本篇文章的来源背景是这样的:我需要在数据库中取数据然后写到缓存中,因为业务原因表示设计成的月份表,即一个月的数据都在这张表中,所以数据量很大,我需要在凌晨的时候,用户量少的时候将数据写到缓存中,又因为线上有个发邮件的定时任务在跑,如果我写入缓存时间太长就可能会影响邮件的发送,所以我必须使用一个快速的方法来实现这个任务。
模拟数据
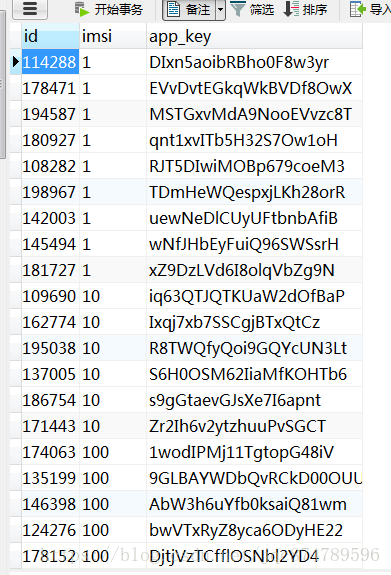
为了模拟效果,我通过存储过程和函数造了2W条左右的数据,部分数据如图所示,写入缓存时,我们以imsi+"_"+app_key作为缓存的key,以imsi+"_"+app_key+"_value"作为缓存的value值。
直接写入的方式
因为是个定时任务,所以方法上用了springboot支持的注解的方式来定时执行任务。因为本篇文章的重点是缓存而并非定时任务,所以关于定时任务的相关信息需要大家自己百度学习,有关定时任务的文章,我后面也会写。
@Scheduled(cron = "0 8 14 * * ?")
public void redisTest() {
Jedis jedis = RedisUtils.getJedis();
LOGGER.info("========程序开始执行========");
Long startTime = System.currentTimeMillis();
Integer dataCount = dataInsertRedis.getCount(); //查询数据总数
List<CatPayMonthProps> data = dataInsertRedis.getData(); //查询全部数据
Long selectEndTime = System.currentTimeMillis();
Long selectTime = (selectEndTime - startTime) / 1000; //查询总耗时,单位:秒
LOGGER.info("查询完毕,总计[{}]条数据,耗时:[{}]秒",dataCount,selectTime);
LOGGER.info("等待数据写入缓存...");
Long writeStartTime = System.currentTimeMillis();
for (CatPayMonthProps catPayMonthProps : data) {
String imsi = catPayMonthProps.getImsi();
String appKey = catPayMonthProps.getAppKey();
String redisKey = imsi + "_" + appKey;
String redisValue = imsi + "_" + appKey + "_value";
jedis.setex(redisKey, 10000, redisValue); //参数分别为缓存的Key,缓存的有效期,缓存的Value
}
Long writeEndTime = System.currentTimeMillis();
Long writeTime = writeEndTime - writeStartTime;
LOGGER.info("数据写入缓存完毕,写入耗时:[{}]毫秒",writeTime);
LOGGER.info("========程序执行结束=======");
}日志输出:

我们发现2W条数据写入缓存时间用了45秒多的时间,如果数据为100W,大约要37.5分钟的时间!
使用Pipeline管道方式写入
前面这种方法显然是不可取的,写入时间太长。现在使用pipeline管道技术写入,代码如下:
@Scheduled(cron = "0 33 14 * * ?")
public void redisTest() {
Jedis jedis = RedisUtils.getJedis();
LOGGER.info("========程序开始执行========");
Long startTime = System.currentTimeMillis();
Integer dataCount = dataInsertRedis.getCount(); //查询数据总数
List<CatPayMonthProps> data = dataInsertRedis.getData(); //查询全部数据
Long selectEndTime = System.currentTimeMillis();
Long selectTime = (selectEndTime - startTime) / 1000; //查询总耗时,单位:秒
LOGGER.info("查询完毕,总计[{}]条数据,耗时:[{}]秒",dataCount,selectTime);
LOGGER.info("等待数据写入缓存...");
Long writeStartTime = System.currentTimeMillis();
Pipeline pipeline = jedis.pipelined();
for (CatPayMonthProps catPayMonthProps : data) {
String imsi = catPayMonthProps.getImsi();
String appKey = catPayMonthProps.getAppKey();
String redisKey = imsi + "_" + appKey;
String redisValue = imsi + "_" + appKey + "_value";
pipeline.setex(redisKey, 10000, redisValue); //参数分别为缓存的Key,缓存的有效期,缓存的Value
}
Long writeEndTime = System.currentTimeMillis();
Long writeTime = writeEndTime - writeStartTime;
LOGGER.info("数据写入缓存完毕,写入耗时:[{}]毫秒",writeTime);
LOGGER.info("========程序执行结束=======");
}日志输出:

观察输出结果发现2W的数据写入缓存只用了300毫秒,仅仅只有0.3秒的时间,如果100W条数据写入缓存,也只需要15秒的时间,比之前的37.5分钟快了150倍!!!
PS:java程序遍历数据的时间是非常快的,不用怀疑这种一条一条遍历数据的速度,这种遍历的耗时几乎可以忽略不计。
那么使用管道与不使用管道的区别是什么呢?简单解释一下,我画了两张图片,大家对比一下。
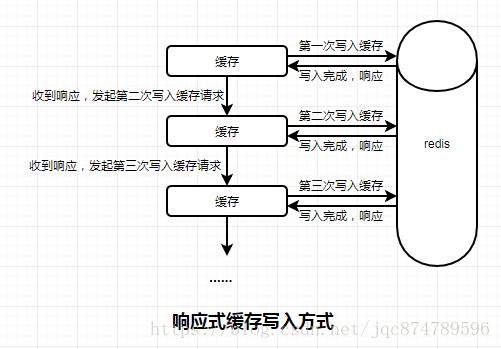
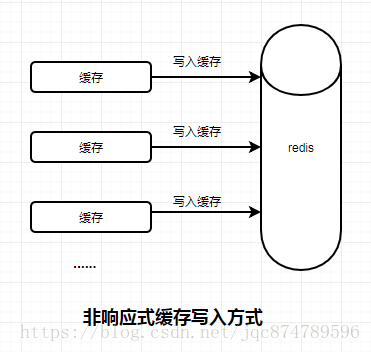
观察图可以得知,通常的写入方式为响应式方式,即每写入一次缓存都需要等待redis相应信息是否写入成功,如果写入成功后会返回相应信息,这时候才会发起下次写入缓存的请求,而对于非响应式的方式,是不需要等待响应信息的,这就节省了很多的等待时间。想要两者更多的区别,还需要大家自己查阅资料,我这里只是简单的表述。