IA-32中的传送指令
IA-32常用指令类型
(1)传送指令 – 通用数据传送指令 MOV:一般传送,包括movb、movw和movl等 MOVS:符号扩展传送,如movsbw、movswl等 MOVZ:零扩展传送,如movzwl、movzbl等 XCHG:数据交换 PUSH/POP:入栈/出栈,如pushl,pushw,popl,popw等 –地址传送指令 LEA:加载有效地址,如leal (%edx,%eax), %eax”的功能为 R[eax]←R[edx]+R[eax],执行前,若R[edx]=i, R[eax]=j,则指令执行后,R[eax]=i+j – 输入输出指令 IN和OUT:I/O端口与寄存器之间的交换 – 标志传送指令 PUSHF、POPF:将EFLAG压栈,或将栈顶内容送EFLAG
“入栈”(pushw %ax)

“出栈” (popw %ax)

程序由指令序列组成

功能:R[esp]← R[esp]-4,M[R[esp]] ←R[ebp]的实现原理
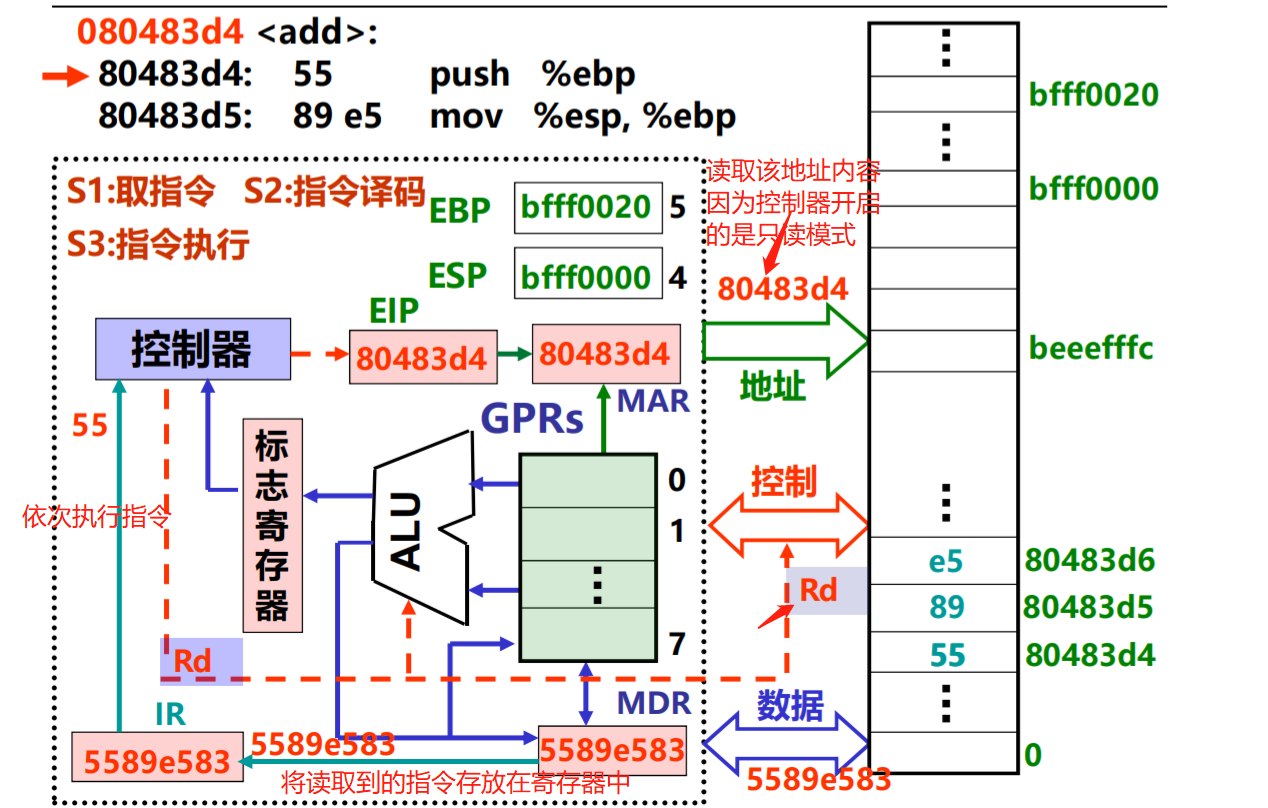
执行下一个指令
扫描二维码关注公众号,回复:
3259833 查看本文章


IA-32中的定点算术运算指令
(2)定点算术运算指令 – 加 / 减运算(影响标志、不区分无/带符号) ADD:加,包括addb、addw、addl等 SUB:减,包括subb、subw、subl等 – 增1 / 减1运算(影响除CF以外的标志、不区分无/带符号) INC:加,包括incb、incw、incl等 DEC:减,包括decb、decw、decl等 – 取负运算(影响标志、若对0取负,则结果为0且CF清0,否则CF置1) NEG:取负,包括negb、negw、negl等 – 比较运算(做减法得到标志、不区分无/带符号) CMP:比较,包括cmpb、cmpw、cmpl等 – 乘 / 除运算(不影响标志、区分无/带符号) MUL / IMUL:无符号乘 / 带符号乘 DIV/ IDIV:带无符号除 / 带符号除
算数运算

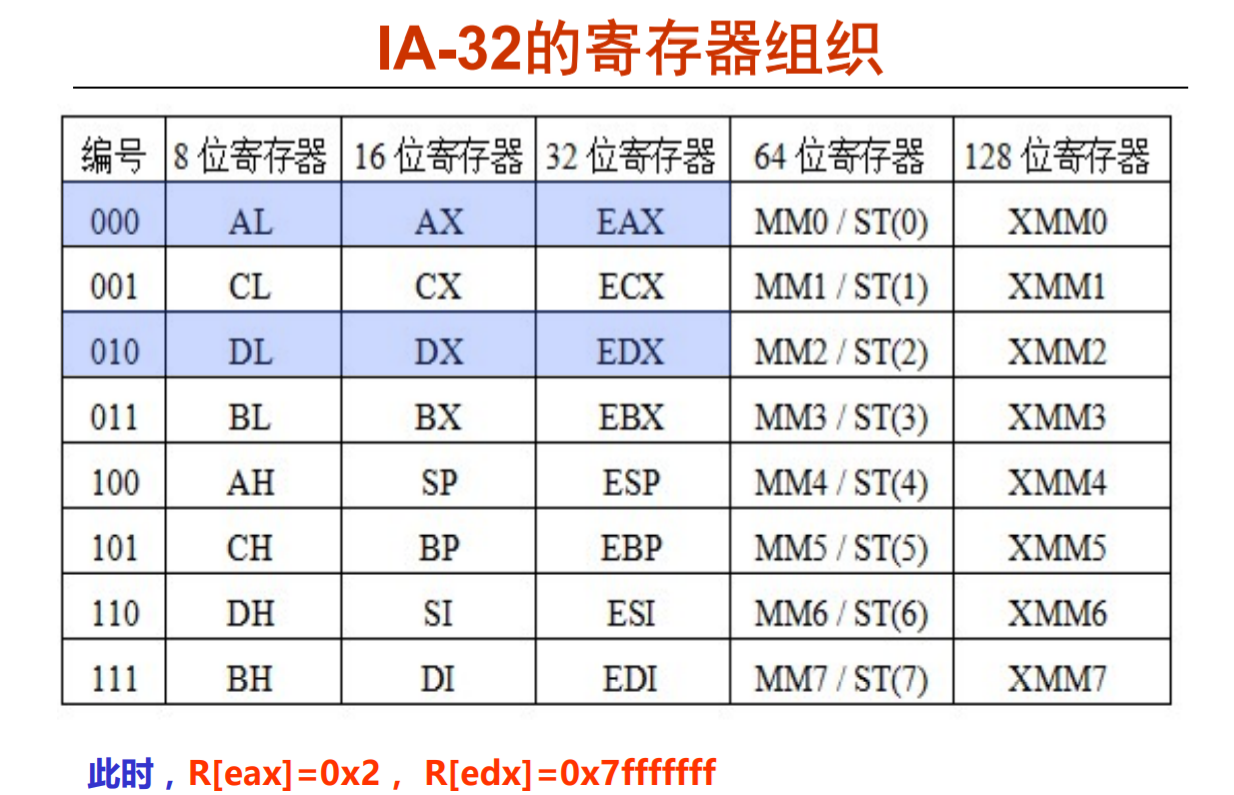
IA-32的寄存器组织
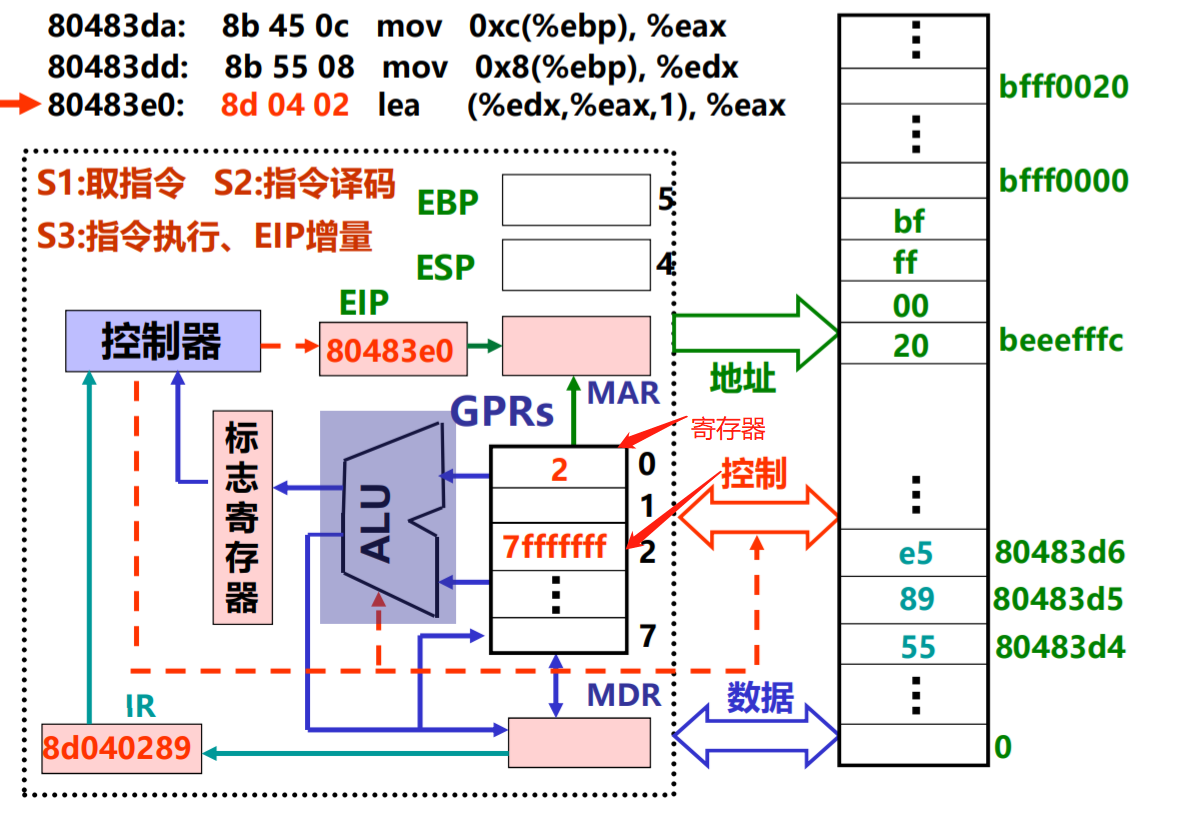
功能:R[eax]← R[edx]+R[eax]*1
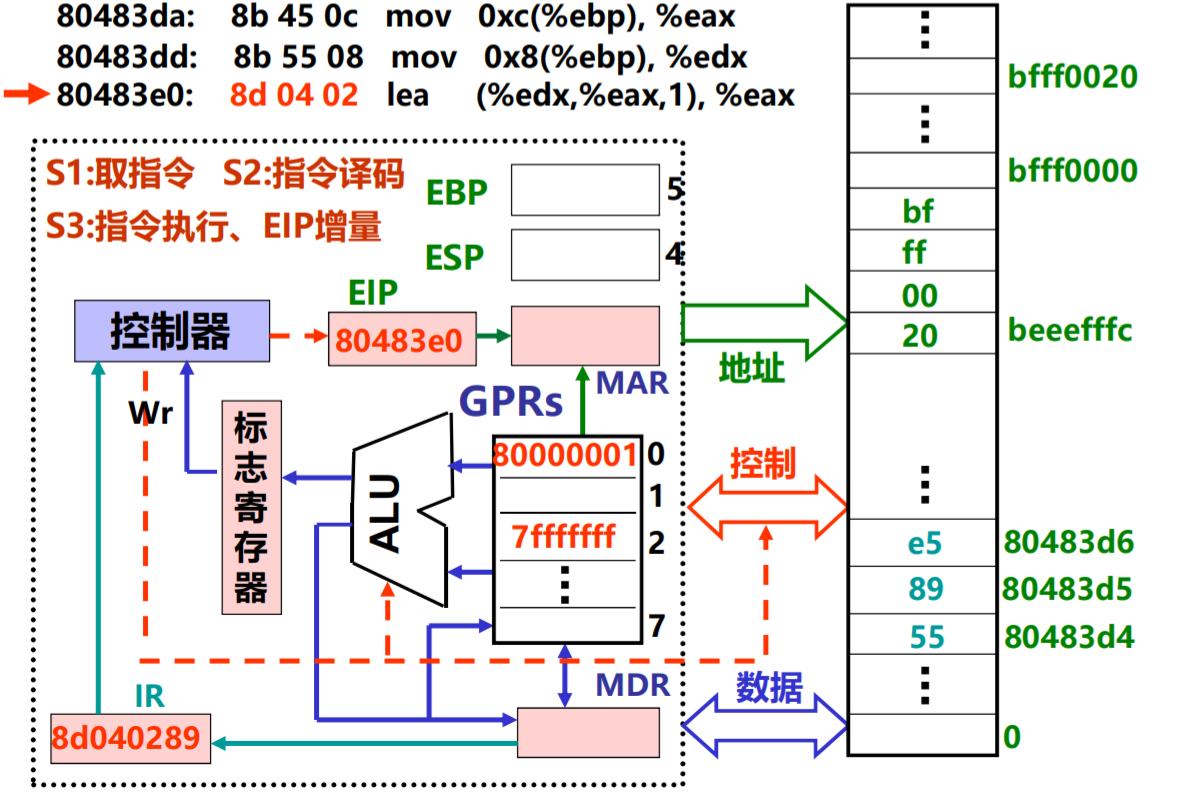
功能:R[eax]← R[edx]+R[eax]*1 (执行后)
定点加法指令举例
假设 R[ax]=FFFAH,R[bx]=FFF0H,则执行以下指令后 “addw %bx, %ax” AX、BX中的内容各是什么?标志CF、OF、ZF、SF各是什么?要求分别 将操作数作为无符号数和带符号整数解释并验证指令执行结果。 解:功能:R[ax]←R[ax]+R[bx],指令执行后的结果如下 R[ax]=FFFAH+FFF0H=FFEAH ,BX中内容不变 CF=1,OF=0,ZF=0,SF=1 若是无符号整数运算,则CF=1说明结果溢出 验证:FFFA的真值为65535-5=65530,FFF0的真值为65515 FFEA的真值为65535-21=65514≠65530+65515,即溢出 若是带符号整数运算,则OF=0说明结果没有溢出 验证:FFFA的真值为-6,FFF0的真值为-16 FFEA的真值为-22=-6+(-16),结果正确,无溢出
定点乘法指令举例
假设R[eax]=000000B4H,R[ebx]=00000011H, M[000000F8H]=000000A0H,请问: (2) 执行指令“imull $-16, (%eax,%ebx,4), %eax”后哪些寄存器和存储单元发生 了变化?乘积的机器数和真值各是多少? 解:“imull -16, (%eax,%ebx,4),%eax” 功能为 R[eax]←(-16)×M[R[eax]+R[ebx]×4] ,执行结果如下 R[eax]+R[ebx]×4=000000B4H+00000011H<<2=000000F8H R[eax]=(-16)×M[000000F8H] =(-16)× 000000A0H(带符号整数乘) =16 × (-000000A0H) =FFFFFF60H<<4 =FFFFF600H EAX中的真值为-2560
x87浮点处理指令
IA-32的浮点处理架构
IA-32的浮点处理架构有两种 (1) x87FPU指令集(gcc默认) (2) SSE指令集(x86-64架构所用) • IA-32中处理的浮点数有三种类型 – float类型:32位 IEEE 754 单精度格式 – double类型:64位 IEEE 754 双精度格式 – long double类型:80位双精度扩展格式 1位符号位s、15位阶码e(偏置常数为16 383)、1位显式 首位有效位(explicit leading significant bit)j 和 63位 尾数f。它与IEEE 754单精度和双精度浮点格式的一个重要的 区别是:它没有隐藏位,有效位数共64位。
x87 FPU指令
x87 FPU 特指与x86处理器配套的浮点协处理器架构 – 浮点寄存器采用栈结构 • 深度为8,宽度为80位,即8个80位寄存器 • 名称为 ST(0) ~ ST(7),栈顶为ST(0),编号分别为 0~7 – 所有浮点运算都按80位扩展精度进行 – 浮点数在浮点寄存器和内存之间传送 • float、double、long double型变量在内存分别用IEEE 754单精度、双精度和扩展精 度表示,分别占32位(4B)、64位(8B)和96位(12B,其中高16位无意义) • float、double、long double类型变量在浮点寄存器中都用80位扩展精度表示 • 从浮点寄存器到内存:80位扩展精度格式转换为32位或64位 • 从内存到浮点寄存器: 32位或64位格式转换为80位扩展精度格式
数据传送类 (1) 装入 (转换为80位扩展精度) FLD:将数据从存储单元装入浮点寄存器栈顶 ST(0) FILD:将数据从int型转换为浮点格式后,装入浮点寄存器栈顶 (2) 存储(转换为IEEE 754单精度或双精度) FSTx:x为s/l时,将栈顶ST(0)转换为单/双精度格式,然后存入存储单元 FSTPx:弹出栈顶元素,并完成与FSTx相同的功能 FISTx:将栈顶数据从int型转换为浮点格式后,存入存储单元 FISTP:弹出栈顶元素,并完成与FISTx相同的功能 带P结尾指令表示操作数会出栈,也即ST(1)将变成ST(0)
数据传送类 (3) 交换 FXCH:交换栈顶和次栈顶两元素 (4) 常数装载到栈顶 FLD1 :装入常数1.0 FLDZ :装入常数0.0 FLDPI :装入常数pi (=3.1415926...) FLDL2E :装入常数log(2)e FLDL2T :装入常数log(2)10 FLDLG2 :装入常数log(10)2 FLDLN2 :装入常数Log(e)2
算术运算类 (3) 乘法 FMUL/FMULP: 相乘/相乘后弹出栈 FIMUL:按int型转换后相乘 (4) 除法 FDIV/FDIVP : 相除/相除后弹出栈 FIDIV:按int型转换后相除 FDIVR/FDIVRP:调换次序相除/相减后弹出栈 FIDIVR:按int型转换并调换次序相除
IA-32浮点操作举例




从这个例子可以看出
– 编译器的设计和硬件结构紧密相关。
– 对于编译器设计者来说,只有真正了解底层硬件结构和真正
理解指令集体系结构,才能够翻译出没有错误的目标代码,
并为程序员完全屏蔽掉硬件实现的细节,方便应用程序员开
发出可靠的程序。
– 对于应用程序开发者来说,也只有真正了解底层硬件的结构
,才有能力编制出高效的程序,能够快速定位出错的地方,
并对程序的行为作出正确的判断。