。如果有100台机器,那么比起一个100 Node、300 Shards的巨型Cluster,使用十个10 Node 30 Shards的小型Cluster可能表现会更好。
• 什么叫多个ElastcSearch Cluster的一致性问题?
本篇讨论的就是使用多个小型Cluster、而不是一个巨大Cluster进行搜索时会出现的问题。
假设部署了两个Cluster,记为Cluster A和Cluster B,请求均摊去两个Cluster。有一天,你对两个Cluster同时新增了一条数据,但由于一些网络延迟之类的理由,A已经添加了但是B还没有,这时候一个用户搜索请求进来,可能会出现这么个情况:
如果请求的pageSize=4。page=1时,用户请求去了Cluster B;page=2时,用户请求去了Cluster A。这样,用户会看到以下的结果:
 如果请求的pageSize=4。page=1时,用户请求去了Cluster B;page=2时,用户请求去了Cluster A。这样,用户会看到以下的结果:
如果请求的pageSize=4。page=1时,用户请求去了Cluster B;page=2时,用户请求去了Cluster A。这样,用户会看到以下的结果:用户:黑人问号.jpg
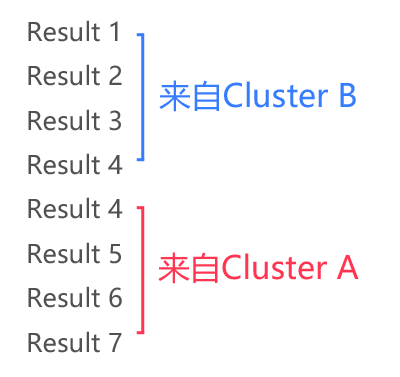 用户:黑人问号.jpg
用户:黑人问号.jpg更糟糕的是,万一在ES前面有一层缓存挡着,而缓存不巧记录了这个诡异的结果,那影响就会扩大了(所有用户:黑人问号.jpg)。
• 解决方案A:单点大法
1. 进入业务请求低谷期时,把所有请求切去1个ES Cluster;
2. 所有ES Cluster开始进行数据同步;
3. 同步完毕后,同时准备离开请求低谷期了,请求开始均摊到多个ES Cluster上。
优点:简单粗暴就是美。能简单粗暴解决的,就不要套复杂的东西。
缺点:1)每天高峰期不能新增数据;2)必须要在低谷期内完成所有数据同步,万一数据同步流程很长且时间不可控则很难实现;3)单点要能够顶过低谷期,万一流量判断错误、或者被攻击,导致单点崩溃,可能发生严重事故。
• 解决方案B:切别名大法
多个ElastcSearch Index的名字切换是个原子操作(搜索"elasticsearch alias"),所以可以这样:
1. 创建两个一样的Index(记为A1、A2);
2. 同步数据到A1;
3. 同步完后,设置别名A,指向刚刚同步好数据的A1(记为A->A1);
4. 使用A进行搜索,请求均摊到每个ES Cluster上;
5. 每次Re-load的时候,所有ES Cluster将数据更新到那个待机中的Index(例如A->A1,那么就更新A2,反之亦然)。在所有ES Cluster都完成数据更新后,同时切换别名(如A->A1,则A->A2,反之亦然)。
优点:比方案A优雅多了。
缺点:1)每个Index要创建两份,存储成本翻倍;2)跟方案A一样,不能实时添加数据;3)实际上,只要是均摊请求,就会出现不一致的问题,ElasticSearch可能根据分片的不同会出现不同的得分,不应使用均摊。
• 解决方案C:哈希大法
1. 对请求进行哈希/散列,确保一个请求每次都会去到同一个ES Cluster;
2. 每个ES Cluster该干嘛干嘛。
优点:比方案B优雅多了,还能实时添加数据。
缺点:万一其中一个ES Cluster挂掉了,怎么办?均摊请求的做法可以很轻松地将挂掉的ES Cluster整个踢出去,那哈希法呢?
• 解决方案D:一致性哈希大法
终于还是到了这一招,新增一层虚拟层,将每个ES Cluster抽象成一个环上的虚拟节点。每个请求在哈希后,先映射去虚拟层,再映射去真实的ES Cluster。
由于每个ES Cluster都存储了完整的数据拷贝,我们并不需要考虑一致性哈希的数据迁移问题。每次新增/删除ES Cluster,就重新分配虚拟节点的位置(环上均分),就可以了。

• 一个新的问题:如何确保多个ES Cluster的更新操作的一致性?
上述全文都在讨论搜索的一致性,那么如何保证插入/更新的一致性呢?
我的解法是,加入一层可以被多人重复消费的消息队列(例如Kafka),作为所有ES Cluster插入/更新的中间层。

这个方案的好处是:
1)主更新程序只有一个,提高可控性和发现问题的能力;
2)使用消息队列来统一发布内容,降低了对数据源的压力;
3)图中消费者这个角色,Elastic Stack官方提供了一个轻量级高可用解决方案,就是Beat。
• 最后留一个小问题
前文讨论了多个Cluster+缓存时出现的一致性问题,其实单Cluster+缓存也可能出现这个问题(极少就是了)。那么,有没有办法彻底解决这个问题呢?
• 结语
ElasticSearch本身是个分布式系统,但如果将其作为一个更大的分布式系统的一个单元的话,将会出现什么问题呢?本文希望可以通过循序渐进的方法,分析围绕ES的高可用方案设计,有许多问题是分布式系统里常见的问题,希望可以对读者有所启发。
https://zhuanlan.zhihu.com/p/24302699