1. 背景
偶然发现查看线上日志-Xloggc:******/gc.log下面的日志,发现线上机器存在Full GC,查找其他服务发现都会有这个问题,
基于我们系统很多垃圾回收机制都是ParalllelGC,即吞吐量优先GC方式,GC线上在处理任务时会造成系统stop the wrold暂停,而且GC
时间相对CMS等收集器而已要更长,虽然这些Full GC暂时无明显停顿,但是出于优化原则进行了一轮排查。下面是对几台线上机器的比对。

比对发现线上服务最后一次启动时间与FullGC出现时间相对吻合。
2. 问题定位
通过观察比对发现这些Full GC有几个比较明显的特点
- 每台机器都有几个Full GC ,这几个Full GC的时间间隔并不长
- 线上xmx是2g,由新生代占比3/8的比例看,Full GC产生时PSYongGen ParOldGen并无达到造成Full GC的大小
- 将日志第一次触发Full GC时间和该服务最后一次启动时间对比,发现几乎吻合
- Full GC类型属于Metadata GC Threshold(jdk 1.8才会打印类型)
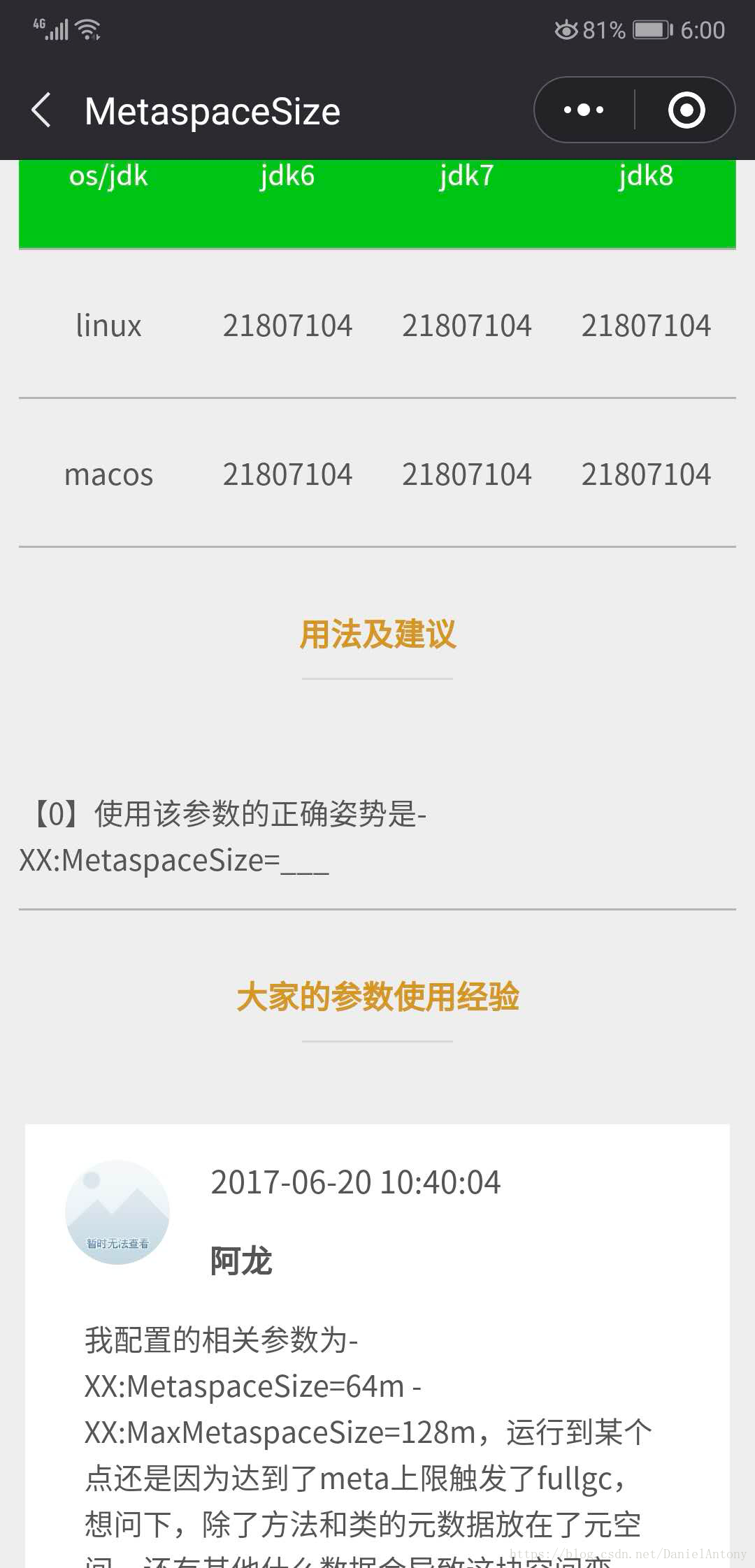
有次四点,我们可以总结到本次Full GC是由服务时启动导致的,由于jdk1.8开始jvm用metaspace替代Perm永久区,我们知道永久区是用来存储已被虚拟机加载的类信息,
常量和静态变量,然后跑去寒泉子大牛的JVMPocket看到,jdk从1.6到1.8的默认大小都是MetaSpaceSize=21807104字节(20.8M左右),继续观察我们会发现这几次
Full GC前后,Metaspace的使用变化是从20844k→20844k,也就是并没有发生变化,看起来好像Metaspace并没有被回收,其实这是JVM的一个BUG,alijdk等自用产品
会将这个问题进行了修复,能看到前后是有变化的,所以如果大家在排查Metaspace的问题时候,希望不要被这个信息骗到
3. mat分析内存使用情况
gc前

gc后

我们发现gc前后内存使用情况并无明显变化,再查看了一下Leak Suspect发现使用内存较多的类是java.lang.ref.Finalizer,此类在finally做流关闭会大量存在,
由于我们用的是dubbo做远程过程调用,故也属于正常行为。

4. 大结局
到这里,我们看到还是MetaSpaceSize设置太小的问题导致,查看参考配置发现很多公司会将MetaSpaceSize设置为128M,在dev重现了此问题后,设置成
128M,重新看gc日志并未发现有Full GC问题,到此,我们就成功解决了线上一个Full GC问题。