MapReduce架构
基于hadoop2.0架构是运行于YARN环境的。
参考:http://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/YARN.html
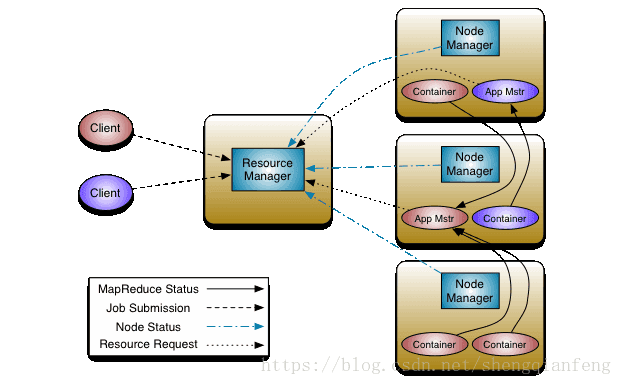
YARN环境-主从结构
整个yarn环境是MapReduce的运行环境
- 主节点Resource Manager
负责调度,是Resource Manager,给Node Manager的ApplicationMaster分配资源,分配好之后,ApplicationMaster就有一个Container,Container是资源的统称。
- 从节点Node manager
负责线程执行,是Node manager,即任务是执行在有数据的节点上,因为数据在DataNode上,所以Node manager和DataNode在同一个机器上。Node Manager是负责线程执行,或者任务执行,是通过application Master负责任务执行,它是属于Node Manager的一个组件,application Master执行的时候从Resource Manager申请资源。Node manager实时汇报自己的节点情况给Resource Manager。
- Container容器
NodeManager的组件之一,资源的组合或者资源容器。
- Application Master
NodeManager的组件之一,当Map Task开始执行的时候,NodeManager产生一个Application Master来负责线程任务的执行,执行前向Resource Manager去申请资源,Resource Manager是知道各个节点的资源情况的,因为NodeManager会实时汇报自己节点的资源情况,如果Node Manager上有空闲的资源,Node Manager就会生成一个Container资源容器,Application Master有了一个对应的资源容器之后就会开始执行,执行的时候Application Master和NodeManager之间还有一个执行状态的汇报,然后NodeManager向ResourceManager汇报。
具体程序的执行过程:
客户端把计算程序(一个jar包)提交给ResourceManager,ResourceManager把jar程序向各个NodeManager上复制。NodeManager会创建一个Application Master去执行map Task。
执行前去ResourceManager请求资源。
Tips:以上YARN环境,我们一般是不会改动的。我们只需要做的是计算程序的开发。
YARN-HA环境搭建
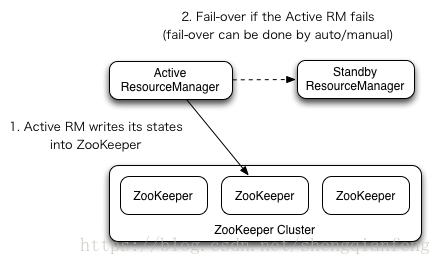
可以看到ResourceManager做了主备切换,通过zk选举出备。在主机宕机时进行故障转移。
ResourceManager上没有数据,直接切换即可。比NameNode的HA简单很多。
配置说明:
启用ResourceManager高可用
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>配置两个ResourceManager的服务编号,cluster1为NameServiceId,服务ID号
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>配置两个ResourceManager的Id号
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
配置rm1的主机
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>master1</value>
</property>
配置rm2的主机
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>master2</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>master1:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>master2:8088</value>
</property>
配置zk是哪些机器
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>zk1:2181,zk2:2181,zk3:2181</value>
</property>进去hadoop的配置文件目录:
#cd /root/hadoop-2.5.1/etc/hadoop
#vim yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>jeffSheng</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node4</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>node1:18088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>node4:18088</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node1:2181,node2:2181,node3:2181</value>
</property>
</configuration>
保存退出!
然后,打开/root/hadoop-2.5.1/etc/hadoop/mapred-site.xml:
|
此配置的作用是把MapReduce的执行环境设置在yarn环境中
可以看到在配置目录下只有一个模板文件,所以我们需要重命名一下
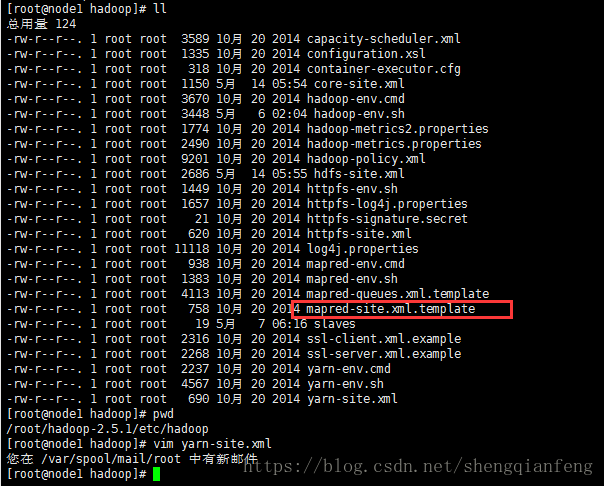
#mv mapred-site.xml.template mapred-site.xml
#vim mapred-site.xml将上边配置粘贴进去,保存退出

还需要配置一个
/root/hadoop-2.5.1/etc/hadoop/yarn-site.xml:
#vim yarn-site.xml在节点下加入以下属性保存退出:
|

配置完成,我们是在node1上配置,将配置文件配置到其他机器上node2,node3,node4。
注意:其实node2,node2,node4,就是datanode节点,也就是我们的NodeManager节点。他们一定是同一台机器上。
拷贝:
[root@node1 hadoop]# pwd
/root/hadoop-2.5.1/etc/hadoop
[root@node1 hadoop]# scp ./* root@node2:/root/hadoop-2.5.1/etc/hadoop/
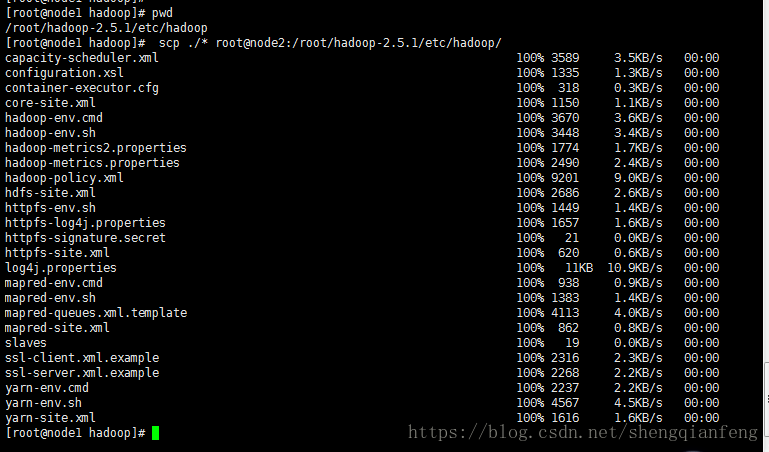
在node1上执行:
# start-yarn.sh
可以看到就启动了一个ResourceManager是node1,和三个nodeManager分别是node2,node3和node4
那么,那个备用的ResourceManager启动了没有,答案是没有,因为start-yarn.sh
不会帮助启动备用ResourceManager,需要我们自己手动启动。
由于我们是node4是备用ResourceManagerManager机器,我们在node4上输入:
# yarn-daemon.sh start resourcemanager
启动成功!
打开ResourceManager的监控页面:

点击左侧菜单Nodes,也可以看到三台NodeManager的节点信息
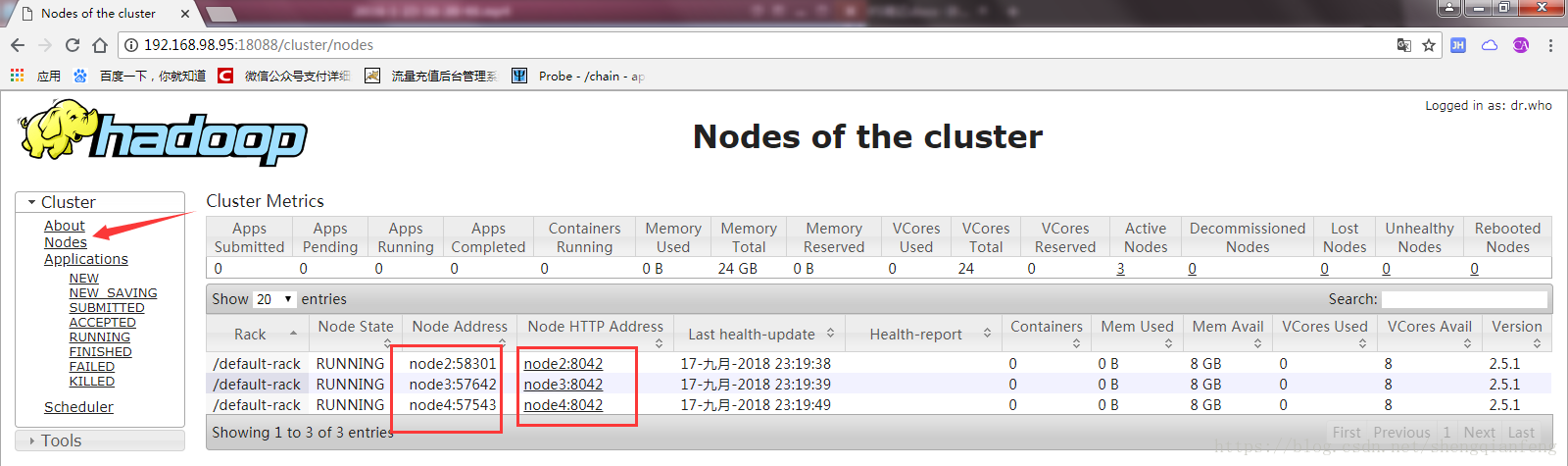
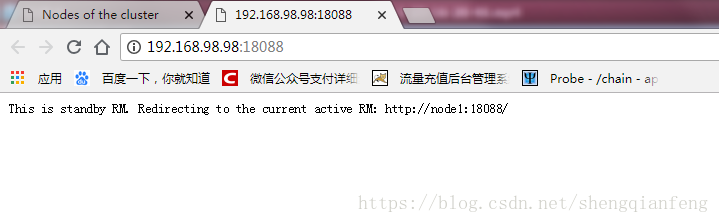
然后我们打开备用的ResourceManager,也就是node4,192.168.98.98这台机器:
却发现提示以下信息:This is standby RM. Redirecting to the current active RM: http://node1:18088/紧接着就重定向到了node1那个主的Resource机器
Tips:在windows上配置node1到node4的域名:打开C:\Windows\System32\drivers\etc,编辑hosts文件。
输入:
192.168.98.95 node1
192.168.98.96 node2
192.168.98.97 node3
192.168.98.98 node4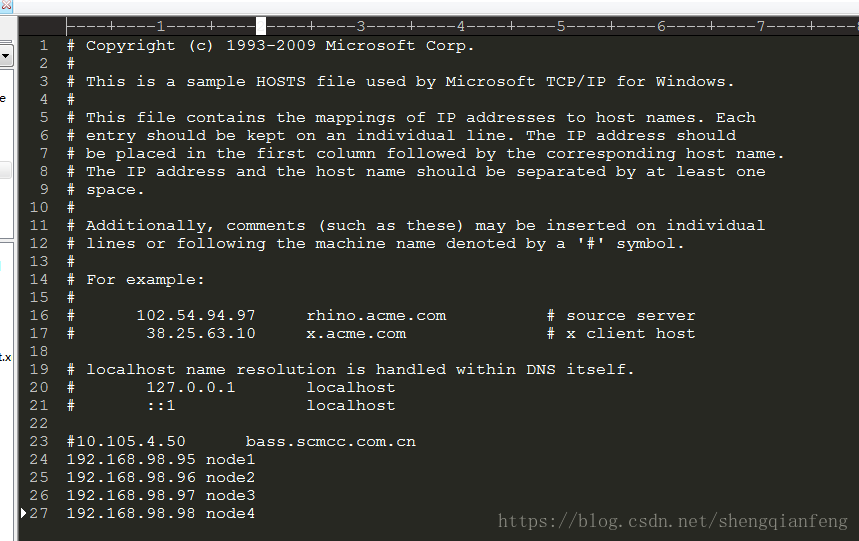
然后我们验证是否node1这个ResourceManager挂掉,node4的备用ResourceManager是否可以接管。
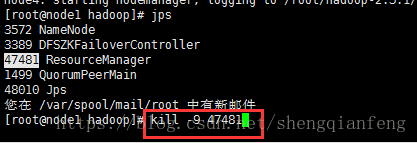
杀死了node1,发现node1的web界面不能访问了,node4可以!
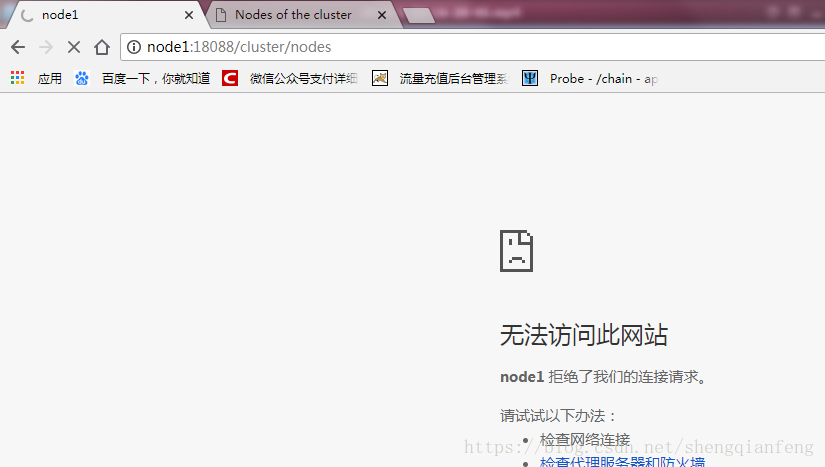
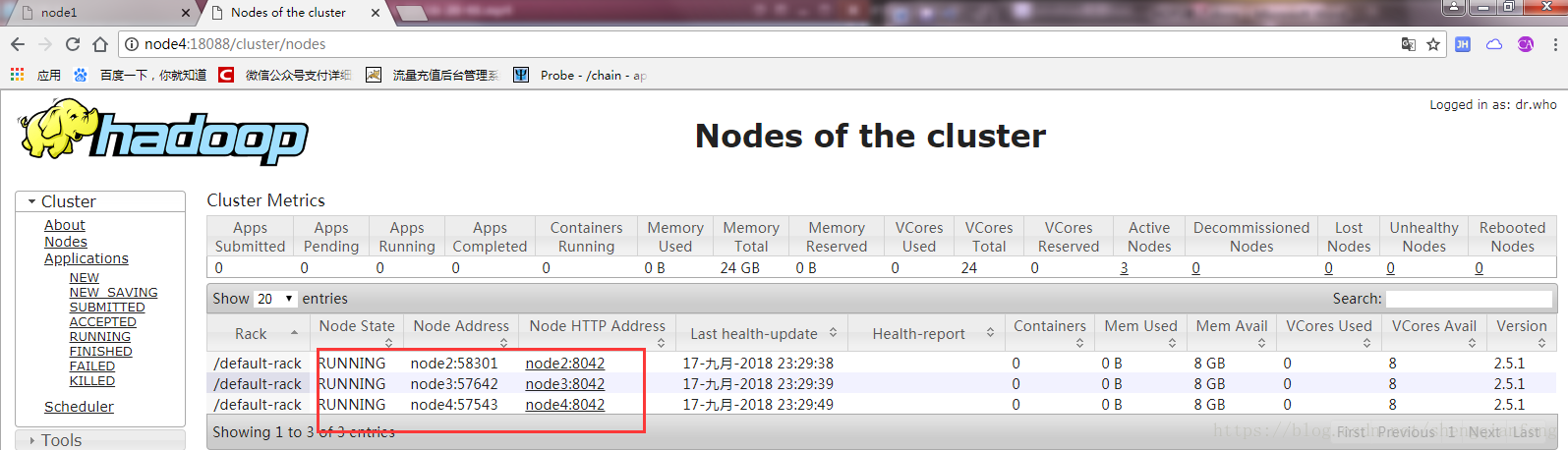
Node4接管node1的ResourceManager成功,需要注意的是接管可能需要几秒钟,其实就是NodeManager向ResourceManager汇报节点状态有一个超时时间,我们把node1杀死后,nodeManager还是在向Node1的resourceManager汇报,虽然是不成功的,等到超时时间到了还不成功,则认为node1这个ResourceManager挂掉了,将向node4这个ResourceManager汇报。