faster rcnn没有将结果去重整合到网络结构中去,需要在第二阶段最后手工进行去重
过程:
- 调用im_detect()得到单张图片在网络中的打分值scores和boxes。其数据格式分别为(300,21)和(300,84)。其中三百为检测到的目标数目也就是前一阶段proposal推荐送入分类器的目标个数。21和84就是我们所说的cls和4*cls。也就是说,对于300个目标每一个目标在21个类上(20cls+1bg)都有一个评分值被输出共同构成一个300行21列的数组。而这个21个分类又分别对应了一个box的位置最终构成一个300行84列的数组我们可以输出这两个数组的维度以及第0行数据以便于直观理解
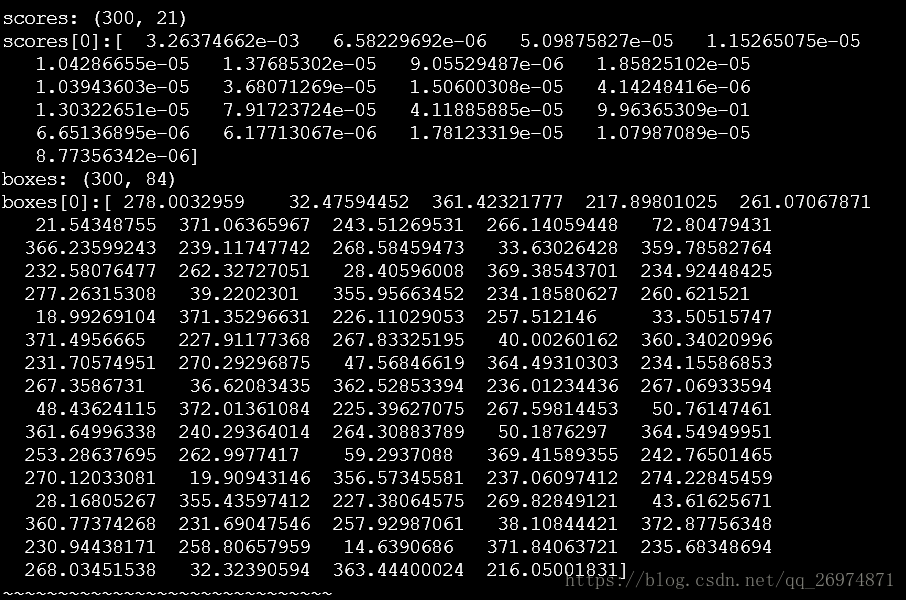
可以看到在scores中对于第0行也就是第一个推荐目标有21个各不相同的评分值。而更值得注意的是boxes[0]对于这个21 个类别共计84个坐标值也是各不相同的。其实这是很好理解的,因为我们在网络中就是分别用21个神经元和84个神经元去进行分类和boxes的计算的。
2. 在一个循环中,针对每一个分类(除去背景类),抽取对应的分类打分情况和boxes坐标得到cls_scores和cls_boxes两个数组


这样我们就可以分别得到这300个proposals在每一个单一类别的分值和box位置。
3.接下来把这两个数组整合到一起得到一个300*5的dets数组,使得每个分类分值后面跟上其box位置,再使用NMS_THRESH计算nms去重复边框。然后根据CONF_THRESH去除低分值

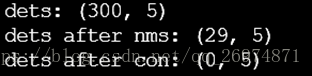
可以看到原本的dets包含所有300个proposals在这个类上的分值和box位置经过NMS去重筛选过后只会剩下了29个独立的proposals。进一步的符合CON_THRESH条件的则一个也没有。
总结:
经过以上步骤我们看到,不算背景类的情况下,原本在RPN阶段的一个proposal应是由5(4+1)个数值来描述即box位置信息和是否为前景的打分值。也就是一个proposal只需要一个框体上对应的分值来描述即可。而到了第二阶段。对于每一个porposal在不同的分类上都进行了预测和边框回归,此时一个proposal就需要有20个框体以及每个框体所对应的分值来描述。也就是第二个阶段在一张图片上一共可以产生300*20=6000个互不重合的框体以及对应的分类分数。
接下来进行去重工作时再是根据各个类别的不同分别进行NMS和分数筛选。最后就可以得到我们想要检测结果。由于是不同类别分别画框分别打分,也就避免了我们所当心的一个框体上出现多个分类结果分值的情况。