一、前言
学习计算机知识也这么久了,在数据结构的学习中也对栈和堆这2种数据结构有一定了解。什么栈是FILO啊,最大堆、最小堆啊,但是每当看到书中说什么栈内存、堆内存、堆栈,就会一脸蒙逼,因此这回总算是下定决心好好深入了解下这个概念了。也就是操作系统中的栈和堆。(OS中的栈、堆与DS中的栈、堆不一样)
二、概念区分
操作系统中三个常常遇到的概念,栈、堆、堆栈。那么这三个概念到底是什么鬼?先简单的说下,然后再按C和Java的情况细说
栈区:Stack
- 分配方式:由系统自动分配
- 存储顺序:有顺序,先进后出的形式,逐一压栈
- 与数据结构中的栈的关系:类似于DS中的栈,同样的特性(都写说的是类似,我看就是一样的,同样的特性,同样的出栈、入栈方式,同样的栈顶指针….)
堆区:heap
- 分配方式:由程序员向OS申请
- 存储顺序:无序,任意顺序
- 与DB中的堆的关系:与DB中的堆不一样,分配方式倒是类似于链表
堆栈
这个是最蛋疼的,最让我困惑的。栈是栈,堆就是堆,哪来的一个堆栈?然后百度堆栈,总是分开谈,要么就是直接使用堆栈这个词。很郁闷。
查了很久,才发现,堆栈其实就是栈嘛,它的英文名称就是Stack,也是压栈、入栈、栈顶指针、FIFO的描述。一样的存储引用变量的特性。—>我觉得这丫的就是栈
三、C/C++中情况
以C++中的内存分配来说说栈和堆。C中的内存分配分为5种内存区域。分别是:栈区、堆区、全局区(也叫静态区)、常量区、代码区
简述
- 栈区:分配方式、存放顺序以及与DB中栈的关系还是上面说的。现在说下C中栈区存放的数据。存放的数据:栈区用于存放函数的参数值,局部变量值等
- 堆区:存放的数据:存放 new 函数声明的对象
- 静态区:存储全局变量和静态变量。全局初始化变量和全局未初始化变量是两块相邻的区域
- 常量区:存放常量
- 代码区:存放函数的二进制代码
代码示例
以 demo.c 来分析一下变量的存放区域。

int a = 0; // 是初始化的全局变量, 存储在全局初始化区
char *p1; // 指针变量 p1 是未初始化的全局变量,存储在全局未初始化区
int main() {
int b; // 是局部变量,存放在栈
char s[] = "abc"; // 是局部变量,存放于栈, 字符串"abc/0"存放在常量区
char *p2; // 指针变量 p2 是局部变量, 存放于栈
char *p3 = "123456"; // 指针变量 p3 是是局部变量,存放于栈,字符串"123456/0"在常量区
static int c =0; // 是初试化的静态变量,存放于静态初始化区
p1 = (char *) malloc(10); // 程序员手动分配了10byte的内存,该内存是在堆上申请的
p2 = (char *) malloc(20); // 程序员手动分配了20byte的内存,该内存是在堆上申请的
strcpy(p1, "123456"); // 函数参数“123456/0”是字符串常量,存放于常量区,编译器可能会将它与p3所指向的"123456"优化成一个地方。
return 0;
}
四、Java中的情况
Java中的内存分配区分为6种,与C/C++不同的2个地方就是多了一个寄存器区以及代码区存放的是硬盘中的源程序代码。
简单叙述
先简单说下Java 中的栈内存、堆内存
[栈]
1. Java 中,栈用于存放基本数据类型及对象变量的引用
2. 一个很重要的特殊性,就是存在栈中的数据可以共享
3. 对象本身不存放于栈中,而是存放在堆中
4. 每定义一个变量时,Java就在栈中为该变量分配内存空间
5. 栈中存放的变量在运行到作用域外,其占用的内存会被回收
[堆]
1. 堆用于存放 new 操作符产生的对象和数组
2. 堆中的对象,程序运行在其作用域外,其所占内存也不会被马上回收
3. 缺点:向OS请求内存分配和内存的销毁都是十分耗时的操作,效率较低
4. 优点:编译器不必知道要从堆里分配多少存储空间,也不必知道存储的数据要在堆里停留多长的时间, 堆的保存数据的灵活性更大
详细叙述
从上面的简单叙述来看,还是很难理解(我在看到这些叙述时,就还是很困惑),会有几个问题。
Q1:既然对象和数组是存放在堆中的,为什么每定义一个变量时,Java就在栈中为该变量分配内存空间?
A1: 确实对象和数组是存放在堆中的,但是在堆中产生了一个数组或者对象后,我们也还可以在栈中定义一个特殊的变量,即引用变量。引用变量相当于为数组或者对象起的一个别名,以后就可以在程序中使用栈内存中的引用变量来访问堆中的数组或者对象。所以,栈中的变量指向堆内存中的变量,栈中的变量其实就是Java中的指针。
[例子]
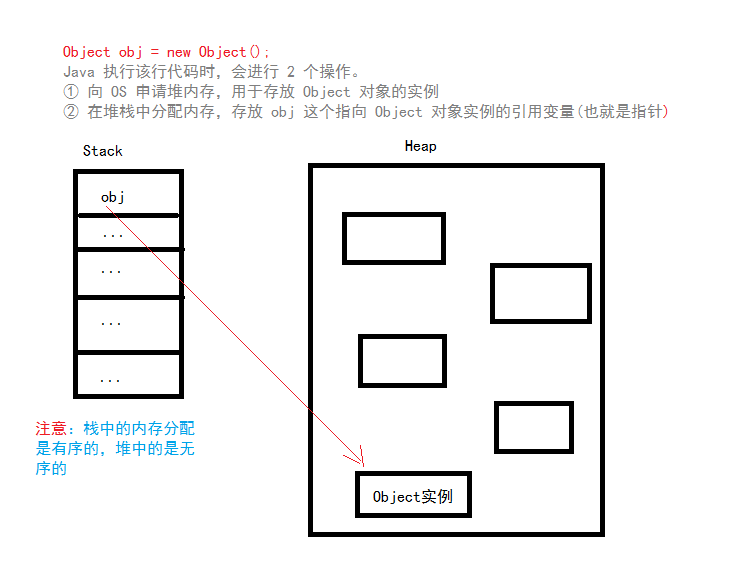
Java中所有对象的存储空间都是在堆中分配的,但是这个对象的引用却是在堆栈中分配,也就是说在建立一个对象时从两个地方都分配内存,在堆中分配的内存实际建立这个对象,而在堆栈中分配的内存只是一个指向这个堆对象的指针(引用)而已。
Q2:为什么堆中的对象在程序运行在作用域外不会立即回收,而栈中的变量却会被立即回收?
A2:栈使用的是一级缓存, 他们通常都是被调用时处于存储空间中,调用完毕立即释放。堆则是存放在二级缓存中,生命周期由虚拟机的垃圾回收算法来决定。堆的变量离开 new 的代码块时,其内存不会被释放,只有没有引用变量指向它时,才会被当作垃圾,不能再被使用,但是仍然占着内存,由GC在不确定的时间回收—>这个也是java比较占内存的主要原因
Q3:为什么栈区变量存储是有序的,而堆是无序的,任意顺序的?
A3:从编译原理的要求来说,栈式存储分配要求在过程的入口处必须知道所有的存储要求,而堆式存储分配则专门负责在编译时或运行时模块入口处都无法确定存储要求的数据结构的内存分配,比如可变长度串和对象实例。因此堆由大片的可利用块或空闲块组成,其中的内存可以按照任意顺序分配和释放.
Q4:栈中的数据共享特性是什么意思?
A4: 我们知道 Java 中的 ”==“操作符是比较变量的引用是否相等的。因此我们可以使用该操作符来进行验证数据共享特性
public static void main(String[] args) {
int a = 3;
int b = 3;
System.out.println(a == b); // true
String s1 = "hello";
String s2 = "hello";
System.out.println(s1 == s2); // true
a = a + 1;
System.out.println(a == b); // false
}
从以上的简单案例,我们可以分析:这些基本数据类型变量是存在栈中的。首先栈中是没有3这个值的,当给 a 赋值为 3 时,JVM 会在栈中查询是否有该值,发现没有,那么就开辟一个空间给 a,用于存放a的值3,然后变量 a 就指向存储 3 的地址空间。当第二次初始化变量 b 为 3 时,jvm 扫描栈中的情况,发现栈中是有 3 的,就会将 b 也给指向 3 的地址空间。所以比较 a、b 的引用时,会返回 true。同理 s1 和 s2 也是一样。
再接着,我们给 a 加上 1,其值变为 4,然后该值要存入栈内。jvm 再次扫描栈内信息,发现此时栈内没有一个空间存放 4 的值,就会另辟一个空间存储值 4,然后让 a 重新指向存储 4 的地址空间。因此我们再次比较 a、b的引用时,会返回 false。
[注:这个和对象的”别名现象“不是同一个情况]
五、小结
记住以下几句话就行:
1. 堆主要用来存放对象的,栈主要是用来执行程序的.
2. 初始化一个对象时,会进行2个内存分配操作:在堆中分配内存,存放对象的实例。在栈中分配内存,存放指向实例的引用变量
前往 bascker/javaworld 获取更多 Java 知识