在 JAVA 语言中有8中基本类型和一种比较特殊的类型String。这些类型为了使他们在运行过程中速度更快,更节省内存,都提供了一种常量池的概念。常量池就类似一个JAVA系统级别提供的缓存。8种基本类型的常量池都是系统协调的,String类型的常量池比较特殊,它的主要使用方法有两种:①直接使用双引号声明出来的String对象会直接存储在常量池中 ②如果不是双引号直接声明的String对象,可以使用String类提供的intern方法,intern方法会从字符串常量池中查询当前字符串是否存在,若不存在,则会将当前字符串放入常量池中。
面试的时候经常碰到这种高逼格的问题来考察我们是否真正理解了String的不可变性、String常量池的设计以及String.intern方法所做的事情,编程中也可能碰到可以利用String.intern方法来提高程序效率或者减少内存占用的情况,这些问题也就是本篇要探讨的问题。
*String类设计成不可变的初衷?
补充:String是不可改变类(基本类型的包装类都是不可改变的)的典型代表,是Immutable设计模式的典型应用,String变量一旦初始化后就不能更改,禁止改变对象的状态,从而增加共享对象的坚固性、减少对象访问的错误,同时还避免了在多线程共享时进行同步的需要。Immutable模式的实现主要有以下两个要点:
1.除了构造函数之外,不应该有其它任何函数(至少是任何public函数)修改任何成员变量。
2.任何使成员变量获得新值的函数都应该将新的值保存在新的对象中,而保持原来的对象不被修改。
①字符串常量池的需要。
字符串常量池的诞生是为了提升效率和减少内存分配,可以说我们在编程时80%的时间都用在了处理字符串上,而处理的字符串很多会出现重复的情况,正因为字符串的不可变性,常量池很容易被优化和管理。
②安全性的考虑。
字符串使用的场景如此之多,设计成不可变可以防止字符串被有意或无意的篡改,Java源码中,String类被final修饰,同时其所有属性也被final修饰,在源码中也未暴露任何修改成员变量的方法(不过,通过反射或者unsafe直接操作内存可以实现对所谓不可变String的修改)。
③作为HashMap、HashTable等hash型数据key的必要。
由于不可变的设计,jvm底层在缓存String对象时缓存其hashcode,大大提升了执行效率!
*JDK中内存划分及1.7前后变化?
内存划分为五大块儿:堆、虚拟机栈、本地方法栈、程序计数器、方法区(非堆)。
①堆:基本上所有的对象都在堆上被创建,而在栈中声明,栈中存着堆中对象的引用。
②虚拟机栈:它是线程私有的,不会出现线程安全问题,在sun公司提供的hotspot中和本地方法栈为一个栈,每次调用方法需要执行一个Frame(帧栈)的入栈到出栈的过程,每一个栈帧都有自己的局部变量表、操作数栈、返回地址和指向运行时常量池的引用。
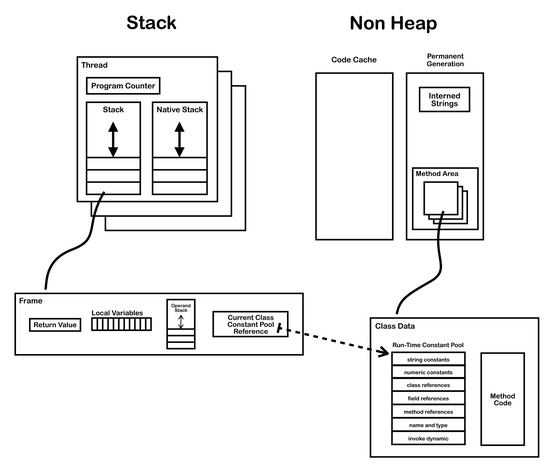
③本地方法栈:和虚拟机栈是一样的,只是里面执行的是jvm本地方法,申明为native的方法。
④程序计数器:记录了每一个线程当前执行的代码行,线程私有的。
⑤方法区(非堆):
jdk7版本:存的是类型信息,包括class被加载后的类名,属性,方法,静态变量等
jdk8版本:移除永久代,相当于把方法区变成了放在元空间中进行类的加载,静态成员变量和常量池移动至java堆中。
常量池(从jdk1.7开始放在堆里面):存的是final的值,常量,就是在编译的时候就已经确定的值。

*常量池分类?
Java的内存分配中,总共三种常量池:①字符串常量池 ②Class常量池 ③运行时常量池
**字符串常量池
存放位置:jdk1.6及之前,放在Perm Gen(即方法区)中; jdk1.7及之后,由于方法区的内存空间太小了,转移至堆中。
字符串常量池是什么:
在hotspot VM里实现的String Pool功能的是一个StringTable类,它是一个Hash表,默认长度是1009;这个StringTable在每个HotSpot VM的实例只有一份,被所有的类共享。字符串常量由一个个字符组成,放在了StringTable上。在JDK1.6中,StringTable的长度是固定的,长度就是1009,因此如果放入String Pool中的String非常多,就会造成hash冲突,导致链表过长,当调用String#intern()时会需要到链表上一个一个找,从而导致性能大幅度下降;在JDK1.7中,StringTable的长度可以通过参数指定:-XX:StringTableSize=66666.
字符串常量池存放什么:
在JDK6.0及之前版本中,String Pool里放的都是字符串常量;在JDK7.0中,由于String的intern()发生了改变,因此String Pool中也可以存放于堆内的字符串对象的引用。
**Class常量池
我们写的每一个Java类被编译后,就会形成一份class文件;class文件中除了包含类的版本、字段、方法、接口等描述信息外,还有一项信息就是常量池(constant pool table),用于存放编译器生成的各种字面量(Literal)和符号引用(Symbolic References);每个class文件都有一个class常量池。这里有人可能要问了,什么是字面量和符号引用?字面量包括:文本字符串、八种基本类型的值、被声明为final的常量等;符号引用包括:类和方法的全限定名、字段的名称和描述符、方法的名称和描述符。
**运行时常量池
运行时常量池存在于内存中,也就是class常量池被加载到内存之后的版本,不同之处是:它的字面量可以动态的添加(String#intern()),符号引用可以被解析为直接引用。
JVM在执行某个类的时候,必须经过加载、连接、初始化,而连接又包括验证、准备、解析三个阶段。而当类加载到内存中后,jvm就会将class常量池中的内容存放到运行时常量池中,由此可知,运行时常量池也是每个类都有一个。在解析阶段,会把符号引用替换为直接引用,解析的过程会去查询字符串常量池,也就是我们上面所说的StringTable,以保证运行时常量池所引用的字符串与字符串常量池中是一致的。
*关于JDK1.7及之后的String内存分配(常量池)?
例1:
String s1 = new String("aaa") ; //新建一个字符串对象s1,并在常量池放入字符串"aaa"
//(s1指向新建的对象,常量池中的"aaa"只不过是String在创建时发现常量池中没有,捎带创建的~)
String s2 = s1.intern() ; //将s1对应的值从常量池中取出并赋值给s2(intern()方法返回对象的常量池位置)
String s3 = "aaa" ; //s3在常量池中找到"aaa",并将自己指向常量池中的"aaa"
System.out.println(s1 == s2) ; //false
System.out.println(s2 == s3) ; //true内存中:

String类通过new操作产生一个字符串("aaa")时,会先去常量池中查找是否有"aaa"对象,如果没有则在常量池中创建一个此字符串对象,然后堆中再创建一个常量池中此"aaa"对象的拷贝对象,所以,对于String str=new String("aaa"),如果常量池中原来没有"aaa"则产生两个对象(堆中和堆中的常量池各一个),否则产生一个对象。
而对于基础类型的变量和常量,变量和引用存储在栈中,常量存储在常量池中。
例2:
String s1 = new String("A")+new String("A");//在堆中创建了两个A对象,并在创建时捎带在常量池放入了一个A,第二个对象发现常量池里有A了之后便不会创建了。
String s2 = s1.intern(); //此时s1=s2
String s3 = "AA";
System.out.println(s2==s3); //true
System.out.println(s1==s3); //true
分析:
第一句中new出来的两个对象是被+号连接起来的,所以“AA”并不是创建(new)的对象,所以人家并不会去瞄常量池,自然不会捎带创建常量“AA”了。
至于s2和s3可以参考下面这段解释:
s2问s1:“请问在你这工作的AA小姐姐家住哪里呀?” s1冷漠地说:“她没有家”。
s2去找AA的常量池地址,可人家偏偏没有。没有怎么办?在居民区公告下AA住单位吧。 于是就在常量池留了个AA对象的地址,想找AA的都去AA对象里找。
java嫌麻烦,于是在编译阶段会让s2直接指向AA对象,这样s1和s2就相等了。
s3依然没问s1,我行我素去了居民区想直接找到AA小姐姐,却看到公告牌(地址)指向了AA对象。没办法,去对象区找AA吧。于是java在编译期又把s3指向了AA对象。
### 注意:常量池放地址的特性只有在jdk1.8才有,1.7及以前是没有的! 在jdk1.7时常量池才移入堆中,之前1.6的版本常量池是在方法区(永久带)中的。
常量池放地址的原因是创建超长字符串时,如果在常量池和堆中各放一份就显得有些浪费了,于是干脆在常量池中放地址,节省空间!
*String.intern方法所做的事情?
推荐参看——String的intern方法详解(有些点我也有点不是太明白),抽出下面几点易于理解的:
Java中String的intern方法的部分源码:
/** @return a string that has the same contents as this string, but is
* guaranteed to be from a pool of unique strings.
*/
public native String intern(); intern方法是一个 native 的方法,英文注释写的非常明了——“如果常量池中存在当前字符串, 就会直接返回当前字符串. 如果常量池中没有此字符串, 会将此字符串放入常量池中后, 再返回”。
jdk7 版本对 intern 操作和常量池都做了一定的修改。主要包括2点:
- 将String常量池从Perm区移动到了Java Heap区
- 使用intern方法时,如果存在堆中的对象,会直接保存对象的引用,而不会重新创建对象。
对于什么时候会在常量池存储字符串对象,我想我们可以基本得出结论:
1. 显示调用String的intern方法的时候;
2. 直接声明字符串字面常量的时候,例如: String a = "aaa";
3. 字符串直接常量相加的时候,例如: String c = "aa" + "bb", 其中的aa/bb只要有任何一个不是字符串字面常量形式,都不会在常量池生成"aabb",且此时jvm做了优化,不会同时生成"aa"和"bb"在字符串常量池中,会在常量池中直接生成“aabb”;String c = new String("aa") + String("bb");c.intern();会在常量池中同时生成“aa”和“bb”;