文章目录
五、归档和备份
# 压缩程序
gzip – 压缩或者展开文件
bzip2 – 块排序文件压缩器
# 归档程序
tar – 磁带打包工具
zip – 打包和压缩文件
# 文件同步程序
rsync – 同步远端文件和目录
压缩文件
压缩算法:无损压缩保留了 原始文件的所有数据;有损压缩,执行压缩操作时会删除数据,允许更大的压缩。gzip/gunzip:
alien@localhost:~ $ ls -l /etc > foo.txt
alien@localhost:~ $ ls -l foo.*
-rw-rw-r-- 1 alien alien 14700 9月 20 08:36 foo.txt
alien@localhost:~ $ gzip foo.txt
alien@localhost:~ $ ls -l foo.*
-rw-rw-r-- 1 alien alien 2877 9月 20 08:36 foo.txt.gz
alien@localhost:~ $ gunzip foo.txt.gz
alien@localhost:~ $ ls -l foo.*
-rw-rw-r-- 1 alien alien 14700 9月 20 08:36 foo.txt
gzip 选项:
| 选项 | 说明 |
|---|---|
| -c | 把输出写入到标准输出,并且保留原始文件。也有可能用–stdout 和–to-stdout 选项来指定。 |
| -d | 解压缩。正如 gunzip 命令一样。也可以用–decompress 或者–uncompress 选项来指定. |
| -f | 强制压缩,即使原始文件的压缩文件已经存在了,也要执行。也可以用–force 选项来指定。 |
| -h | 显示用法信息。也可用–help 选项来指定。 |
| -l | 列出每个被压缩文件的压缩数据。也可用–list 选项。 |
| -r | 若命令的一个或多个参数是目录,则递归地压缩目录中的文件。也可用–recursive 选项来指定。 |
| -t | 测试压缩文件的完整性。也可用–test 选项来指定。 |
| -v | 显示压缩过程中的信息。也可用–verbose 选项来指定。 |
| -number | 设置压缩指数。number 是一个在1(最快,最小压缩)到9(最慢,最大压缩)之间的整数。 数值1和9也可以各自用–fast 和–best 选项来表示。默认值是整数6。 |
alien@localhost:~ $ ls -l /etc | gzip > foo.txt.gz
# 没有必要指定.gz
alien@localhost:~ $ gunzip foo.txt
alien@localhost:~ $ ls -l foo.txt
-rw-rw-r-- 1 alien alien 14700 9月 20 08:43 foo.txt
# 查看压缩文件内容
alien@localhost:~ $ ls -l /etc | gzip > foo.txt.gz
alien@localhost:~ $ gunzip -c foo.txt | less
alien@localhost:~ $ ls
bin foo.txt.gz 公共的 模板 视频 图片 文档 下载 音乐 桌面
# 与上面有同等作用
alien@localhost:~ $ zcat foo.txt.gz | less
# 等同于上面的语句
alien@localhost:~ $ zless foo.txt.gz
bzip2:
与 gzip 程序相似,但是使用了不同的压缩算法, 舍弃了压缩速度,而实现了更高的压缩级别。
如果你再次压缩已经压缩过的文件,实际上你 会得到一个更大的文件。这是因为所有的压缩技术都会涉及一些开销,文件中会被添加描述 此次压缩过程的信息。
归档文件
**tar:**扩展名为 .tar 或者 .tgz 的文件,它们各自表示“普通” 的 tar 包和被 gzip 程序压缩过的 tar 包
tar mode[options] pathname...
tar 模式:
| 模式 | 说明 |
|---|---|
| c | 为文件和/或目录列表创建归档文件。 |
| x | 抽取归档文件。 |
| r | 追加具体的路径到归档文件的末尾。 |
| t | 列出归档文件的内容。 |
alien@localhost:~ $ mkdir -p playground/dir-{00{1..9},0{10..99},100}
alien@localhost:~ $ touch playground/dir-{00{1..9},0{10..99},100}/file-{A..Z}
# 模式和选项可以写在一起,而且不 需要开头的短横线。
alien@localhost:~ $ tar cf playground.tar playground
alien@localhost:~ $ tar tvf playground.tar
drwxrwxr-x alien/alien 0 2018-09-20 09:01 playground/
drwxrwxr-x alien/alien 0 2018-09-20 09:01 playground/dir-051/
-rw-rw-r-- alien/alien 0 2018-09-20 09:01 playground/dir-051/file-K
...
# 抽取tar包到foo文件夹
alien@localhost:~ $ mkdir foo
alien@localhost:~ $ cd foo
# 类似于压缩
alien@localhost:~/foo $ tar xf ../playground.tar
alien@localhost:~/foo $ ls
playground
在现代 Linux 系统中, USB硬盘会被“自动地”挂载到 /media 目录下。我们也假定硬盘中有一个名为 BigDisk 的逻辑卷。 为了打包家目录文件,可以制作 tar 包
# 打包文件
sudo tar cf /media/BigDisk/home.tar /home
# 抽取文件
cd /
sudo tar xf /media/BigDisk/home.tar
# 抽取单个文件
sudo tar xf archive.tar pathname
tar 命令经常结合 find 命令一起来制作归档文件:

alien@localhost:~ $ mkdir -p playground/dir-{00{1..9},0{10..99},100}
alien@localhost:~ $ touch playground/dir-{00{1..9},0{10..99},100}/file-{A..Z}
alien@localhost:~ $ find playground -name 'file-A' -exec tar rf playground.tar '{}' '+'
alien@localhost:~ $ ls
bin playground.tar 模板 图片 下载 桌面
playground 公共的 视频 文档 音乐
find 命令来匹配 playground 目录中所有名为 file-A 的文件,然后使用-exec 行为,来 唤醒带有追加模式(r)的 tar 命令,把匹配的文件添加到归档文件 playground.tar 里面。
alien@localhost:~ $ find playground -name 'file-A' | tar cf - --files-from=- | gzip > playground.tgz
alien@localhost:~ $ ls
bin playground playground.tar playground.tgz 公共的 模板 视频 图片 文档 下载 音乐 桌面
–file-from 选项(也可以用 -T 来指定) 导致 tar 命令从一个文件而不是命令行来读入它的路径名列表。现在的 GUN 版本的 tar 命令 ,gzip 和 bzip2 压缩两者都直接支持,各自使用 z 和 j 选项,上述命令简化为:
find playground -name 'file-A' | tar czf playground.tgz -T -
# 创建一个由 bzip2 压缩的归档文件
find playground -name 'file-A' | tar cjf playground.tbz -T -
把远端remote-sys主机下的`Documents`文件夹打包到本地系统
ssh remote-sys 'tar cf - Documents' | tar xf -
zip:
zip options zipfile file...
alien@localhost:~ $ zip -r playground.zip playground
adding: playground/ (stored 0%)
adding: playground/dir-051/ (stored 0%)
adding: playground/dir-051/file-K (stored 0%)
...
alien@localhost:~ $ ls
bin playground.tar playground.zip 模板 图片 下载 桌面
playground playground.tgz 公共的 视频 文档 音乐
使用-l 选项,导致 unzip 命令只是列出文件包中的内容而没有抽取文件。添加这个-v 选项会增加列表的冗余信息。
# 利用管道
alien@localhost:~ $ find playground -name "file-A" | zip -@ file-A.zip
adding: playground/dir-051/file-A (stored 0%)
adding: playground/dir-007/file-A (stored 0%)
adding: playground/dir-092/file-A (stored 0%)
unzip 程序,不接受标准输入。
# 与tar一样,zip 命令把末尾的横杠解释为 “使用标准输入作为输入文件。”
alien@localhost:~ $ ls -l /etc/ | zip ls-etc.zip -
adding: - (deflated 81%)
同步文件和目录
通过使用 rsync 远端更新协议,此协议 允许 rsync 快速地检测两个目录的差异,执行最小量的复制来达到目录间的同步。
rsync options source destination
source 和 destination 两者之一必须是本地文件。rsync 不支持远端到远端的复制。source 和 destination 是下列选项之一:
- 一个本地文件或目录
- 一个远端文件或目录,以[user@]host:path 的形式存在
- 一个远端 rsync 服务器,由 rsync://[user@]host[:port]/path 指定
# -a 选项(递归和保护文件属性)和-v 选项(冗余输出)
rsync -av playground foo
在网络间使用 rsync 命令
# 备份本地文件到远端
sudo rsync -av --delete --rsh=ssh /etc /home /usr/local remote-sys:/backup
# 同步远端文件到本地
rsync -av -delete rsync://rsync.gtlib.gatech.edu/fedora-linux-core/development/i386/os fedora-devel
六、正则表达式
grep
grep [options] regex [file...],grep 程序会在文本文件中查找一个指定的正则表达式,并把匹配行输出到标准输出。
grep选项:
| 选项 | 描述 |
|---|---|
| -i | 忽略大小写。不会区分大小写字符。也可用–ignore-case 来指定。 |
| -v | 不匹配。通常,grep 程序会打印包含匹配项的文本行。这个选项导致 grep 程序只会打印不包含匹配项的文本行。也可用–invert-match 来指定。 |
| -c | 打印匹配的数量(或者是不匹配的数目,若指定了-v 选项),而不是文本行本身。 也可用–count 选项来指定。 |
| -l | 打印包含匹配项的文件名,而不是文本行本身,也可用–files-with-matches 选项来指定。 |
| -L | 相似于-l 选项,但是只是打印不包含匹配项的文件名。也可用–files-without-match 来指定。 |
| -n | 在每个匹配行之前打印出其位于文件中的相应行号。也可用–line-number 选项来指定。 |
| -h | 应用于多文件搜索,不输出文件名。也可用–no-filename 选项来指定。 |
alien@localhost:~ $ ls /bin > dirlist-bin.txt
alien@localhost:~ $ ls /usr/bin > dirlist-usr-bin.txt
alien@localhost:~ $ ls /sbin > dirlist-sbin.txt
alien@localhost:~ $ ls /usr/sbin > dirlist-usr-sbin.txt
alien@localhost:~ $ ls dirlist*.txt
dirlist-bin.txt dirlist-sbin.txt dirlist-usr-bin.txt dirlist-usr-sbin.txt
# 搜索所列文件中的
alien@localhost:~ $ grep bzip dirlist*.txt
dirlist-bin.txt:bzip2
dirlist-bin.txt:bzip2recover
alien@localhost:~ $ grep -l bzip dirlist*.txt
dirlist-bin.txt
# 查看不包含匹配项的文件列表
alien@localhost:~ $ grep -L bzip dirlist*.txt
dirlist-sbin.txt
dirlist-usr-bin.txt
dirlist-usr-sbin.txt
元字符:^ $ . [ ] { } - ? * + ( ) | \,可以把元字符用引号引起来阻止 shell 试图展开它们
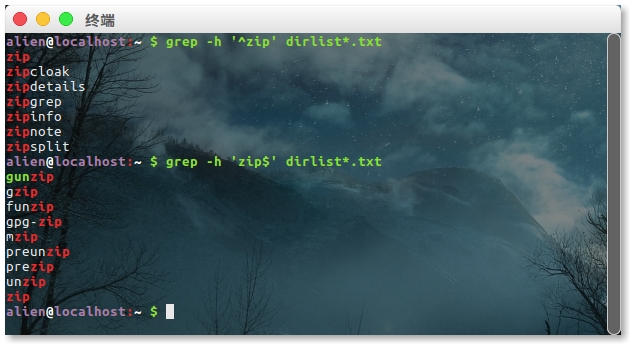
插入符号和美元符号被看作是锚点,^匹配开头,$匹配尾部。
# 在我们的字典文件中查找到包含五个字母,且第三个字母 是“j”,最后一个字母是“r”的所有单词
alien@localhost:~ $ grep -i '^..j.r$' /usr/share/dict/words
Major
major
POSIX 字符集
posix标准引入了”locale”概念,它能针对不同地区选择合适的字符集。:
| 字符集 | 说明 |
|---|---|
| [:alnum:] | 字母数字字符。在 ASCII 中,等价于:[A-Za-z0-9] |
| [:word:] | 与[:alnum:]相同, 但增加了下划线字符。 |
| [:alpha:] | 字母字符。在 ASCII 中,等价于:[A-Za-z] |
| [:blank:] | 包含空格和 tab 字符。 |
| [:cntrl:] | ASCII 的控制码。包含了0到31,和127的 ASCII 字符。 |
| [:digit:] | 数字0到9 |
| [:graph:] | 可视字符。在 ASCII 中,它包含33到126的字符。 |
| [:lower:] | 小写字母。 |
| [:punct:] | 标点符号字符。在 ASCII 中,等价于:[-!"#$%&’()*+,./:;<=>?@[\]_`{|}~] |
| [:print:] | 可打印的字符。在[:graph:]中的所有字符,再加上空格字符。 |
| [:space:] | 空白字符,包括空格、tab、回车、换行、vertical tab 和 form feed.在 ASCII 中, 等价于:[ \t\r\n\v\f] |
| [:upper:] | 大写字母。 |
| [:xdigit:] | 用来表示十六进制数字的字符。在 ASCII 中,等价于:[0-9A-Fa-f] |
七、文本处理
cat – 连接文件并且打印到标准输出
sort – 给文本行排序
uniq – 报告或者省略重复行
cut – 从每行中删除文本区域
paste – 合并文件文本行
join – 基于某个共享字段来联合两个文件的文本行
comm – 逐行比较两个有序的文件
diff – 逐行比较文件
patch – 给原始文件打补丁
tr – 翻译或删除字符
sed – 用于筛选和转换文本的流编辑器
aspell – 交互式拼写检查器
文本应用程序
cat > foo.txt # 将输入cat重定向到foo.txt中,按CTRL+D结束
cat -ns foo.txt # 输出显示行号和禁止输出多个空白行
sort > foo.txt # 将输入sort重定向到foo.txt中,按CTRL+D结束
# 将三个文本文件合并为一个有序的文件
sort file1.txt file2.txt file3.txt > final_sorted_list.txt
常见的 sort 程序选项:
| 选项 | 长选项 | 描述 |
|---|---|---|
| -b | –ignore-leading-blanks | 默认情况下,对整行进行排序,从每行的第一个字符开始。这个选项导致 sort 程序忽略 每行开头的空格,从第一个非空白字符开始排序。 |
| -f | –ignore-case | 让排序不区分大小写。 |
| -n | –numeric-sort | 基于字符串的数值来排序。使用此选项允许根据数字值执行排序,而不是字母值。 |
| -r | –reverse | 按相反顺序排序。结果按照降序排列,而不是升序。 |
| -k | –key=field1[,field2] | 对从 field1到 field2之间的字符排序,而不是整个文本行。看下面的讨论。 |
| -m | –merge | 把每个参数看作是一个预先排好序的文件。把多个文件合并成一个排好序的文件,而没有执行额外的排序。 |
| -o | –output=file | 把排好序的输出结果发送到文件,而不是标准输出。 |
| -t | –field-separator=char | 定义域分隔字符。默认情况下,域由空格或制表符分隔。 |
# du 命令可以 确定最大的磁盘空间用户,输出结果按照路径名来排序
# head 命令,把输出结果限制为前 10 行
du -s /usr/share/* | head
# 按数值排序
du -s /usr/share/* | sort -nr | head
# 按照文件大小排序,5指第五个字段
ls -l /usr/bin | sort -nr -k 5 | head
# 对第一个字段排序,指定了 1,1, 始于并且结束于第一个字段
# 第二个实例中,我们指定了 2n,意味着第二个字段是排序的键值
sort --key=1,1 --key=2n distros.txt
# sort 程序使用一个排序键值,其始于第三个字段中的第七个字符
# n 和 r 选项来实现一个逆向的数值排序,b 选项用来删除日期字段中开头的空格
sort -k 3.7nbr -k 3.1nbr -k 3.4nbr distros.txt
# -t 选项来定义分隔符
sort -t ':' -k 7 /etc/passwd | head
uniq 会删除任意排好序的重复行(因为 uniq 只会删除相邻的重复行),并且把结果发送到标准输出。 它常常和 sort 程序一块使用,来清理重复的输出。
uniq 选项:
| 选项 | 说明 |
|---|---|
| -c | 输出所有的重复行,并且每行开头显示重复的次数。 |
| -d | 只输出重复行,而不是特有的文本行。 |
| -f n | 忽略每行开头的 n 个字段,字段之间由空格分隔,正如 sort 程序中的空格分隔符;然而, 不同于 sort 程序,uniq 没有选项来设置备用的字段分隔符。 |
| -i | 在比较文本行的时候忽略大小写。 |
| -s n | 跳过(忽略)每行开头的 n 个字符。 |
| -u | 只输出独有的文本行。这是默认的。 |
cut 程序选择项
| 选项 | 说明 |
|---|---|
| -c char_list | 从文本行中抽取由 char_list 定义的文本。这个列表可能由一个或多个逗号 分隔开的数值区间组成。 |
| -f field_list | 从文本行中抽取一个或多个由 field_list 定义的字段。这个列表可能 包括一个或多个字段,或由逗号分隔开的字段区间。 |
| -d delim_char | 当指定-f 选项之后,使用 delim_char 做为字段分隔符。默认情况下, 字段之间必须由单个 tab 字符分隔开。 |
| –complement | 抽取整个文本行,除了那些由-c 和/或-f 选项指定的文本。 |
# 抽取所有行第三个字段到标准输出
cut -f 3 distros.txt
# 抽取所有行第三个字段后,再抽取每一个字段的7-10个字符
cut -f 3 distros.txt | cut -c 7-10
# 指定了分隔符
cut -d ':' -f 1 /etc/passwd | head
paste
这个 paste 命令的功能正好与 cut 相反,会添加一个或多个文本列到文件中。
join
类似于 paste,它会往文件中添加列,通常与关系型数据库有关联。
# 不同的列项会添加到第二个file中
join distros-key-names.txt distros-key-vernums.txt | head
比较文本
comm
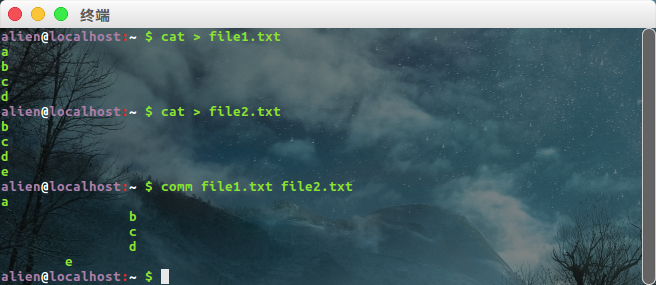
第一列包含第一个文件独有的文本行;第二列文本行是第二列独有的;第三列包含两个文件共有的文本行。comm 支持 -n 形式的选项,这里 n 代表 1,2 或 3。
# 隐藏输出结果的第1,2列
comm -12 file1.txt file2.txt
diff
软件开发员经常使用 diff 程序来检查不同程序源码 版本之间的更改,diff 能够递归地检查源码目录,经常称之为源码树。
diff 更改命令:
| 改变 | 说明 |
|---|---|
| r1ar2 | 把第二个文件中位置 r2 处的文件行添加到第一个文件中的 r1 处。 |
| r1cr2 | 用第二个文件中位置 r2 处的文本行更改(替代)位置 r1 处的文本行。 |
| r1dr2 | 删除第一个文件中位置 r1 处的文本行,这些文本行将会出现在第二个文件中位置 r2 处。 |
# 上下文模式,与github上面的一样
diff -c file1.txt file2.txt
diff 上下文模式更改指示符:
| 指示符 | 意思 |
|---|---|
| blank | 上下文显示行。它并不表示两个文件之间的差异。 |
| - | 删除行。这一行将会出现在第一个文件中,而不是第二个文件内。 |
| + | 添加行。这一行将会出现在第二个文件内,而不是第一个文件中。 |
| ! | 更改行。将会显示某个文本行的两个版本,每个版本会出现在更改组的各自部分。 |
diff 统一模式更改指示符
| 字符 | 意思 |
|---|---|
| 空格 | 两个文件都包含这一行。 |
| - | 在第一个文件中删除这一行。 |
| + | 添加这一行到第一个文件中。 |
patch
它接受从 diff 程序的输出,并且通常被用来 把较老的文件版本转变为较新的文件版本。
diff -Naur old_file new_file > diff_file
# 得到diff_file应用到旧文件中
patch < diff_file
tr
一种基于字符的查找和替换操作。
alien@localhost:~ $ echo "lowercase letters" | tr a-z A-Z
LOWERCASE LETTERS
字符集可以用三种方式来表示:
- 一个枚举列表。例如, ABCDEFGHIJKLMNOPQRSTUVWXYZ
- 一个字符域。例如,A-Z 。注意这种方法有时候面临与其它命令相同的问题,归因于 语系的排序规则,因此应该谨慎使用。
- POSIX 字符类。例如,[:upper:]
# MS-DOS 文本文件为 Unix 风格文本,每行末尾的回车符需要被删除
tr -d '\r' < dos_file > unix_file
# 使用-s 选项,tr 命令能“挤压”(删除)重复的字符实例,重复的字符必须是相邻的
alien@localhost:~ $ echo "aaabbbccc" | tr -s ab
abccc
sed
sed 的工作方式是要不给出单个编辑命令(在命令行中)要不就是包含多个命令的脚本文件名, 然后它就按行来执行这些命令。替换命令由字母 s后面跟着的字符来代表。
# 两条命令等价,将输入的文本中的front替换为back
echo "front" | sed 's_front_back_'
echo "front" | sed 's/front/back/'
# 对仅有一行文本的输入流的第一行执行替换操作
echo "front" | sed '1s/front/back/'
sed 地址表示法:
| 地址 | 说明 |
|---|---|
| n | 行号,n 是一个正整数。 |
| $ | 最后一行。 |
| /regexp/ | 所有匹配一个 POSIX 基本正则表达式的文本行。注意正则表达式通过 斜杠字符界定。选择性地,这个正则表达式可能由一个备用字符界定,通过\cregexpc 来 指定表达式,这里 c 就是一个备用的字符。 |
| addr1,addr2 | 从 addr1 到 addr2 范围内的文本行,包含地址 addr2 在内。地址可能是上述任意 单独的地址形式。 |
| first~step | 匹配由数字 first 代表的文本行,然后随后的每个在 step 间隔处的文本行。例如 1~2 是指每个位于偶数行号的文本行,5~5 则指第五行和之后每五行位置的文本行。 |
| addr1,+n | 匹配地址 addr1 和随后的 n 个文本行。 |
| addr! | 匹配所有的文本行,除了 addr 之外,addr 可能是上述任意的地址形式。 |
# 打印出一系列的文本行,开始于第一行,直到第五行
# 我们使用 p 命令, 其就是简单地把匹配的文本行打印出来
sed -n '1,5p' distros.txt
sed 基本编辑命令:
| 命令 | 说明 |
|---|---|
| = | 输出当前的行号。 |
| a | 在当前行之后追加文本。 |
| d | 删除当前行。 |
| i | 在当前行之前插入文本。 |
| p | 打印当前行。默认情况下,sed 程序打印每一行,并且只是编辑文件中匹配 指定地址的文本行。通过指定-n 选项,这个默认的行为能够被忽略。 |
| q | 退出 sed,不再处理更多的文本行。如果不指定-n 选项,输出当前行。 |
| Q | 退出 sed,不再处理更多的文本行。 |
| s/regexp/replacement/ | 只要找到一个 regexp 匹配项,就替换为 replacement 的内容。 replacement 可能包括特殊字符 &,其等价于由 regexp 匹配的文本。另外, replacement 可能包含序列 \1到 \9,其是 regexp 中相对应的子表达式的内容。更多信息,查看 下面 back references 部分的讨论。在 replacement 末尾的斜杠之后,可以指定一个 可选的标志,来修改 s 命令的行为。 |
| y/set1/set2 | 执行字符转写操作,通过把 set1 中的字符转变为相对应的 set2 中的字符。 注意不同于 tr 程序,sed 要求两个字符集合具有相同的长度。 |
# 可选标志是 g 标志,其 指示 sed 对某个文本行全范围地执行查找和替代操作
# 上边只是对第一个实例进行替换
echo "aaabbbccc" | sed 's/b/B/g'
aspell
一款交互式的拼写检查器,拼写检查一个包含简单的文本文件,可以这样使用 aspell:
aspell check textfile
split(把文件分割成碎片), csplit(基于上下文把文件分割成碎片),和 sdiff(并排合并文件差异)
八、格式化输出
nl – 添加行号
fold – 限制文件列宽
fmt – 一个简单的文本格式转换器
pr – 让文本为打印做好准备
printf – 格式化数据并打印出来
groff – 一个文件格式化系统
简单的格式化工具
nl - 添加行号:
nl distros.txt | head
如果nl同时处理多个文件,它会把他们当成一个单一的 文本流,处理完一个标记元素之后,nl 把它从文本流中删除。它支持一个叫“逻辑页面”的概念。
nl标记:
| 标记 | 含义 |
|---|---|
| ::: | 逻辑页页眉开始处 |
| :: | 逻辑页主体开始处 |
| : | 逻辑页页脚开始处 |
nl 选项:
| 选项 | 含义 |
|---|---|
| -b style | 把 body 按被要求方式数行,可以是以下方式:a = 数所有行t = 数非空行。这是默认设置。n = 无pregexp = 只数那些匹配了正则表达式的行 |
| -f style | 将 footer 按被要求设置数。默认是无 |
| -h style | 将 header 按被要求设置数。默认是 |
| -i number | 将页面增加量设置为数字。默认是一。 |
| -n format | 设置数数的格式,格式可以是:ln = 左偏,没有前导零。rn = 右偏,没有前导零。rz = 右偏,有前导零。 |
| -p | 不要在没一个逻辑页面的开始重设页面数。 |
| -s string | 在没一个行的末尾加字符作分割符号。默认是单个的 tab。 |
| -v number | 将每一个逻辑页面的第一行设置成数字。默认是一。 |
| -w width | 将行数的宽度设置,默认是六。 |
fold - 限制文件行宽:
# 设置行宽为12(字符),默认是80
echo "The quick brown fox jumped over the lazy dog." | fold -w 12
# 增加s选项考虑单词边界
echo "The quick brown fox jumped over the lazy dog." | fold -w 12 -s
fmt - 一个简单的文本格式器:填充和连接文本行,同时保留空白符和缩进
# 设置50 个字符宽,fmt 会保留第一行的缩进
fmt -w 50 fmt-info.txt | head
# 格式文件选中的部分,通过在开头使用一样的符号,注释行会合并
fmt -w 50 -p '# ' fmt-code.txt
pr – 格式化打印文本
pr 程序用来把文本分页,当打印文本的时候,经常希望用几个空行在输出的页面的顶部或底部添加空白。此外,这些空行能够用来插入到每个页面的页眉或页脚。
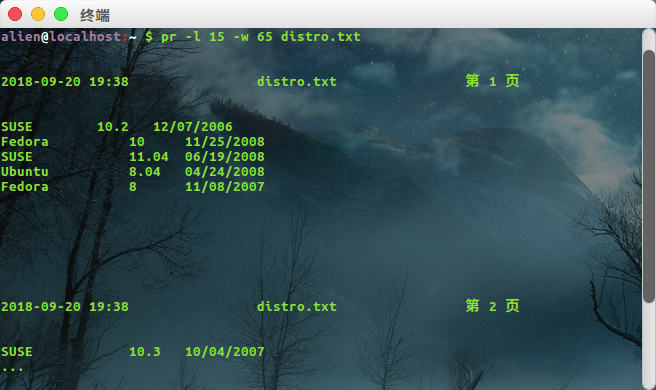
-l 选项(页长)和 -w 选项(页宽)定义了宽65列,长15行的一个“页面”。 pr 为 distros.txt 中的内容编订页码,用空行分开各页面,生成了包含文件修改时间、文件名、页码的默认页眉
printf:主要用在脚本中,用于格式化表格数据
printf “format” arguments
# 基本上和C语言一样
alien@localhost:~ $ printf "I formatted the string: %s\n" foo
I formatted the string: foo
printf转换规范组件:
| 组件 | 描述 |
|---|---|
| d | 将数字格式化为带符号的十进制整数 |
| f | 格式化并输出浮点数 |
| o | 将整数格式化为八进制数 |
| s | 将字符串格式化 |
| x | 将整数格式化为十六进制数,必要时使用小写a-f |
| X | 与 x 相同,但变为大写 |
| % | 打印 % 符号 (比如,指定 “%%”) |
alien@localhost:~ $ printf "%d, %f, %o, %s, %x, %X\n" 380 380 380 380 380 380
380, 380.000000, 574, 380, 17c, 17C
完整转换规范:
%[flags][width][.precision]conversion_specification
printf 转换可选规范组件
| 组件 | 描述 |
|---|---|
| flags | 有5种不同的标志:# – 使用“备用格式”输出。这取决于数据类型。对于o(八进制数)转换,输出以0为前缀.对于x和X(十六进制数)转换,输出分别以0x或0X为前缀。0–(零) 用零填充输出。这意味着该字段将填充前导零,比如“000380”。- – (破折号) 左对齐输出。默认情况下,printf右对齐输出。‘ ’ – (空格) 在正数前空一格。+ – (加号) 在正数前添加加号。默认情况下,printf 只在负数前添加符号。 |
| width | 指定最小字段宽度的数。 |
| .precision | 对于浮点数,指定小数点后的精度位数。对于字符串转换,指定要输出的字符数。 |
示例:
| 自变量 | 格式 | 结果 | 备注 |
|---|---|---|---|
| 380 | “%d” | 380 | 简单格式化整数。 |
| 380 | “%#x” | 0x17c | 使用“替代格式”标志将整数格式化为十六进制数。 |
| 380 | “%05d” | 00380 | 用前导零(padding)格式化整数,且最小字段宽度为五个字符。 |
| 380 | “%05.5f” | 380.00000 | 使用前导零和五位小数位精度格式化数字为浮点数。由于指定的最小字段宽度(5)小于格式化后数字的实际宽度,因此前导零这一命令实际上没有起到作用。 |
| 380 | “%010.5f” | 0380.00000 | 将最小字段宽度增加到10,前导零现在变得可见。 |
| 380 | “%+d” | +380 | 使用+标志标记正数。 |
| 380 | “%-d” | 380 | 使用-标志左对齐 |
| abcdefghijk | “%5s” | abcedfghijk | 用最小字段宽度格式化字符串。 |
| abcdefghijk | “%d” | abcde | 对字符串应用精度,它被从中截断。 |
文件格式化系统
groff:一套用GNU实现 troff 的程序。它还包括一个脚本,用来模仿 nroff 和其他 roff 家族。linux手册页由 groff 渲染,使用 mandoc 宏包。
# 默认以 PostScript格式输出,这里制定了ascii格式
zcat /usr/share/man/man1/ls.1.gz | groff -mandoc -ascii | head
# PostScript 输出的文件转换为PDF文件:
ps2pdf ~/Desktop/foo.ps ~/Desktop/ls.pdf
将 -t 选项添加到 groff 指示它用 tbl 预处理文本流。同样地,-T 选项用于输出到 ASCII ,而不是默认的输出介质 PostScript。