版权声明:原创文章要转载的话麻烦请dalao注明出处呢٩(๑❛ᴗ❛๑)۶ https://blog.csdn.net/MIKASA3/article/details/80066001
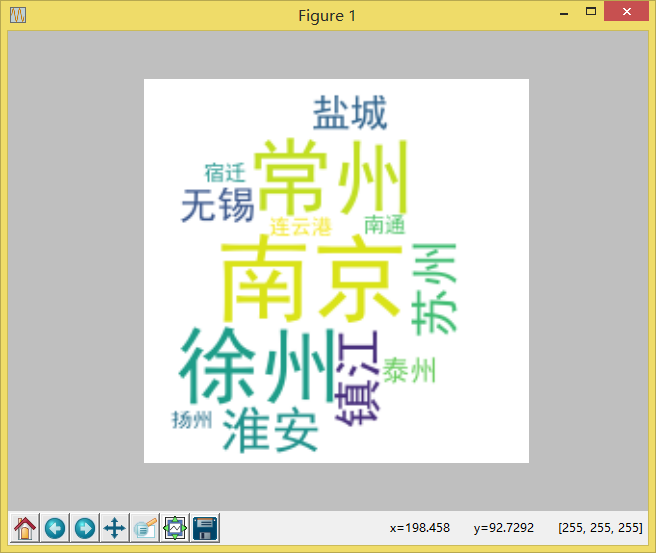
词云图是根据词出现的频率生成词云,词的字体大小表现了其频率大小。
〇、碎碎念
用wc.generate(text)直接生成词频的方法使用很多,所以不再赘述。
但是对于根据generate_from_frequencies()给定词频如何画词云图的资料找了很久,下面只讲这种方法。
generate_from_frequencies适用于我已知词及其对应的词频是多少,不需要自动生成的情况下。
官方文档说generate_from_frequencies函数的参数是array of tuple,但是我试了很久都不行,最后发现居然应该是dict 字典形式!
即形如:{ word1: fre1, word2: fre2, word3: fre3,......, wordn: fren }
注意词云wordcloud的中文显示,需要特殊处理,在网上看了不少是说加字体路径之类的方法我试了都不行,最后只好采用改变编码的形式才解决好Σ(っ°Д°;)っ:
name[i] = name[i].decode('gb2312')( • ̀ω•́ )✧还有,示例词云的轮廓背景图由back.jpg给出,如下图:

一、数据文件准备
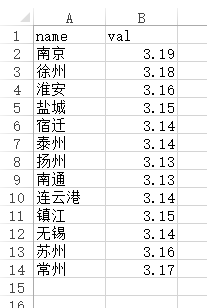
1、price.csv
name,val
南京,3.19
徐州 ,3.18
淮安,3.16
盐城,3.15
宿迁,3.14
泰州,3.14
扬州,3.13
南通,3.13
连云港 ,3.14
镇江,3.15
无锡,3.14
苏州,3.16
常州,3.17
第一列是城市名,第二列是词频数值,
csv文件本质上就是以逗号(,)分隔开的txt文件,所以用excel打开形式为:
二、导入模块包
可参考Windows下安装Python、matplotlib包 及相关
https://blog.csdn.net/mikasa3/article/details/78942650
1、numpy
2、pandas
3、wordcloud
4、matplotlib
三、完整代码
如下:
import random
import numpy as np
import pandas as pd
from pyecharts import WordCloud
import matplotlib.pyplot as plt
from PIL import Image,ImageSequence
from wordcloud import WordCloud,ImageColorGenerator
def DrawWordcloud(read_name):
image = Image.open('back.jpg')#作为背景形状的图
graph = np.array(image)
#参数分别是指定字体、背景颜色、最大的词的大小、使用给定图作为背景形状
wc = WordCloud(font_path = 'C:\\windows\\Fonts\\simhei.ttf', background_color = 'White', max_words = 50, mask = graph)
fp = pd.read_csv(read_name)#读取词频文件
name = list(fp.name)#词
value = fp.val#词的频率
for i in range(len(name)):
name[i] = str(name[i])
#注意因为要显示中文,所以需要转码
name[i] = name[i].decode('gb2312')
dic = dict(zip(name, value))#词频以字典形式存储
wc.generate_from_frequencies(dic)#根据给定词频生成词云
image_color = ImageColorGenerator(graph)
plt.imshow(wc)
plt.axis("off")#不显示坐标轴
plt.show()
wc.to_file('Wordcloud.png')#保存的图片命名为Wordcloud.png
if __name__=='__main__':
DrawWordcloud("Price.csv")
四、运行结果
1、词云图