目录
永远记住计算机存储的是二进制码流,不是文字
涉及编码的几个函数的理解
unicode 与 print函数
write使用示例
常见的错误1:write使用错误
常见的错误2:encode错误
常见的错误2: utf-8 与 utf-8 无BOM
常见的错误4: 对unicode进行decode错误
常见的错误5:对函数‘==’和replace的理解
永远记住计算机存储的是二进制码流,不是文字
python 中的中文乱码经常地很让人头疼。
其实所谓编码,就是一种数字(编码数字)与文字的一一映射关系。之所以会有不同的编码,就是这种映射关系不唯一。计算机里存储的是编码的数字,形式上就是二进制流,由于这种映射关系不唯一,所以一个文本经不同的编码总会得到不同的二进制流。
涉及编码的几个函数的理解
python中经常会涉及编码的几个函数和我个人对他们的理解(理解没经过查证,只是单纯的通过实现验证,请小心参考):
| 函数 | 功能 | 编码错误产生可能 |
|---|---|---|
| s.encode(‘utf-8’) | 如果s是str类型,将二进制码流B1按系统默认编码对应出相应的文字,再将相应的文字按utf-8获新的二进制码流B2; 如果s是unicode类型,将二进制流B1按unicode编码对应出相应的文字,再将相应的文字按utf-8获新的二进制码流B2; 该函数返回书类型为str |
s为str类型时,B1不是使用系统编码获得的 |
| s.decode(‘utf-8’) | 将s的二进制码流B1按utf-8获取相应的文字,相应的文字按unicode获取新的二进制码流B2; 该函数返回类型是unicode |
B1不是使用utf-8编码获得的 |
| setdefaultencoding(‘utf-8’) | 设置系统默认编码为utf-8,默认为ascii | |
| write(s) | 如果s类型是str,那么直接写入文件,如果s是unicode,将s对应的二进制码流按unicode获得相应文字,再将相应文字按系统默认编码获取新的二进制码流,将s对应的二进制码流改写为这个新的二进制码流 | |
| print(s) | 将s的二进制码流按unicode获取相应的文字,输出到屏幕上(在我的windows8.1系统上print好像还能正常解析gbk编码) |
| 函数 | 功能 | 编码错误产生可能 |
|---|---|---|
| encode(‘utf-8’) | 将系统默认编码或unicode编码对应的二进制流B1转化为utf-8编码的二进制流B2 | B1不是使用系统编码获得的 |
| decode(‘utf-8’) | 将使用utf-8的二进制流B1转化为unicode编码的二进制流B2 | B1不是使用utf-8编码获得的 |
注:ANSI格式不是ascii编码,而是gbk编码(查看notepad++)
这几个函数使用不慎,就会出现中文乱码。
unicode 与 print函数
python 中除了str,还有unicode类型表示字符串
对于print函数,如果是字符流,他会输出对应的Unicode文字;如果是一个与list,那么将输出这个list里字符的编码二进制流(实质是十六进制数)
#coding=utf-8
# 下面三种方式获得结果以一样的(输出的文字和二进制码流)
s = unicode('中国', 'utf-8')
print s, [s] # 中国 [u'\u4e2d\u56fd']
s = u'中国' # 这个可能是解释器根据文件本身coding=utf-8的编码进行了隐式的准换吧
print s, [s] # 中国 [u'\u4e2d\u56fd']
s = '中国'.decode('utf-8')
print s, [s] # 中国 [u'\u4e2d\u56fd']write使用示例
#coding=utf-8
# write
def test1():
filep = open('test.txt','wb')
s = '你是谁' # 这里s的二进制流对应的是该文件的编码,因为指定了事utf-8编码,所以这里对应的是utf-8对应的流
filep.write(s) # s的类型是str,所以写入文件的的是utf-8对应的二进制流
filep.close()
words = open('test.txt','rb').read()
print words == s # True。True。 因为读文件读的是二进制流没有发生改变
print s # 乱码。print会按unicode编码解析这个utf-8对应的二进制流
print s.decode('utf-8') # 无乱码。先试用decode把utf-8的二进制流转化为 unicode的二进制流,再利用print按unicode编码解析这个流得到最终对应的文字。该程序生成的test.txt使用notepad++打开,格式选为以utf-8编码,就能看到正确的内容

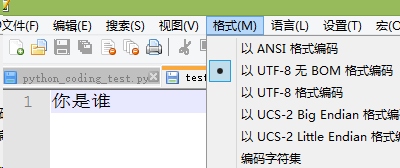
常见的错误1:write使用错误
# coding=utf-8
def test2():
filep = open('test.txt','wb')
s = u'你是谁' # s存储的是unicode对应的二进制流
filep.write(s) # Error 解释报错。write接收到unicode流,先将unicode流转化为系统编码(默认为ascii)流,ascii无法编码中文,报错
filep.close()报错如下
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-2: ordinal not in range(128)报错分析:
s的二进制流是unicode对'你是谁'的编码,write接收到unicode类型后,
会将二进制流按unicode的编码对应出相应的文字('你是谁'),
然后将相应的文字('你是谁')按系统默认编码(如果不设置,就是ascii)对应出相应的二进制流编码,
由于ascii无法对汉字进行编码所以出错了。解决方案:
修改系统默认编码方式
# coding=utf-8
def test2_change():
import sys
reload(sys)
sys.setdefaultencoding( "utf-8" ) # 临时修改系统默编码方式,程序结束后失效
filep = open('test.txt','wb')
s = u'你是谁' # s存储的是unicode对应的二进制流
filep.write(s) # write接收到unicode流,先将unicode流转化为系统编码(前面已修改为utf-8)流,再写入文件
filep.close()常见的错误2:encode错误
#coding=utf-8
# 首先字符串'中文'在这个utf-8的文件里先得到utf-8流,
# encode('gbk') 先将utf-8流按系统默认编码(ascii)对应出文字,再将文字对应到utf-8对应的二进制流
# 但是ascii无法编码中文,所以在encode的第一步就会报错。即使能编码中文,对utf-8流使用非utf-8对应文字,也会是乱码。
def test3():
s = '中文'.encode('gbk') # Error。正确修改为,修改系统默认编码和文件编码一致
def test3_change():
import sys
reload(sys)
sys.setdefaultencoding('utf-8') # 临时修改系统默编码方式,程序结束后失效
s = '中文'.encode('gbk') # utf-8流按系统默认方式utf-8对应出文字,将文字按gbk对应出gbk二进制码流
print s.decode('gbk') # 将gbk二进制流按gbk对应出文字,再将文字按unicode对应出unicode二进制码流
# print再将unicode码流按unicode对应出文字打印出来
print s # 这个没有乱码,说明在我这台机器上,print可以正常打印gbk流
print [s], [s.decode('gbk')]常见的错误2: utf-8 与 utf-8 无BOM
# utf-8无BOM 和 utf-8
# 有些编辑器在创建UTF8编码文件时会在头部添加一个不可见字符(这个例子里是0xfeff)
# 这个被称作BOM(Byte Order Mark)的不可见字符,是Unicode用来标识内部编码的排列方式的,
# 在UTF-16、UTF-32编码里它是必需的,而在UTF-8里是可选的
# 如果utf-8文件是有BOM的那么应该从index=1开始读取,而不是index=0
def test4():
import sys
reload(sys)
sys.setdefaultencoding( "utf-8" ) # 临时修改系统默编码方式,程序结束后失效
w = open("hongloumeng.txt",'rb').read();
w = w.decode("utf-8") # 注意变成unicode后不能使用replace,所以选择时机decode
print w[1:7] == u" 上卷 第一" # 从第1个开始的正文
#print w[0:7] # w.worlds[0]打印会报错 【unicodeError】
print [w[0]] 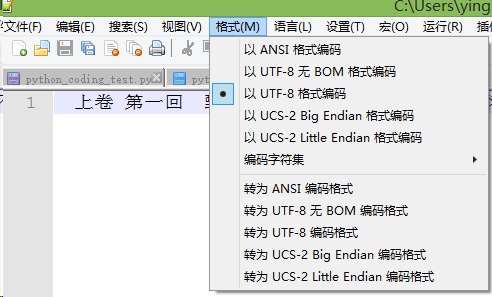

常见的错误4: 对unicode进行decode错误
u'您好'.decode('utf-8')
'你好'.decode('utf-8').decode('utf-8')以上两个都回报下面的错误:
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-12: ordinal not in range(128)如果我的理解decode(‘utf-8’)是将二进制码流按utf-8对应出文字,所以将unicode二进制码流按utf-8对应文字时,自然会出错,但是应该报utf-8 codec的错误才对,这里却报了acsii codec的错误,看来我的理解虽然能解决遇到的问题,但还是有问题的。
常见的错误5:对函数‘==’和replace的理解
字符串比较s1==s2,
如果两者类型都是str,那么相等的条件是两者编码一致并且对应文字相同;
如果一个是str,另一个是unicode,那么会先将str按系统默认编码decode为unicode,再比较,相当于str.decode(defaultencoding)==unicode
#coding=utf-8
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
s0 = "我是中国人,我热爱学习" # utf-8流
s1 = s0.decode('utf-8') # unicode流
s2 = s1.encode('gbk') # gbk流
print [s0,s1, s2]
print s0 == s2 # False. str1==str2 要求两者对应的文字相同并且编码一致
print s0 == s1 # True. str==unicode 等价为 str.decode(defaultencoding)==unicode,因为默认编码设置为utf-8,所以True
print s1 == s2 # False而且有Warning.. str==unicode 同上,但是默认编码是utf-8,而这个流是gbk流,所以转换为unicode失败replace里字符匹配上了就是利用上面的标准s1==s2
所以如果是unicode.replace(str,..)或str.replace(unicode,…)系统默认编码设置会很重要;
如果是str.replace(str..)的话要保证两个str的bain吗要保持一致。
#coding=utf-8
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
# str.replace(str,...)
s = s0.replace('我', '我们').decode('utf-8') # 一定可以 (文件编码和s0都符合utf-8)
print s, type(s), [s]
# unicode.replace(unicode,...)
s = s0.decode('utf-8').replace(u'我', u'我们') # 一定可以 (文件编码和s0都符合utf-8)
print s, type(s), [s]
# unicode.replace(str,..)
s = s0.decode('utf-8').replace('我', '我们') # (文件编码和s0都符合utf-8,还要保证系统默认编码是utf-8),否则就会失效甚至报错
print s, type(s), [s]
# str.replace(unicode,...)
s = s0.replace(u'我', u'我们').decode('utf-8') # 同上一个
print s, type(s), [s]测试源代码可参考:http://download.csdn.net/detail/yinglang19941010/9590911