参考
https://blog.csdn.net/u014419512/article/details/27966957
https://www.jianshu.com/p/0f9578df7fbc
https://www.cnblogs.com/raphael5200/p/5229164.html
https://songlee24.github.io/2015/07/24/hbase-introduction/
http://www.cnblogs.com/gaopeng527/p/4967186.html
https://blog.csdn.net/hellowordlichao/article/details/27176151
http://www.rowkey.me/blog/2015/06/10/hbase-about/
https://blog.csdn.net/u010638969/article/details/53322643
https://blog.csdn.net/zhong_han_jun/article/details/45969375
Hbase简要介绍
HBase适合非结构化数据存储的数据库,是基于列的而不是基于行的模式
数据模型

rowkey:
决定一行数据的唯一标识;
按字典顺序排序;
最多只能存64K的字节数据;
columnfamily列族:
定义表时必须定义一个列族;
列族是表的一部分,而列不是;
访问控制、磁盘和内存的使用统计都是在列族层面进行的。实际应用中,列族上的控制权限能帮助我们管理不同类型的应用:我们允许一些应用可以添加新的基本数 据、一些应用可以读取基本数据并创建继承的列族、一些应用则只允许浏览数据;
column列:
列必须属于某个列族,不同列族之间可以有同名列;
name1:col1和name1:col2同属name1列族;
column在put时直接写就行;
Timestamp时间戳 :
用来区分版本,不同版本按时间倒序排列;
get最新的数据,scan可以看有定义版本个数的数据,版本由VERSIONS确定;
可自动赋值,也可由client赋值,但是要保证唯一性,以避免数据版本冲突;
cell单元格:
由行列交叉决定value,以时间戳为版本,tableName+RowKey+ColumnKey+Timestamp=>value
存储模型
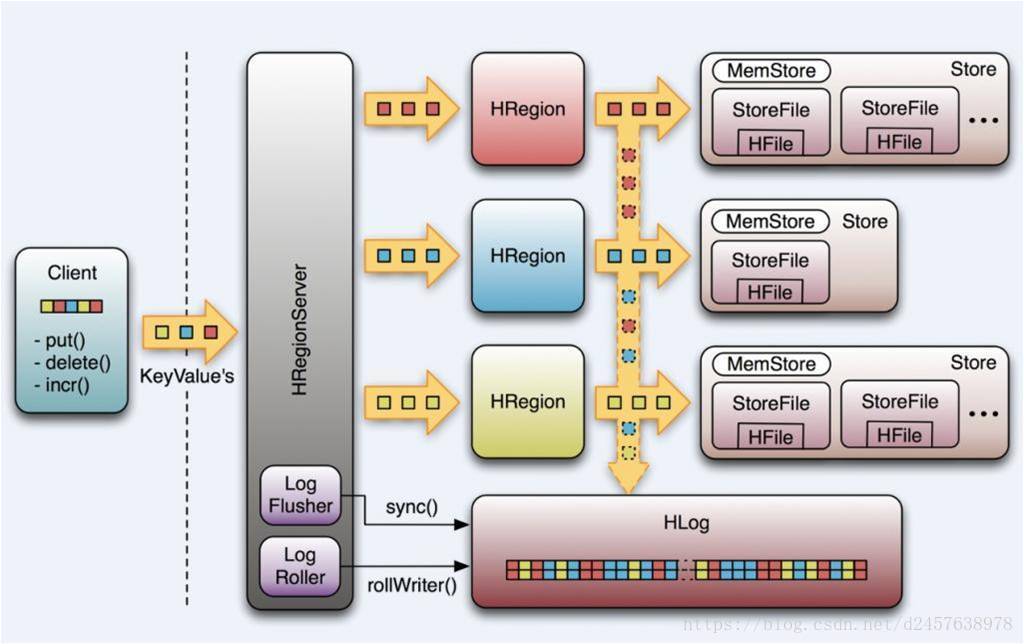
数据分片存储
在HBase中,一张表的数据会被分成几份,每一份数据为一个region;
每个region内存储的key是连续范围内的,不同region存储的key范围不重合;
这些region可能被存储在同一台机器上,也可能存储在不同的机器上;
HBase作为一个分布式数据库,对数据进行分片,可以提升吞吐量。
HLog:Write-Ahead-Log,写操作先写日志
当一台regionServer crash了,可以利用HLog来恢复内存中未持久化到硬盘中的数据;
需要注意的是,同一台server上的所有region共用一个HLog实例;
MemStore
写缓存,每个store拥有独立的写缓存;
在HBase中,所有的写操作全部写到内存中,当写缓存(MemStore)写满,再刷写(flush)到磁盘中,形成一个新的文件。
HFile
磁盘文件
在存储上,HBase完全依赖HDFS,磁盘操作是直接调用HDFS的API;
同一列族的数据会被写到同一文件,因为存储特性本来就是按照列族定义的;
HBase的数据在底层文件中时以KeyValue键值对的形式存储的;
HBase没有数据类型,HFile中存储的是字节,这些字节按字典序排列。
读缓存
同一server上所有region共用;
当HBase读取磁盘上某一条数据时,HBase会将整个HFile block读到cache中;
当client请求临近的数据时,HBase的响应会更快,HBase推荐将那些相似的,会被一起查找的数据存放在一起;
全表扫描时,为了不刷走读缓存中的热数据,千万记得关闭读缓存的功能;
HBase Compaction和Region Split
a. HBase Compaction
HBase数据写入的时候,总是先写入到写缓存(MemStore)中,当写缓存写满,则flush到磁盘形成一个新的磁盘文件。为了避免小文件越来越多,HBase会做compaction,合并HFile文件,减少每次查找数据的磁盘寻道时间。compaction分为major compact和minor compact两种:
Minor compact:将多个小文件简单合并成一个大文件
Major compact:将同一列族的所有文件合并成一个大文件,并且删除过期无效的数据和tombstone标记
b. Region Split
client不断向HBase写入数据,region管理的数据量不断膨胀。当一个region内存储的数据量到达阈值,则会触发HBase的region split操作,将老的region拆分成两个新的子region。拆分的原则是数据量对半分。为了避免region拆分导致的IO瞬时上升,region拆分并不会立刻将拆分重写所有的磁盘文件文件,而是为每个子region创建reference文件,这些文件指向了旧的磁盘文件中对应记录的起始和终止位置。等到子region的compact操作被触发,在重写文件的时候,HBase才会为每个子region生成独立的磁盘文件。
region定位
HBase如何找到某个row key (或者某个row key的range)所在的region?使用三层类似B+树的结构来保存region位置:
第一层:Zookeeper保存了-ROOT-表的位置。
第二层:-ROOT- 表保存了.META.表所有region的位置,通过-ROOT-表,可以访问.META.表的数据。
第三层:.META.是一个特殊的表,保存了HBase中所有数据表的region位置信息。
需要注意的是:
-ROOT-表永远不会被split,保证了只需要三次跳转,就能定位到任意region
META.表每行保存一个region的位置信息,row key采用表名+表的最后一行编码而成
为了加快访问,.META.表的全部region都保存在内存中
Client会将查询过的位置信息保存缓存起来,缓存不会主动失效
物理模型
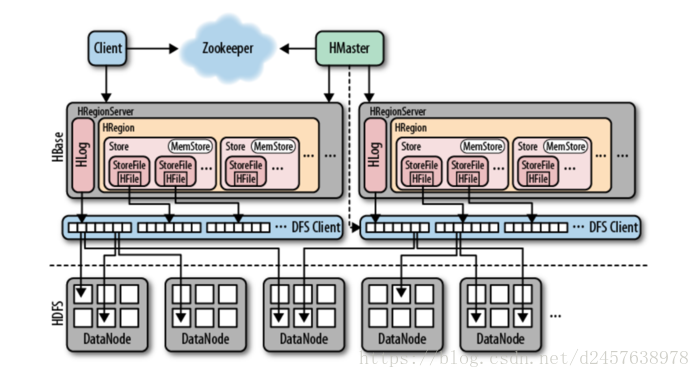
HBase的架构是一个典型的master-slave模型,HBase的master节点叫HMaster,slave节点就是RegionServer。
Client
HBase Client使用HBase的RPC机制与HMaster和HRegionServer进行通信,对于管理类操作,Client与HMaster进行RPC;
对于数据读写类操作,Client与HRegionServer进行RPC;
Zookeeper
Zookeeper Quorum中除了存储了-ROOT-表的地址和HMaster的地址;
HRegionServer也会把自己以Ephemeral方式注册到Zookeeper中,使得HMaster可以随时感知到各个HRegionServer的健康状态;
Zookeeper也避免了HMaster的单点问题;
HMaster
HMaster没有单点问题,HBase中可以启动多个HMaster,通过Zookeeper的Master Election机制保证总有一个Master运行,HMaster在功能上主要负责Table和Region的管理工作:
1. 管理用户对Table的增、删、改、查操作
2. 管理HRegionServer的负载均衡,调整Region分布
3. 在Region Split后,负责新Region的分配
4. 在HRegionServer停机后,负责失效HRegionServer 上的Regions迁移
5. HDFS的垃圾文件回收
注意:Client访问HBase上数据的过程并不需要HMaster参与(寻址访问Zookeeper和HRegionServer,数据读写访问HRegioneServer),HMaster仅仅维护者table和region的元数据信息,负载很低。
HRegionServer
主要负责响应用户I/O请求,向HDFS文件系统中读写数据,是HBase中最核心的模块。
HBase访问接口
- Native Java API,最常规和高效的访问方式,适合Hadoop MapReduce Job并行批处理HBase表数据
- HBase Shell,HBase的命令行工具,最简单的接口,适合HBase管理使用
- Thrift Gateway,利用Thrift序列化技术,支持C++,PHP,Python等多种语言,适合其他异构系统在线访问HBase表数据
- REST Gateway,支持REST 风格的Http API访问HBase, 解除了语言限制
- Pig,可以使用Pig Latin流式编程语言来操作HBase中的数据,和Hive类似,本质最终也是编译成MapReduce Job来处理HBase表数据,适合做数据统计
- Hive,当前Hive的Release版本尚没有加入对HBase的支持,但在下一个版本Hive 0.7.0中将会支持HBase,可以使用类似SQL语言来访问HBase。
Habse使用
使用场景
半结构化或非结构化数据
对于数据结构字段不够确定或杂乱无章很难按一个概念去进行抽取。当业务发展需要增加存储比如一个用户的email,phone,address信息时RDBMS需要停机维护,HBase支持动态增加.
记录稀疏表
Hbase只存储有值的cell,对于稀疏表来说就可以节省很多空间,但是,每个cell都存储了rowkey,columnFamily,qualifier,因此cf的名字不要太长
多版本数据
根据Row key和Column key定位到的Value可以有VERSIONS对应数量的版本值,因此对于需要存储变动历史记录的数据,用HBase就非常方便了。对于某一值,业务上一般只需要最新的值,但有时可能需要查询到历史值。
超大数据量
当数据量越来越大,会慢慢使用读写分离策略,通过一个Master专门负责写操作,多个Slave负责读操作,服务器成本倍增。然后再分库,把关联不大的数据分开部署,一些join查询不能用了,需要借助中间层。当一个表的记录越来越大,查询变得很慢,于是又得搞分表,比如按ID取模分成多个表以减少单个表的记录数。采用HBase只需要加机器即可,HBase会自动水平切分扩展,跟Hadoop的无缝集成保障了其数据可靠性(HDFS)和海量数据分析的高性能(MapReduce)
使用建议
一张HBase表存储的列的数量可以是无限的,但是列族的数量最好控制在3个以内
同一张表的column family数量不能超过2-3个。因为目前,flush和compaction操作是基于region进行的,当一个column family触发了MemStore flush操作,相邻的column family都会被刷写到磁盘,即使它们MemStore内的数据量还很小。因此,如果同一张表内column family的数量过多,flush和compaction将会带来更多不必要的I/O负载(当然这个问题可以通过,将flush和compaction改成列族之间互不影响来解决)。通常情况下,定义表的时候尽量使用单列族,除非列与列的查询是相对独立的,再考虑使用多个列族,比如client并不会同时请求两个列族的数据。
当同一张内有多个列族时,注意一些列族间的数据量是否一致,假如列族A和列族B的数据量相差悬殊,列族A的大数据量会导致表数据被分片到很多个机器上,此时再对列族B的数据做扫描,效率会很低。行键设计
避免使用时序或者单调(递增/递减)行键,否则会导致连续到来的数据会被分配到统一region中。
尽量最小化行键和列族的大小
每个cell都存储了rowkey,columnFamily,qualifier,因此cf的名字不要太长,避免hbase的索引过大,加重系统存储的负担
版本的数量
避免设置过大,版本保留过多。
设置TTL
避免后期无用数据过大
简单使用语句
Hbase shell
hbase shell
create 'user:example','name1' //create 'namespace:basename','columnFamilyname'
put 'user:example','row1','name1','row1name1'
put 'user:example','row1','name1:col1','row1name1col1'
get 'user:example','row1','name1'
get 'user:example','row1','name1:col1'
help
status //服务器状态
version //Hbase版本信息
whoami //查看连接的用户
disable 'user:example' //表失效
enable 'user:example' //失效表有效
//alter表修改,需在执行前先disable,执行后enable
alter 'user:example','name2' //新增列族
alter 'user:example',{NAME=>'name2',METHOD=>'delete'}
describe 'user:example' //查看表结构
desc 'user:example'
list //列举该namespace下所有的表
drop 'user:example'
count 'user:example'
scan 'user:example' //全表扫描
delete 'user:example','row1','name1:col1' //删除指定rowkey的指定列族的列名数据
delete 'user:example','row1','name1' //删除rowkey的制定列族数据
delete 'user:example','row1'
alter 'user:example',{NAME=>'name1',TTL=>'15768000'} //设置TTLHBase API
//HbaseUtil
public class HbaseUtil {
private static Connection connection = null;
private HbaseUtil(){
}
public static synchronized Connection getConnection(){
if (null == connection) {
try {
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.property.clientPort", "2181");
conf.set("hbase.zookeeper.quorum", "2120.mzhen.cn,2122.mzhen.cn,2121.mzhen.cn");
connection = ConnectionFactory.createConnection(conf);
} catch (IOException e) {
e.printStackTrace();
}
}
return connection;
}
}
//OperationDao
public class OperationDao {
private Connection connection;
private TableName tablename;
public OperationDao(String tablename){
this.tablename = TableName.valueOf(tablename);
connection = HbaseUtil.getConnection();
}
public void createTable(String columnFamily) throws Exception{
Admin admin = connection.getAdmin();
if(admin.tableExists(tablename)){
System.out.println("table exists!");
}else {
HTableDescriptor desc = new HTableDescriptor(tablename);
desc.addFamily(new HColumnDescriptor(columnFamily));
admin.createTable(desc);
System.out.println("create table success!");
}
}
public void putData(String rowKey, String columnfamily, String column, String cell) throws Exception {
Table table = connection.getTable(tablename);
Put p = new Put(Bytes.toBytes(rowKey));
p.addColumn(Bytes.toBytes(columnfamily), Bytes.toBytes(column), Bytes.toBytes(cell));
table.put(p);
table.close();
}
public String getData(String rowKey, String columnfamily, String column) throws Exception{
Table table = connection.getTable(tablename);
Get g = new Get(Bytes.toBytes(rowKey));
Result res = table.get(g);
Cell cell = res.getColumnLatestCell(Bytes.toBytes(columnfamily), Bytes.toBytes(column));
if(cell == null){
return null;
}
return Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength());
}
}
//常用语句
System.out.println("-----------cell[]进行扫描-----");
for(Result rs : scanner){
for(Cell cell:rs.rawCells()){
String row = Bytes.toString(cell.getRowArray(), cell.getRowOffset(), cell.getRowLength());
String family= Bytes.toString(cell.getFamilyArray(),cell.getFamilyOffset(),cell.getFamilyLength());
String column= Bytes.toString(cell.getQualifierArray(),cell.getQualifierOffset(),cell.getQualifierLength());
String value = Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength());
System.out.println(row+"\n---"+family+":"+column+"\n"+value);
}
}