过往的经历告诉我们,好记性不如烂笔头,永远都不要觉得很简单就放松警惕。以下是自己对 Java 的一些易忘点的记录,如果对你有帮助,请别忘了点赞哦!
1B(字节) = 8bit(比特位)
byte(1) - short(2) - int(4) - long(8) - float(4) - double(8) - char(2) - boolean(1)
关键字及标识符的概念
关键字是 Java 预先定义好的标识符,较为特殊,有其自己的含义。
标识符是给类,接口,方法,变量等起名字时使用的字符序列
标识符的定义规则:
1、组成规则
数字
字母
$和_
2、注意事项
不能以数字开头
不能使用关键字
严格区分大小写,尽量做到见名知意
switch 语句接收的类型
JDK1.0-1.4 :byte、short、int、char
JDK1.5 :byte、short、int、char、enum(枚举)
JDK1.7 :byte、short、int、char、enum(枚举)、String
Java中除法注意事项
19/10=1
12/10=1
不会根据结果进行四舍五入
JVM 的内存划分
JVM的内存分为以下 5 个部分:
1、寄存器:内存和 CPU 之间的通信
2、本地方法栈:JVM 调用系统中的功能
3、方法和数据共享区:运行时期 .class 文件进入的地方
4、方法栈:所有的方法运行的时候进入的地方
5、堆:存储容器和对象
数组最简单的定义方式
一维数组:int[] arr = {1,4,6,12};
二维数组:int[][] arr2 = { {1,2,4} , {3,5,7,1,4} };
方法的重载
Java中,在同一个类中,允许出现多个同名的方法,但参数列表必须不同(参数的类型和个数),这就是Java中方法的重载。
ASCII 编码表常见数值
48 — 0
65 — A
97 — a
char 类型的取值范围
0 – 65535
没有负数的概念,16位都表示数值位
数组的排序
默认都是升序排序,元素从小到大。
基本规则:比较大小,位置交换
常见思想:
1、选择排序:先用数组的第一个元素和依次和其他元素相比,小的放在第一个位置,结束后最小的值就在第一的位置; 在用数组的第二个元素和后面的元素依次比较,如果第二个元素大于其他元素,就交换位置,第二小的值就在第二个位置;依次类推。
eg:n个元素的数组,第一次要比较 n-1次,依次类推,直到比 1 次。
先确定较小的数,直到最大
public static void selectSort(int[] arr){
for(int i = 0;i < arr.length-1;i++){
for(int j = i+1;j < arr.length;j++){
if(arr[i] > arr[j]){
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
}
}
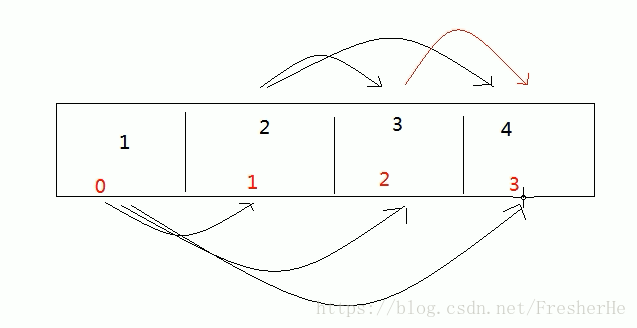
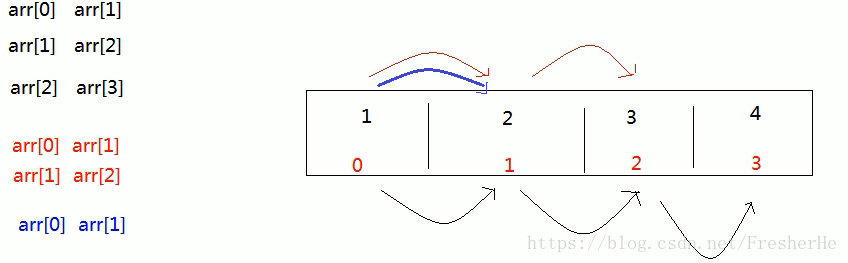
2、冒泡排序:数组中相邻元素进行比较,每次都从头开始,但以确定的较大值就不做比较
eg:n个元素的数组,第一次要比较 n-1次,依次类推,直到比 1 次。
先确定最大的值,直到最小
public static void bubbleSort(int[] arr){
for(int i = 0;i < arr.length-1;i++){
for(int j = 0;j < arr.length-i-1;j++){
if(arr[j] > arr[j+1]){
int temp = arr[j+1];
arr[j+1] = arr[j];
arr[j] = temp;
}
}
}
}
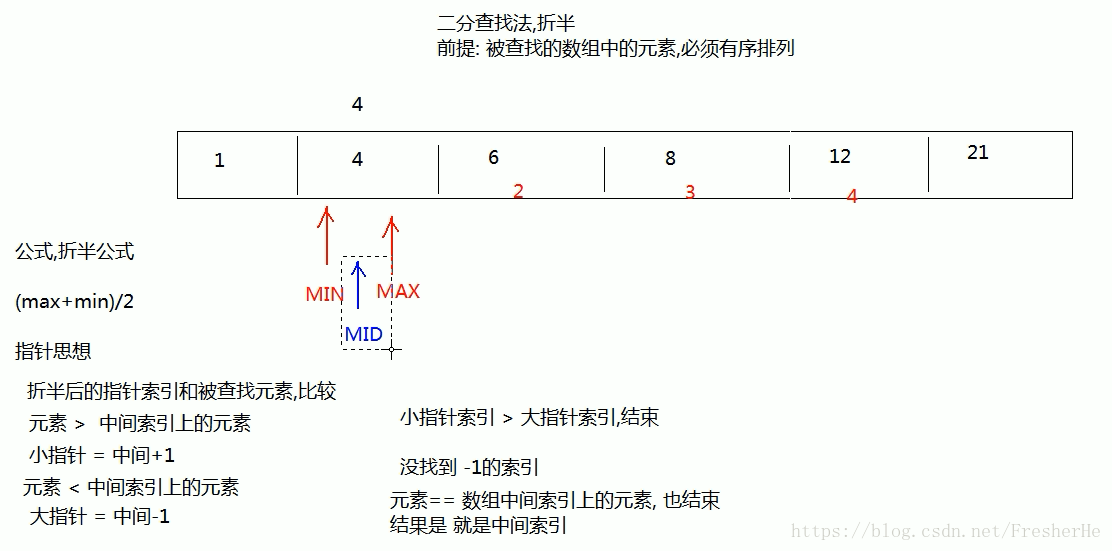
二分查找法(折半)
前提:被查找的数组中的元素必须有序
对象创建内存图
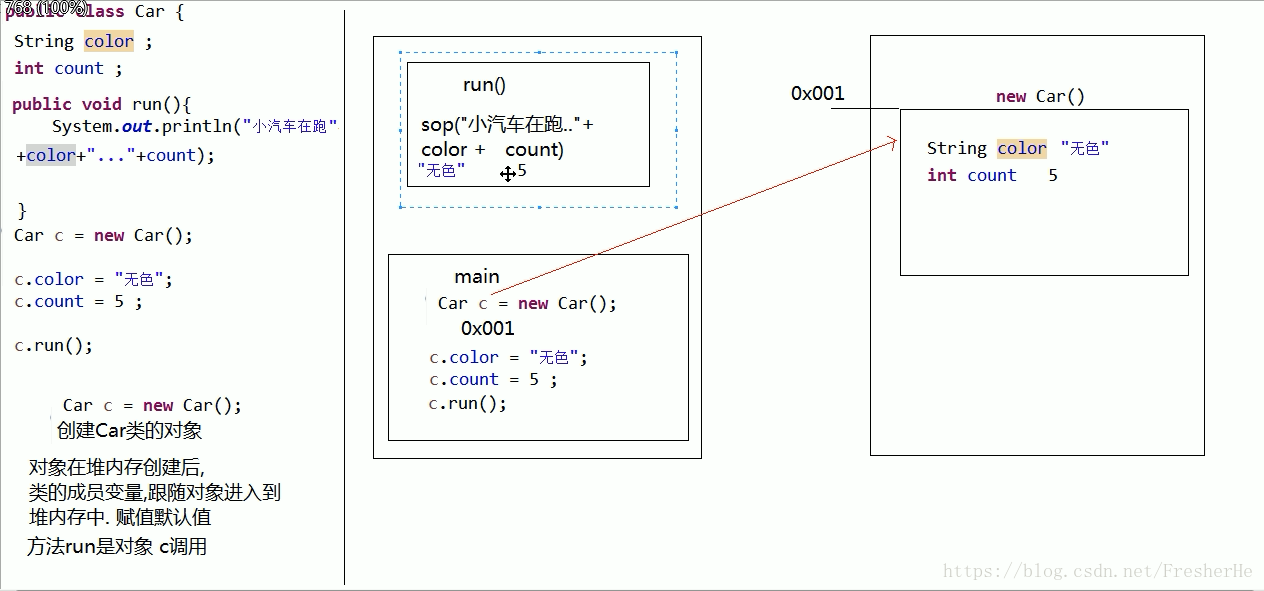
栈内的内容运行完后就释放;而堆中的内容是由 GC 去管理释放。
成员变量 VS 局部变量
1、定义位置不同
2、作用域不同
3、默认值不同
成员变量:有自己的默认值
局部变量:没有自己的默认值,不赋值不能使用
4、内存位置不同
成员变量:跟随对象进入到堆内存存储
局部变量:跟随自己所在的方法进入栈内存
5、生命周期不同
成员变量:跟随对象,在堆中存储。内存要等到 JVM 清理,生命周期较长。
局部变量:跟随方法,在栈内存中存储。方法出栈即销毁,生命周期较短。
面向对象的三个特征 * — 封装;继承;多态*
封装
封装的体现:
1、方法就是最基本的封装体
2、类也是一个封装体
3、私有 仅仅是封装的一种体现形式
封装的好处:
1、提高代码的复用性
2、提高代码的安全性
3、隐藏了代码的细节,提供公共的访问方式。
继承 需要满足 is a 关系
extends
继承的好处:
1、继承提高了代码的复用性和可维护性,提高了软件的开发效率
2、继承让类与类之间产生了关系,提供了 多态的前提
继承的弊端:
类与类之间耦合度增高
多态
多态的前提:必须有子父类关系 或 类实现接口
格式: 父类or接口 变量 = new 子类or实现类();
注意:在使用多态后的 父类引用变量调用方法时,会调用子类重写后的方法。
多态中,成员特点
成员变量(静态和非静态):
编译的时候,参考父类中有没有这个变量。如果有,编译成功;没有,编译失败。
运行的时候,运行的是父类中的变量值。‘’
变量:编译运行全看父类。
成员方法:
编译的时候,参考父类中有没有这个方法。如果有,编译成功;没有,编译失败。
运行的非静态方法,运行的是子类中的方法。 如果是静态的方法,就运行父类中的方法。
方法:编译看父类,运行看子类。
为什么在多态中,静态成员方法调用的是父类的静态成员方法?
因为静态成员方法属于类,不属于对象。
对象的多态性,静态和对象无关。因为是父类的引用调用的静态方法,所以调用就是父类的静态成员变量。
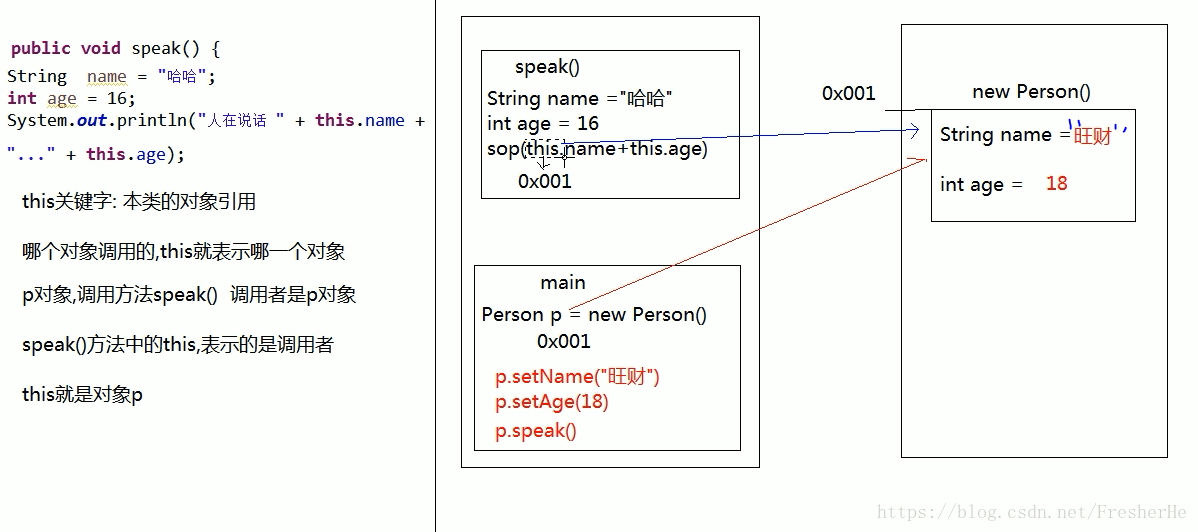
this 的内存图
this 表示当前类的对象
继承后,子父类中成员变量的特点
1、子类对象,调用同名成员变量。如果子类有,就调用子类的成员变量;反之,调用父类的成员变量
注意:this. 调用的是本类的成员; super. 调用的自己父类的成员。
继承后,子父类中成员方法的特点
1、子类对象,调用同名成员方法。如果子类有,就调用子类的成员方法;反之,调用父类的成员方法
2、方法的重写 Override(方法的返回类型、方法名、参数列表都要一样)
子类中,出现了和父类一样的方法时,子类重写了父类的方法,覆盖
abstract 不可以和哪些关键字共存
private
final
static
抽象类
抽象方法所在的类必须是抽象类;抽象类中可以有非抽象的方法;如果抽象类中全都是非抽象的方法,意义何在?可以避免创建该类的对象,也是为了完善继承体系结构。
接口
1、接口中方法均为 公共的抽象方法。 固定修饰符:public abstract
2、接口中只有静态成员常量,没有成员变量。 固定修饰符:public static final
3、接口和接口之间继承关系,而且可以多继承
多继承 VS 多实现
1、为什么 Java 中不允许多继承?
存在安全隐患。因为当子类不重写 多个类中的同名方法时,创建子类对象时,不知道调用的是哪个父类的方法;
2、为什么 Java 中允许多继承?
不存在多继承的安全隐患。因为接口的方法都是抽象方法,没有功能主体。实现类必须重写,才能创建对象。所以不存在安全隐患。解决了单继承的局限性。
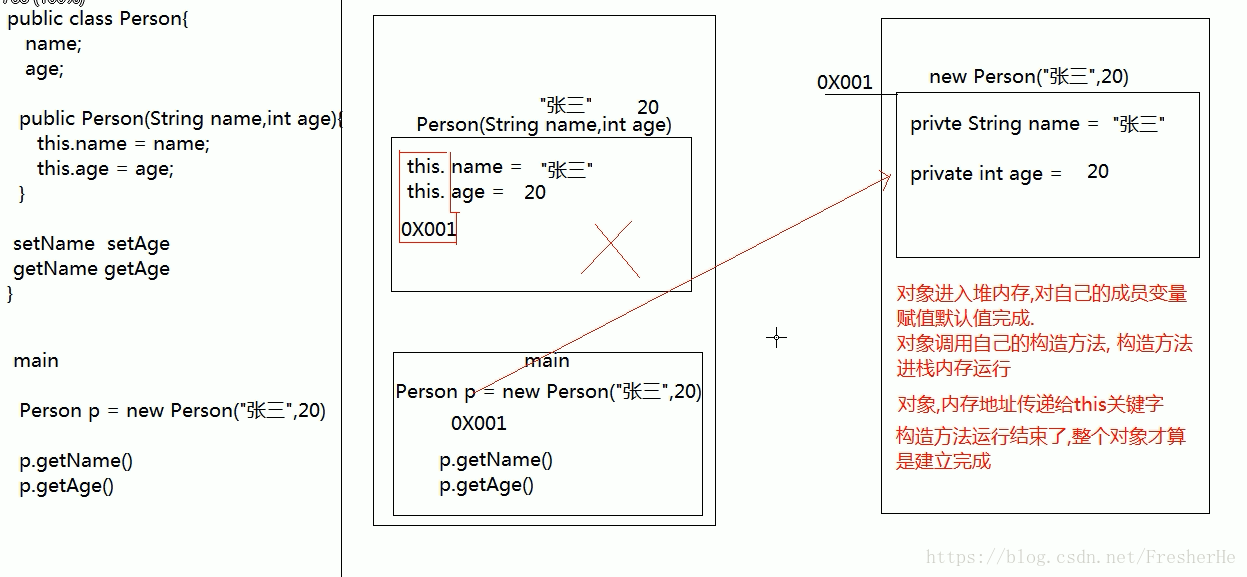
构造方法的内存图
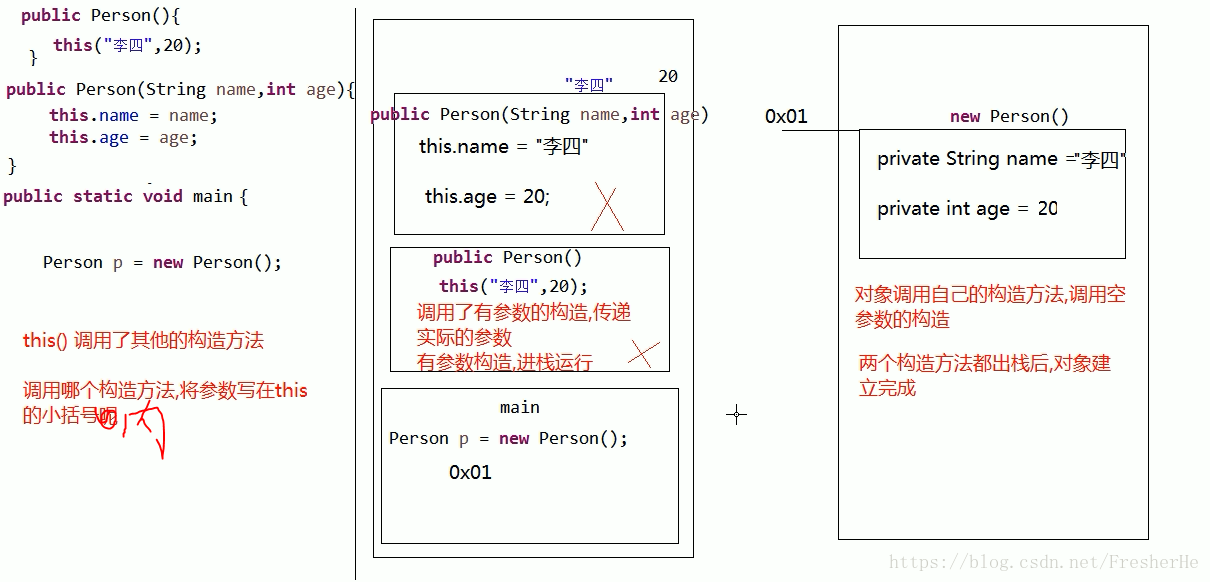
this的用法
1、this. 的方式,区分同名的局部变量和成员变量。
2、this 可以在构造方法之间调用 。this(参数列表); 必须放在构造方法的第一行。
super的使用
1、super.父类成员变量
2、super.父类成员方法
3、super() 在子类构造中,调用父类的构造方法
构造方法注意事项
在子类所有的构造方法的第一行,有个默认隐式代码:super(); 我们也可以手动调用父类的任一一个构造。
super 表示父类存储的位置。
构造方法不能继承,没有重写的概念
supe() 必须在构造方法的第一行。
子父类子类创建对象时内存图
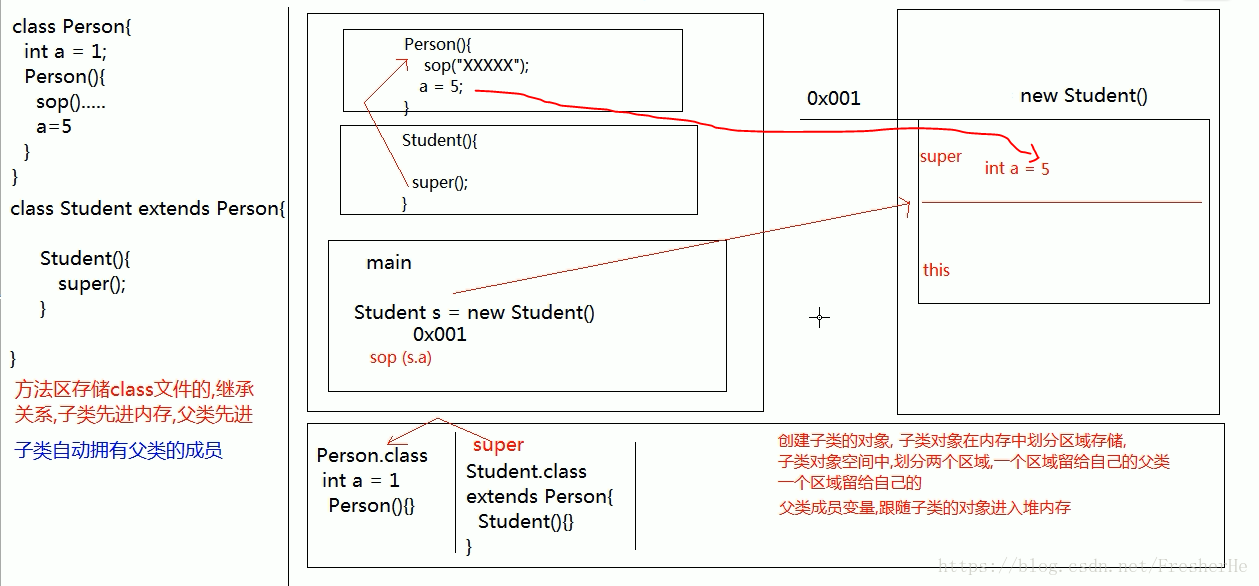
构造方法第一行的角逐
this() 和 super() 都只能写在 构造 方法的第一行,矛盾了?
不能同时存在,任选其一。保证子类的所有构造方法能调用到父类的构造方法即可。
被 final 修饰的成员变量的赋值方式
定义时直接 = 号赋值
构造方法中赋值
构造代码块中赋值
注意:需要在创建对象前赋值,且只能赋值一次
static 存在的意义
static 修饰的成员属于类,而非属于对象
生命周期:随着类的加载而加载,随着类的销毁而销毁
意义:共享的属性和方法。eg:同一个学校的学生信息的学校名,就可以用 static 修饰;又比如饮水机中的水。注意:在静态中不能调用非静态,为何?
静态随着类的加载而加载带方法区中的静态区,属于类,优先于非静态在内存中。
静态不能用this和super
static 的内存图
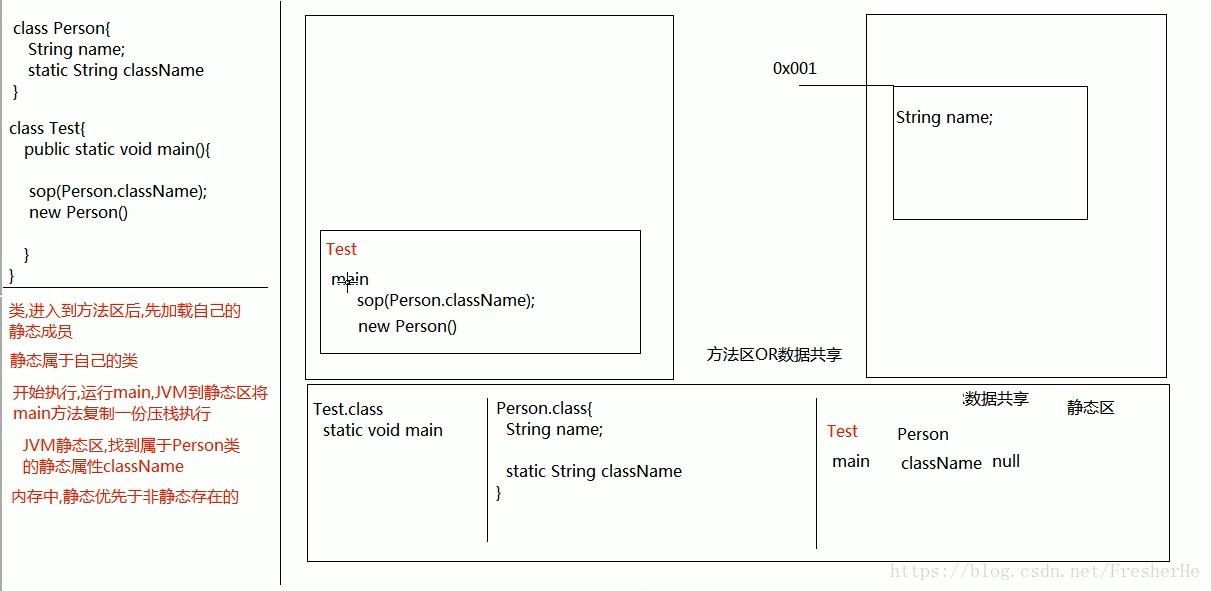
static 的使用场景
成员变量:具体事物,具体分析
定义事物的时候,思考多个事物是否有共性的数据!有,就加 static
成员方法:跟着变量走
如果方法中没有调用非静态的成员,将方法定义为静态的。加 static
内部类
内部类根据声明的位置的不同,分为 成员内部类(声明在类的成员位置的类))和 局部内部类(声明在方法中的内部类)
内部类可以直接访问外部类的成员,包括私有的。
成员内部类:
既然声明在成员的位置,也就可以用成员修饰符修饰。比如,public static …
访问规则:
内部类可以访问外部类的成员,包括私有的。
外部类要使用内部类的成员,必须创建内部类的对象。Outer.Inner inn = new Outer().new Inner();
Outer.this –> 表示Outer类的对象
局部内部类:
访问规则:局部内部类只能由自己所在的成员方法去访问,外部是不能获取到的。除非,通过 return 去返回,但一般都不这么做。一般是方法内部自己调用。
最常使用的内部类是 匿名内部类。注意:匿名内部类只能写在方法中。
1、临时定义某一类型的子类对象
格式:
new 父类或接口(){
// 对方法进行重写
};包的命名规则
域名反写,全小写,以 . 分割
eg:www.baidu.com
包:com.baidu.search(功能)
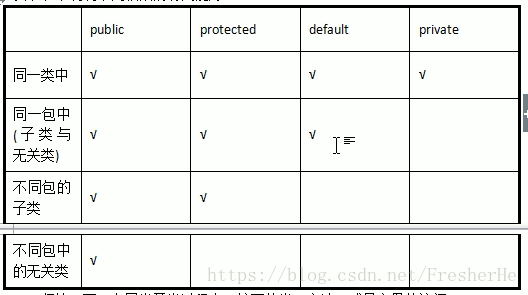
权限修饰符
代码块
静态代码块
只执行一次
构造代码块
new 一次,执行一次,优先于 构造方法
局部代码块
限制变量的生命周期
成员变量和局部变量的选择
思考这个变量属于谁?
属于事物本身,就定义为成员变量。
属于每个独立计算的功能,就定义局部变量。
Object
Object 类是 Java 中所有类的根类。但是 接口 不继承 Object。
equals()方法:注意,我们在重写父类的 equals(Object obj) 方法时,参数是 Object 类型。在调用属性前,一定要进行非空判断,类型判断,向下转型。还要注意程序的执行效率。
在自定义数据类型时,最好重写 equals(Object obj) 和 toString() 方法
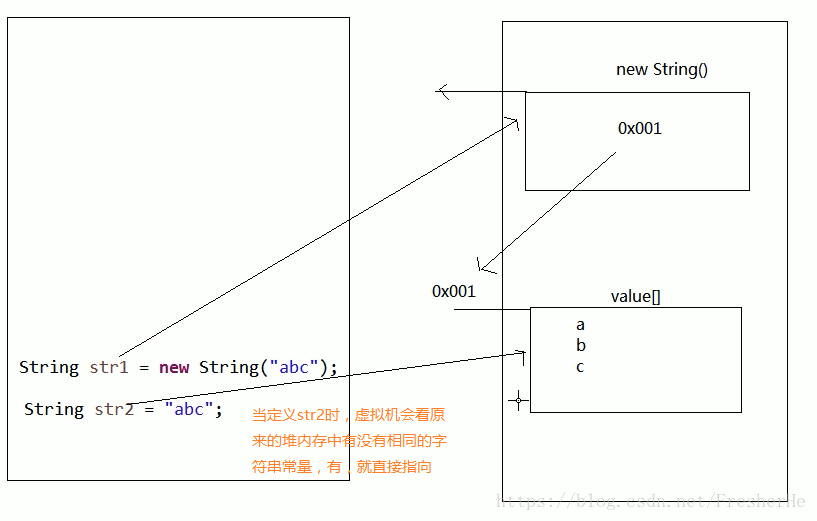
new String() 创建方式内存图
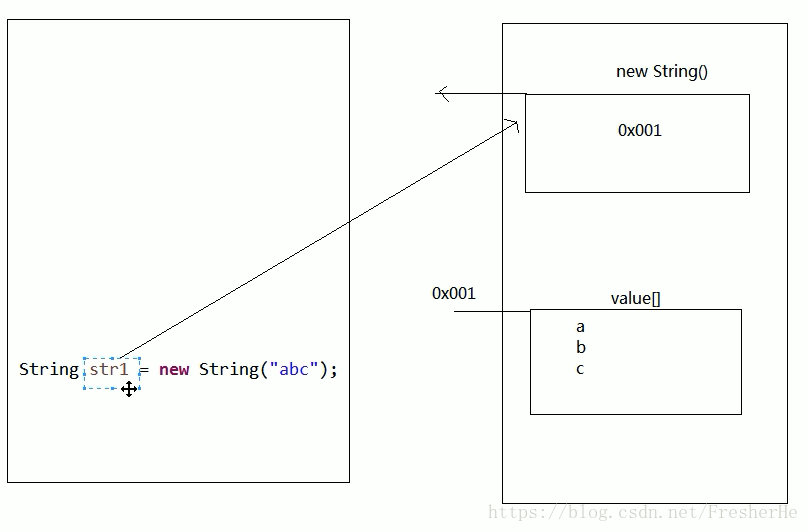
String 内存注意事项
StringBuffer VS StringBuilder
两者都是可变的字符序列。
StringBuffer 线程安全,效率低。
StringBuilder 线程不安全,效率高。
Java 中的常量优化机制
int a = 4 + 5; //在编译时,就会计算出 9,把值赋值给a
String str = "ab" + "c";//在编译时,就会计算出 "abc",把值赋值给str
注意:而且当堆内存中已经存在 "abc" 时,我们再次定义 "abc",就会直接指向之前内存中已经存在的 "abc"
正则表达式(Regular Expression)regex
本质是一个字符串,用来定义匹配规则。常用来检索、替换、校验字符串。
可以将多个规则用 () 括起来eg:
.com.cn
(\.[a-z]+)+
正则表达式的语法规则:
字符:x
含义:代表的是字符x
例如:匹配规则为 “a”,那么需要匹配的字符串内容就是 ”a”
字符:\
含义:代表的是反斜线字符’\’
例如:匹配规则为”\” ,那么需要匹配的字符串内容就是 ”\”
字符:\t
含义:制表符
例如:匹配规则为”\t” ,那么对应的效果就是产生一个制表符的空间
字符:\n
含义:换行符
例如:匹配规则为”\n”,那么对应的效果就是换行,光标在原有位置的下一行
字符:\r
含义:回车符
例如:匹配规则为”\r” ,那么对应的效果就是回车后的效果,光标来到下一行行首
字符类:[abc]
含义:代表的是字符a、b 或 c
例如:匹配规则为”[abc]” ,那么需要匹配的内容就是字符a,或者字符b,或字符c的一个
字符类:[^abc]
含义:代表的是除了 a、b 或 c以外的任何字符
例如:匹配规则为”[^abc]”,那么需要匹配的内容就是不是字符a,或者不是字符b,或不是字符c的任意一个字符
字符类:[a-zA-Z]
含义:代表的是a 到 z 或 A 到 Z,两头的字母包括在内
例如:匹配规则为”[a-zA-Z]”,那么需要匹配的是一个大写或者小写字母
字符类:[0-9]
含义:代表的是 0到9数字,两头的数字包括在内
例如:匹配规则为”[0-9]”,那么需要匹配的是一个数字
字符类:[a-zA-Z_0-9]
含义:代表的字母或者数字或者下划线(即单词字符)
例如:匹配规则为” [a-zA-Z_0-9] “,那么需要匹配的是一个字母或者是一个数字或一个下滑线
预定义字符类:.
含义:代表的是任何字符
例如:匹配规则为” . “,那么需要匹配的是一个任意字符。如果,就想使用 . 的话,使用匹配规则”\.”来实现
预定义字符类:\d
含义:代表的是 0到9数字,两头的数字包括在内,相当于[0-9]
例如:匹配规则为”\d “,那么需要匹配的是一个数字
预定义字符类:\w
含义:代表的字母或者数字或者下划线(即单词字符),相当于[a-zA-Z_0-9]
例如:匹配规则为”\w “,,那么需要匹配的是一个字母或者是一个数字或一个下滑线
边界匹配器:^
含义:代表的是行的开头
例如:匹配规则为^[abc][0-9]$ ,那么需要匹配的内容从[abc]这个位置开始, 相当于左双引号
边界匹配器: ,那么需要匹配的内容以[0-9]这个结束, 相当于右双引号
边界匹配器:\b
含义:代表的是单词边界
例如:匹配规则为”\b[abc]\b” ,那么代表的是字母a或b或c的左右两边需要的是非单词字符([a-zA-Z_0-9])
数量词:X?
含义:代表的是X出现一次或一次也没有
例如:匹配规则为”a?”,那么需要匹配的内容是一个字符a,或者一个a都没有
数量词:X*
含义:代表的是X出现零次或多次
例如:匹配规则为”a*” ,那么需要匹配的内容是多个字符a,或者一个a都没有
数量词:X+
含义:代表的是X出现一次或多次
例如:匹配规则为”a+”,那么需要匹配的内容是多个字符a,或者一个a
数量词:X{n}
含义:代表的是X出现恰好 n 次
例如:匹配规则为”a{5}”,那么需要匹配的内容是5个字符a
数量词:X{n,}
含义:代表的是X出现至少 n 次
例如:匹配规则为”a{5, }”,那么需要匹配的内容是最少有5个字符a
数量词:X{n,m}
含义:代表的是X出现至少 n 次,但是不超过 m 次
例如:匹配规则为”a{5,8}”,那么需要匹配的内容是有5个字符a 到 8个字符a之间
自动装箱、自动拆箱
这是 JDK1.5 后的新特性,方便了 基本数据类型 和 对应的引用类型直接运算。
装箱:基本类型 –> 引用类型
拆箱:引用类型 –> 基本类型
“`
/*
* 关于自动装箱和拆箱一些题目
*/
public static void function_2(){
Integer i = new Integer(1);
Integer j = new Integer(1);
System.out.println(i==j);// false 对象地址
System.out.println(i.equals(j));// true 继承Object重写equals,比较的对象数据
System.out.println("===================");
Integer a = 500; // Integer a = new Integer(500); 自动装箱
Integer b = 500; // Integer a = new Integer(500);
System.out.println(a==b);//false
System.out.println(a.equals(b));//true
System.out.println("===================");
//数据在byte范围内,JVM不会从新new对象
Integer aa = 127; // Integer aa = new Integer(127)
Integer bb = 127; // Integer bb = aa;
System.out.println(aa==bb); //true
System.out.println(aa.equals(bb));//true
}
```
finalize()
虚拟机在 GC 垃圾回收时,会调用 对应类的 finalize()方法
public void finalize(){}
大数据运算
BigInteger 适用于可能超出 long 范围的整数,注意,这里是对象。四则运算都要调用对应的方法实现,不能使用运算符号了。
BigDecimal 在计算机二进制中,表示浮点数不精确,所以会存在计算结果不准确的现象。eg:0.09+0.01=0.0999999… 。
Java 中提供了 BigDecimal 来实现 高精度的浮点运算。
add +
substract -
multiply *
divide /
但是要注意 BigDecimal 在做 除法时,如果出现了无限小数就会报错。应对办法,设定要保留的位数,以及保留的模式。/*
* BigDecimal实现除法运算
* divide(BigDecimal divisor, int scale, int roundingMode)
* int scale : 保留几位小数
* int roundingMode : 保留模式
* 保留模式 阅读API文档
* static int ROUND_UP 向上+1
* static int ROUND_DOWN 直接舍去
* static int ROUND_HALF_UP >= 0.5 向上+1
* static int ROUND_HALF_DOWN > 0.5 向上+1 ,否则直接舍去
*/
public static void function_1(){
BigDecimal b1 = new BigDecimal(“1.0301”);
BigDecimal b2 = new BigDecimal(“100”);
//计算b1/b2的商,调用方法divied
BigDecimal bigDiv = b1.divide(b2,2,BigDecimal.ROUND_HALF_UP);//0.01301
System.out.println(bigDiv);
}
集合继承关系图
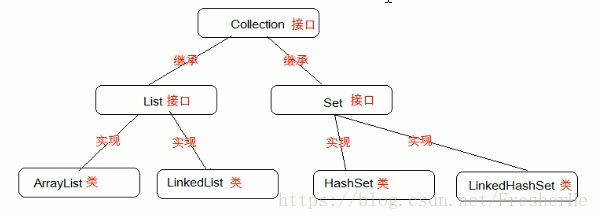
List集合的特点:
1、存储顺序有序
2、有索引,方便准确的操作元素
3、可以存储重复的元素
Set集合的特点:
1、存储顺序无序
2、无索引,遍历方式包括:迭代器、增强for
3、不能存储重复的元素(通过 equals 方法)
4、Set集合的底层实现 实际上是 Map集合
JDK1.5 新特性
1、增强 for 循环
在 JDK1.5 之后,出现了新的接口 java.lang.Iterable
Collection 接口 开始继承 自 Iterable
Iterable接口的作用:实现了该接口的实现类,都可以使用增强 for 循环
2、泛型
Java在 JDK1.5之后,提供了一个安全机制 – 泛型。严格的讲,这是一个伪泛型,因为只在编译期间有效。
泛型的通配符:?
泛型的限定符:
1、? extends Employee:表示允许 Employee以及它的子类
2、? super Employee: 表示允许 Employee 以及它的父类3、静态导入,减少开发代码量
格式:import static java.util.Arrays.sort; //注意,最后一个必须是静态成员
调用:Arrays.sort(xx); ——> sort(xx);4、方法的可变参数:本质是一个数组
前提:方法可变参数的数据类型确定
可变参数语法:数据类型…变量名
注意事项:
1、一个方法中,可变参数只能有一个
2、可变参数,必须写在参数列表的最后一位
迭代器的并发修改异常
迭代器在遍历的时候,不能改变被遍历对象的长度。否则,会抛出并发修改异常。
因为增强 for 底层实现也是迭代器,所以也不能在遍历的时候,修改被遍历对象的长度。
数据的存储结构
栈(先进后出)、数组(查询快,增删慢)、队列(先进先出)、链表(查询按,增删快)
ArrayList
ArrayList 底层实现本质是可变长的 数组(默认长度为10)。
特点:
1、线程不同步,运行快
2、查询快,增删慢(在项目中,一定要考虑到这个效率的问题)
可以存储包括 null 在内的所有元素。
LinkedList
LinkedList 本质是一个链表,所以 查询慢,增删快。
特点:
1、线程不同步,运行快
2、查询慢,增删快
3、提供了大量的首尾操作的方法
可以存储包括 null 在内的所有元素。
Vector
Vector 底层实现本质是可变长的 数组。
线程同步,运行较慢。一般不使用。
字符串 哈希值获取源码分析
Object 有 hashCode() 方法,每次运行结果不可预测。
String 类重写了 父类的 hashCode() 方法,原理如下:

哈希表的数据结构
其实就是一个 数组链表结合体 的结构
外面是一个数组,每个数组的元素,是一个桶。就是一个链表的结构,里面存放的是有相同的 hashCode 值的元素。
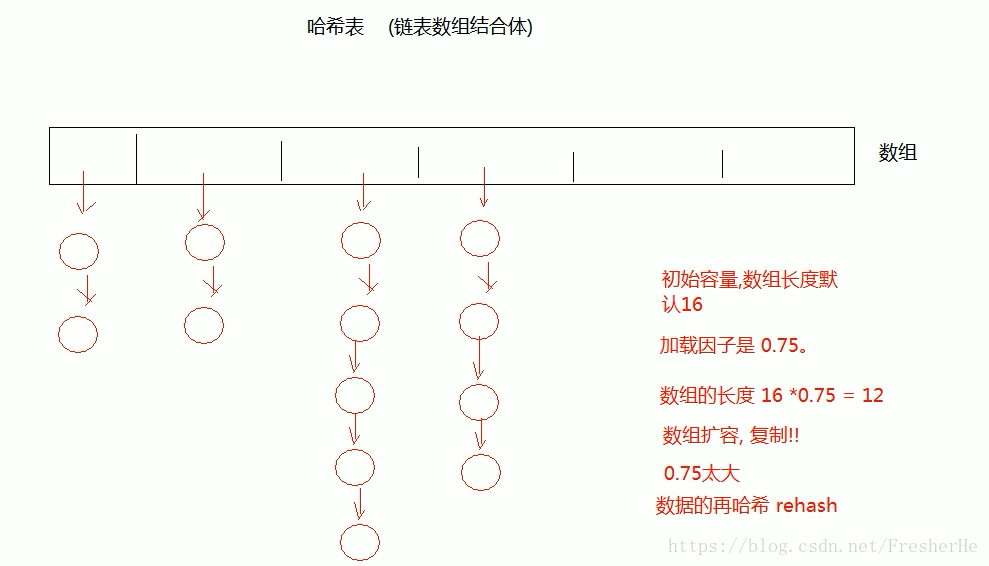
哈希表的存储过程
当存储对象时,先获取该对象的 hashCode 的值,看集合中是否存在?
如果存在,就通过 equals 方法,比较是否相同?如果相同,就PASS;
如果不同,就以桶的方式存储在有相同 hashCode 值的索引下。如果不存在,也通过equals 方法,比较是否相同?
如果不同,就添加到集合中。
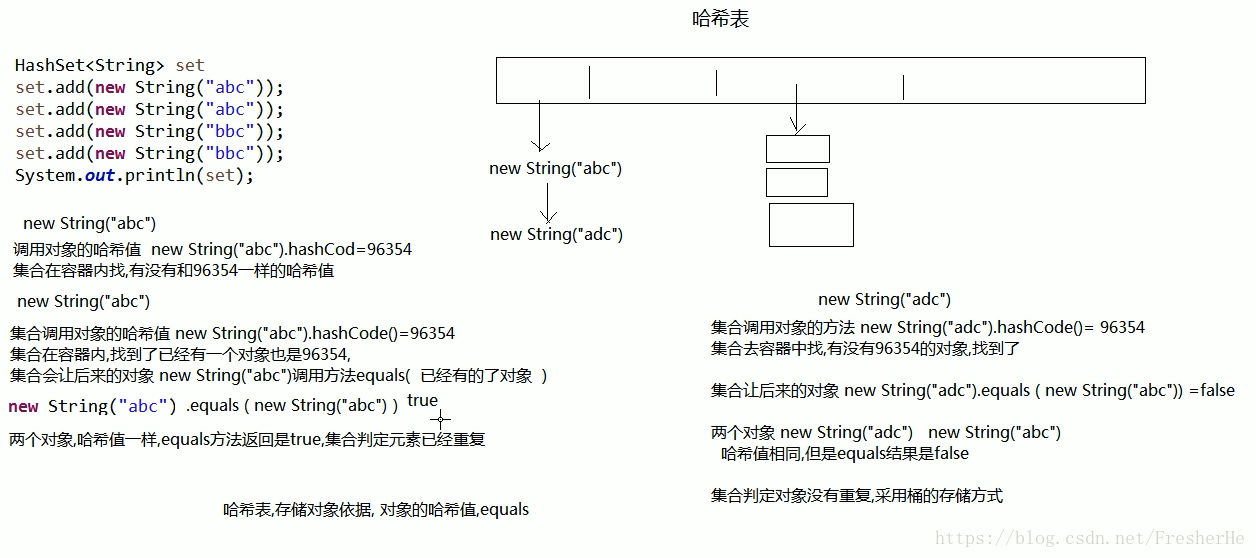
关于 hashCode() 和 equals() 面试题
题目:两个对象 Person p1 p2
如果两个对象的哈希值相同 p1.hashCode() == p2.hashCode()
两个对象的 equals() 一定返回 true 吗? p1.equals(p2) 一定是true吗?答案:不一定
如果两个对象的 equals() 返回true, p1.equals(p2) == true
两个对象的 哈希值一定相同吗?答案:一定
这个和 sun 公司的协定有关!
HashSet
HashSet 的底层实际是 HashMap。
特点:
无序集合,存取无序
没有索引
不存储重复元素
线程不安全
注意:在存储自定义对象时,要重写 hashCode() 和 equals() 方法,用来让 HashSet 判断 数据是否重复的依据。
LinkedHashSet
基于链表的 哈希表实现
继承自 HashSet
特点:
具有顺序,存取顺序相同
不能存储相同元素
线程不安全
Collection 集合 与 Map集合的区别
Collection 集合是单列集合。
Map集合是双列集合,每个元素由 键和值 两部分组成。注意:Map集合中不能包含相同的 key,value可以重复。每个键只能对应一个值。
Map集合
为了保证 Map 集合 key 的唯一性。key的数据类型必须重写 hashCode() 和 equals() 方法。
当存储重复键key时,会将原有的value覆盖掉。此时,put方法会返回被覆盖的value值。一般情况下,put方法返回是null。
HashMap :存储无序
LinkedHashMap:存储有序,继承自 HashMap
集合遍历:keySet() entrySet()
目前学习的集合都是线程不安全的,运行速度快。除了 Vector 和 Hashtable。
Hashtable:底层数据结构是哈希表,特点和 HashMap一样,但是线程安全,运行速度慢。它的子类 Properties 可以和 IO 结合使用,依旧活跃在开发舞台。
HashMap 和 Hashtable 的区别
1、HashMap 线程不安全,运行速度快;Hashtable 线程安全,运行速度慢。
2、HashMap 允许存储 null 值,null键;Hashtable 不允许存储 null值,null键。
Collections工具类
有很多操作集合的方法,包括将线程不安全的集合变成线程安全的集合等功能。
异常的继承体系
Throwable
Exception:异常。可能发生在编译期,也可能是运行期。将异常处理掉,程序可以继续执行
Error:错误。发生在运行期,比如 OutOfMemoryError。必须手动修改程序Exception有一个子类,RuntimeException(运行时异常)
异常的产生过程

注意:
当我们在调用抛出异常的方法时,最好采用 try…catch…finally的方式处理。
(RuntimeException 及其子类)运行时异常的特点:
方法内部抛出的异常是运行时异常时,throw new RuntimeException() ,或者其子类。
方法的声明上,不需要throws抛出异常,调用者也不需要做处理。
设计原因:
运行异常,不能发生。但如果发生了,说明程序有问题,需要修改源代码
运行异常:一旦发生,不要处理(throws | try…catch),直接修改源码。运行异常一旦发生,后面的代码就没有执行的意义了。
继承中,子类重写父类方法时的异常处理
1、父类的方法如果抛异常,子类可以不抛,也可以抛(抛的话只能是父类抛出异常或者其子类)
2、父类的方法没有抛异常,子类也不能抛。如果子类重写方法调用了已抛异常的方法,可以直接 try…catch… 处理。
Throwable类中方法
String getMessage() 对异常信息详细描述(较简短)
String toString() 对异常信息的简短描述(较详细)
void printStackTrace() 将异常信息追加到标准的错误流(最详细)
自定义异常
自定义异常按需继承自 Exception 或者 RuntimeException,重写构造方法即可。
分隔符
目录分隔符:
Windows:; eg:path环境变量
Linux::
目录名称分隔符:
Windows:\ eg:c:\temp
Linux:/
方法的递归调用
概念:方法自己调用自己
适用于:方法中运算的主体不变,但运算时,参与运算的参数会发生变化
注意事项:
1、递归一定要有出口,不能形成死循环
2、递归次数不能过多
3、构造方法,不能递归调用
流对象构造注意事项
流对象的构造方法,可以创建文件。如果文件已经存在,直接覆盖。可以选着续写的构造区创建。
IO流
java.io.InputStream 所有字节输入流的超类
java.io.OutputStream 所有字节输出流的超类
java.io.Reader 所有字符输入流的超类
java.io.Writer 所有字符输出流的超类
注意:字符流只能操作文本文件
字符输出流注意事项
字符输出流写数据时,必须要运行一个功能,就是刷新功能 - flush()
转换流(一旦涉及到编码表,就用转换流)
java.io.OutputStreamWriter 继承 Writer 类
就是一个字符输出流,将要写出的字符通过指定的码表转给指定的字节输出流,但我们还是操作的这个转换流,输出文本文件
OutputStreamWriter 是字符通向字节的桥梁,将字符流通过指定的编码转成字节流
java.io.InputStreamReader 继承 Reader 类
就是一个字符输入流,将要读取的字节输入流通过指定的码表转成对应的字符,读取文本文件
InputStreamReader 是字节通向字符的桥梁,将字节流通过指定的编码转成字符流
缓存流
提高IO效率
BufferedOutputStream、BufferedInputStream、BufferedWriter(特有方法 newLine() 具有跨平台性)、BufferedReader(特有方法 readLine()))
Windows:换行符 –> \r\n
Linux: 换行符 –> \n
IO流的规律
明确一:要操作的数据是数据源还是数据目的。
源:InputStream Reader
目的:OutputStream Writer
先根据需求明确要读,还是要写。
明确二:要操作的数据是字节还是文本呢?
源:
字节:InputStream
文本:Reader
目的:
字节:OutputStream
文本:Writer
已经明确到了具体的体系上。
明确三:明确数据所在的具体设备。
源设备:
硬盘:文件 File开头。
内存:数组,字符串。
键盘:System.in;
网络:Socket
目的设备:
硬盘:文件 File开头。
内存:数组,字符串。
屏幕:System.out
网络:Socket
完全可以明确具体要使用哪个流对象。
明确四:是否需要额外功能呢?
额外功能:
转换吗?转换流。InputStreamReader OutputStreamWriter
高效吗?缓冲区对象。BufferedXXX
Properties类
概述:
表示一个持久的属性集。Properties可以保持在流中或从流中加载。
特点:
1、Hashtable的子类,Map 集合中的方法都可以使用;
2、该集合没有泛型,键值对的键和值都固定为 字符串;
3、它是一个可持续化的属性集;
4、有和流技术相结合的方法;具体方法可查看 API文档(注意:配置文件有特殊要求:1、文件名后缀必须是 .properties;2、文件内容必须是键值对,以=号分割。每个键值对独占一行,不需要多余的符号;3、如果要注释某行的内容,可以在行首加 #)
常用方法:
setProperty(String key,String value)
getProperty(String key);
load(InputStream in) //流对象读取文件中的键值对,保存到集合中
load(Reader r)
store(OutputStream out) //将集合中的键值对,通过流对象保存到文件中
store(Writer w, String comments) // comments 原因,建议写英文,一般不写
对象的序列化和反序列化
序列化和反序列化的类必须实现 Serializable 接口
序列化:将内存中的对象通过流的方式写到文件中 ObjectOutputStream
反序列化:通过流的方式将文件中的数据读取到内存中的对象 ObjectInputStream
注意:静态不能序列化(因为这里是对象的序列化,而静态是属于类的)
transient (瞬态)关键字:只能用于修饰成员变量,阻止成员变量进行序列化
序列化冲突问题
当一个类实现了 Serializable 接口,在编译的时候,编译器会为其生成一个 序列号。
当我们将一个类对象进行序列化后,改变了原来的源码,新编译后的序列码就和之前序列化时的不一样,就会抛出异常。
解决方案:
自定义序列号,编译器就不会计算序列号了
在成员位置:private static final long serialVersionUID = 2143213123L;
打印流
PrintStream
PrintWriter
打印流的特点:
1、此流不负责输出源,只负责数据目的
2、为其他输出流,添加功能
3、永远不会抛出 IOException;但可能抛出其他异常
打印流的自动刷新功能
条件:
1、输出的数据目的必须是流对象(OutputStream、Writer),可以传入参数true,开启。
2、必须调用println printf format 三个方法中的一个,启用自动刷新。
commons-io 工具类
Apache 提供,包括很多 IO 的工具类。如:文件夹的复制,文件判断等
本文只用于记录学习之用,同时希望能帮助到各位“初学者”。