业务背景
最近一个开发维护的公众号管理系统用户表(user_info)数据已经达到15,000k了,而此时有一个业务场景需要将公众号的用户信息重新同步一次,且后台原有过针对单个公众号的用户同步,但是已经非常难以使用,因为同步时间太长了,以前的同步用户方式大概流程如下:
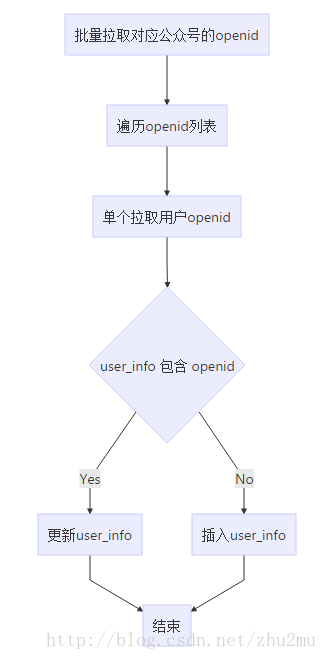
通过上面的流程可以看出来更新用户流程过程非常耗时,每个用户更新下来应该需要300ms左右,因为这涉及到每次更新一个用户都需要调用一次微信接口,然后单个更新用户信息又分两步a.查询用户是否存在、b.不存在则更新。其中user_info表已经针对openid建立了普通索引,查询起来比较快。那么一个30W粉丝的公众号数据更新可能就需要14hour左右,这个时间是无法接受的。那么应该如何来进行优化呢?很明显可以这下面两点开始:
1. 拉取微信用户信息使用批量接口,批量接口一次可以拉取100个用户信息;
2. 插入用户数据使用批量插入、更新接口每次可以插入100条(这个数量如何确定的?其实只要数据库插入的时间和拉取用户数据差不多就可以了,没必要一次插入几千、几万条,因为接口数据如何没有准备好的话该过程也是在等待)。
上面两点可以优化性能,其中第一点没什么好说的调用公众平台的批量接口,第二代批量插入数据库,而且要求:用户存在时更新用户信息、用户不存在时插入用户信息。
可以用下面语句满足上面业务:
insert into tableName(id,name1,name12) values (a,b,c),(d,c,e) on DUPLICATE KEY UPDATE name1=values(name1),name2=values(name2)Mybaits写法
<insert id="batchInsert">
insert into tableName(id,name1,name12) values
<foreach collection="List" item="item" index="index" separator=",">
(#{item.id,jdbcType=VARCHAR},
#{item.name1,jdbcType=VARCHAR},
#{item.name2,jdbcType=VARCHAR})
</foreach>
ON DUPLICATE KEY UPDATE name1=values(name1),name2=values(name2)
</insert>
上面满足业务需要的insert sql语句建立在数据有唯一索引的情况下,例如要限制插入用户信息不重复那么需要针对openid来创建唯一索引才能满足需求。这个时候问题就来了,如何修改千万级别的数据表索引呢?而且该数据表还是一个业务活跃表。
服务器性能
8核16G 300G SSD 云主机 性能还过的去其他网卡什么的不用考虑太多同机房应用服务器这些不是性能瓶颈,主要是唯一索引过程需要排序要消耗不少CPU。
建索引前准备
这种千万级别的==活跃==数据表肯定需要找专家一起评估一番才敢开始动手,于是第一步找有经验的DBA同事一起协商下根据当前数据服务器性能、数据量、业务请求等多方面评估修改索引的风险和影响。根据历史经验DBA给除了几分钟肯定不行的评估,让我直接建。然后就是业务方面的评估,索引期间对业务的影响,因为索引过程中会导致数据服务器性能变慢,因此我们决定找一个用户不太活跃的时间段来开始。那么接下来就是准备步骤了。整理大致步骤如下:
- 找出user_info表 openid重复的数据;
- 重复数据只保留一条;
- 删除openid普通索引;
- 创建openid唯一索引。
开始执行
由于历史遗留问题,实际操作步骤更为复杂:
1. create table user_info_duplicate like user_info; //创建临时表用来备份重复数据
2. insert into user_info_duplicate select * from user_info group by openid having count(*) > 1;
3. SELECT openid from user_info_duplicate; //导出重复的openid到文件(用子查询的方式删除会特别慢)
4. 提供删除openid的脚本文件提执行sql
5. 删除openid为null的数据
DELETE from user_info where openid is null;
DELETE from user_info_duplicate where openid is null;
- drop INDEX
openid_indexon user_info; //删除旧索引; - ALTER TABLE user_info ADD UNIQUE openid_u_index(openid); // 创建唯一索引;
8、insert ignore into user_info select * from user_info_duplicate; //把数据还原
总结
其中有几个步骤需要特别说明下:
- 第一是重复数据部分之后要先创建唯一索引再还原数据否则怕在业务过程中被删除的用户更新了用户表导致基于openid的唯一索引创建失败;
- 另外需要关注的是第6和第7步应该更换一下位置,否则会导致业务非常缓慢,因为在很多业务依赖索引openid_index来执行时,突然索引被清除了那么千万基本的表肯定会有大量的查询超时,导致业务异常,我们就是按照这个悲剧式的步骤执行的,果然最后悲剧了;
- 最后异步还原数据的时候要用ignore关键字避免插入重复的数据,因为在创建索引过程中由于业务在执行可能会有与备份表相同的用户进入业务系统更新用户表(进入公众号进行操作时会自动更新用户信息到数据库)
最终数据库索引创建过程花了大概 36min。性能不错的虚拟机花费了这么长时间,这个过程中业务一直超时,还好执行时间段用户比较少,影响不是特别大。真是一个不小的教训。
Query OK, 0 rows affected (36 min 13.23 sec)
Records: 0 Duplicates: 0 Warnings: 0最后更新系统代码为批量更新,300,000K 用户更新花费了大概 1hour,更新速度提升了10+倍。基本上面是每100调用户花费1s更新。